Введение
Неконтролируемая маркировка данных — важнейший аспект машинного обучения, целью которого является присвоение меток точкам данных без предварительно помеченных обучающих данных.
В этой статье мы исследуем мир неконтролируемой маркировки данных и ее значение в области машинного обучения. Мы углубляемся в различные темы, такие как алгоритмы кластеризации, методы уменьшения размерности, активное обучение, метрики оценки, проблемы, приложения, гибридные подходы, этика и будущие тенденции исследований.
Обзор неконтролируемой маркировки данных

Неконтролируемая маркировка данных играет жизненно важную роль в различных задачах машинного обучения, включая кластеризацию, обнаружение аномалий и исследовательский анализ данных.
В этом разделе мы стремимся предоставить всестороннее введение в этот важный аспект машинного обучения.
Контролируемое VS неконтролируемое обучение
В то время как обучение с учителем в значительной степени зависит от помеченных данных для обучения моделей, обучение без учителя работает в отсутствие таких меток, что делает его сложным, но очень ценным подходом.
Используя неконтролируемые методы маркировки данных, исследователи и практики могут обнаруживать скрытые шаблоны и структуры в наборах данных без необходимости в заранее определенных метках.
Ключевое различие между контролируемым и неконтролируемым обучением заключается в доступности помеченных данных. В то время как контролируемое обучение опирается на уже существующий набор помеченных примеров для обучения моделей, неконтролируемое обучение работает в немаркированных или частично помеченных условиях.
Алгоритмы кластеризации для неконтролируемой маркировки данных

Алгоритмы кластеризации являются важными инструментами для неконтролируемой маркировки данных, позволяя группировать точки данных в отдельные категории на основе их сходства. Несколько популярных методов кластеризации, таких как k-means, иерархическая кластеризация, DBSCAN и смешанные модели Гаусса, широко используются в различных областях.
К-означает
Кластеризация K-средних — это широко используемый алгоритм, который разбивает точки данных на k кластеров, сводя к минимуму внутрикластерную дисперсию.
Иерархическая кластеризация
Иерархическая кластеризация, с другой стороны, строит иерархию кластеров путем многократного слияния или разделения кластеров на основе их сходства.
DBSCAN (пространственная кластеризация приложений с шумом на основе плотности)
DBSCAN (Пространственная кластеризация приложений с шумом на основе плотности) определяет плотные области точек данных и отделяет шум от кластеров.
Модели гауссовской смеси
Смешанные модели Гаусса предполагают, что точки данных генерируются из смеси распределений Гаусса, и оценивают параметры для назначения точек различным кластерам.
Каждый из этих алгоритмов обладает уникальными преимуществами и ограничениями:
- k-means эффективен в вычислительном отношении, но требует априорного знания количества кластеров.
- Иерархическая кластеризация обеспечивает гибкую иерархию кластеров, но может быть чувствительна к шуму и выбросам.
- DBSCAN эффективен при обнаружении кластеров произвольной формы, но требует тщательной настройки параметров.
- Смешанные модели Гаусса могут охватывать сложные распределения данных, но могут иметь проблемы с многомерными данными.
Понимание характеристик этих алгоритмов кластеризации имеет решающее значение для выбора подходящего метода на основе данных и проблемы, что в конечном итоге облегчает неконтролируемую маркировку данных.
Методы уменьшения размерности для неконтролируемой маркировки данных

Методы уменьшения размерности играют жизненно важную роль в решении проблем, связанных с многомерными наборами данных, обеспечивая эффективную визуализацию и анализ. Анализ основных компонентов (PCA), t-SNE и автоэнкодеры являются одними из известных методов, используемых для этой цели.
СПС
PCA — это метод линейного преобразования, который идентифицирует основные компоненты данных, фиксируя максимальную дисперсию в низкоразмерных представлениях. Это позволяет сжато представлять данные, сохраняя при этом их базовую структуру.
т-СНЭ
t-SNE фокусируется на сохранении локальных сходств путем сопоставления точек данных высокой размерности с пространством меньшей размерности. Он подчеркивает сохранение попарных расстояний, позволяя визуализировать кластеры и закономерности.
Автоэнкодеры
Автоэнкодеры — это тип нейронной сети, способный изучать компактные представления данных, кодируя их в пространство с меньшим размером и впоследствии реконструируя их.
→ Используя внутреннюю структуру данных, эти методы уменьшения размерности прокладывают путь для эффективной неконтролируемой маркировки. Они облегчают выявление шаблонов, кластеров и взаимосвязей, которые могут быть скрыты в многомерном пространстве, позволяя исследователям и аналитикам получать ценную информацию и принимать обоснованные решения.
Активное обучение для неконтролируемой маркировки данных

Активное обучение — это мощный подход, обладающий огромным потенциалом для повышения как эффективности, так и качества неконтролируемой маркировки данных. В области неконтролируемой маркировки данных, где отсутствие маркированных данных представляет собой проблему, активное обучение предлагает решение путем интеллектуального выбора экземпляров для ручного аннотирования.
Благодаря использованию алгоритмов активного обучения этот процесс становится более эффективным и действенным, что позволяет повысить точность маркировки при минимальных человеческих усилиях.
Ключевая идея активного обучения состоит в том, чтобы итеративно выбирать наиболее информативные экземпляры из немаркированного набора данных и запрашивать их метки у экспертов или аннотаторов.
Эти экземпляры тщательно выбираются на основе их потенциала для уменьшения неопределенности или повышения общей осведомленности о модели.
Этот активный выбор помогает расставить приоритеты при написании аннотаций, сосредоточив внимание на экземплярах, которые, как ожидается, окажут наибольшее влияние на процесс обучения.
Стратегически выбирая экземпляры для маркировки, алгоритмы активного обучения могут направить модель к лучшему обобщению и повысить ее производительность на невидимых данных.
Эта повторяющаяся петля обратной связи между моделью и аннотаторами позволяет модели учиться на размеченных данных, сводя к минимуму необходимость значительных усилий по маркировке.
По мере того, как модель становится более осведомленной, она может принимать более обоснованные решения о том, какие экземпляры должны быть приоритетными для маркировки, что делает процесс маркировки все более эффективным.
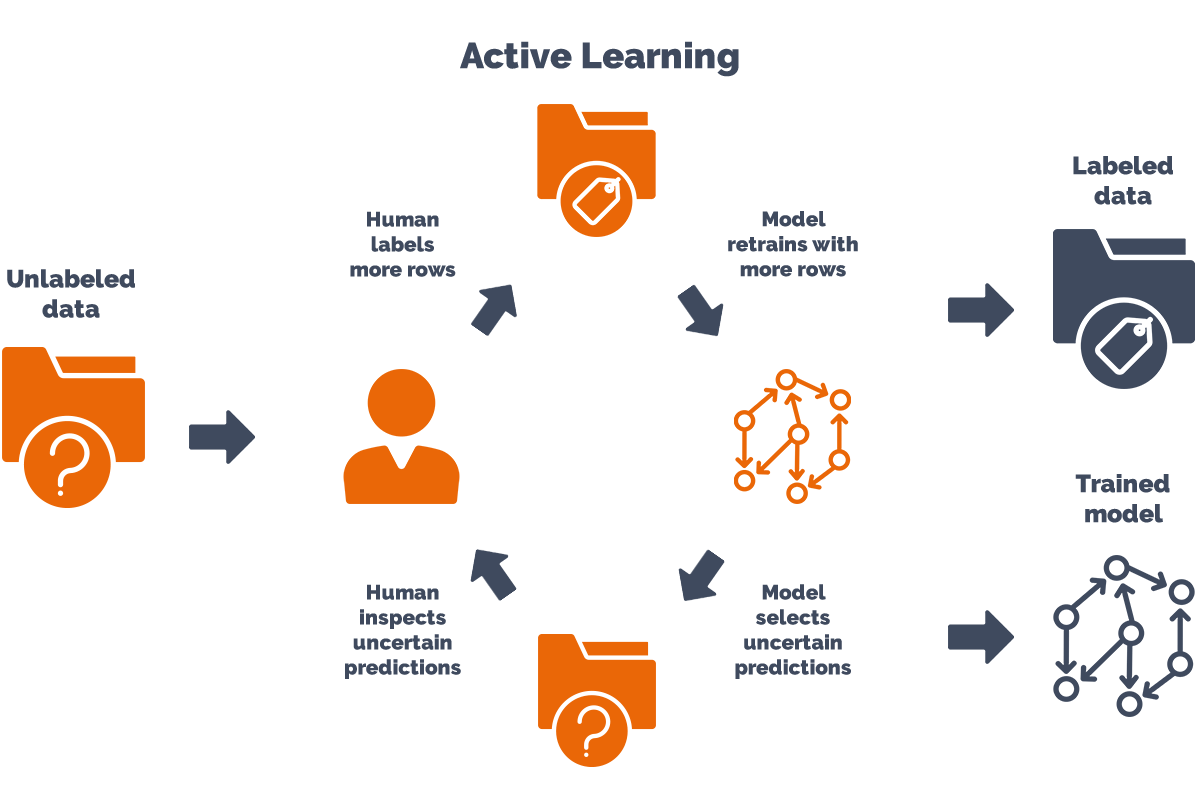
Кроме того, активное обучение также позволяет исследовать различные стратегии маркировки. Активно выбирая сложные или неопределенные случаи, модель может извлечь выгоду из более разнообразного набора помеченных данных, помогая ей учиться на более широком спектре случаев и потенциально обнаруживая ранее незамеченные закономерности или идеи.
Эта гибкость в стратегии маркировки позволяет активному обучению адаптироваться и развиваться в соответствии с конкретными потребностями и характеристиками набора данных, максимально увеличивая потенциал точной и значимой маркировки.
Метрики оценки для маркировки данных обучения без учителя

В области неконтролируемого обучения оценка моделей приобретает особое значение. Чтобы всесторонне оценить производительность неконтролируемых алгоритмов маркировки данных, важно учитывать различные метрики оценки.
Эти показатели дают представление о качестве и эффективности используемых моделей. Среди ключевых показателей оценки в этой области — коэффициент силуэта, чистота и нормализованная взаимная информация (NMI).
Коэффициент силуэта
Коэффициент силуэта измеряет компактность и разделение кластеров, обеспечивая количественную меру качества кластеризации.
Чистота
Чистота оценивает степень, в которой каждый кластер содержит экземпляры из одного класса, тем самым указывая на точность результатов кластеризации.
Нормализованная взаимная информация
Нормализованная взаимная информация оценивает количество общей информации между наземными метками истинности и предсказанными кластерами.
→ Рассматривая эти показатели оценки, специалисты-практики могут лучше понять эффективность моделей обучения без учителя в различных сценариях и принимать обоснованные решения на основе их интерпретации и применения.
Проблемы и ограничения неконтролируемой маркировки данных

Неконтролируемая маркировка данных, несмотря на ее многочисленные преимущества, не застрахована от проблем и ограничений.
Отсутствие наземных ярлыков истины
Одна из основных проблем возникает из-за отсутствия наземных меток истины. В отличие от обучения с учителем, где маркированные данные легко доступны, маркировка данных без учителя зависит исключительно от внутренней структуры самих данных.
Это отсутствие меток достоверности затрудняет оценку точности процесса маркировки и оценку производительности используемых алгоритмов.
Интерпретируемость результатов кластеризации
Еще одна проблема заключается в интерпретируемости результатов кластеризации. Неконтролируемая маркировка данных часто использует алгоритмы кластеризации для группировки похожих точек данных вместе. Однако интерпретация и понимание значения и значения этих кластеров может быть сложной задачей. Процесс маркировки становится субъективным и сильно зависит от понимания аналитиком предметной области. В некоторых случаях результаты кластеризации могут не совпадать с предполагаемой семантикой или могут не фиксировать тонкие закономерности в данных.
Шум и выбросы
Кроме того, шумовые рекламные выбросы представляют собой еще одну серьезную проблему при неконтролируемой маркировке данных. Зашумленные точки данных или выбросы могут нарушить процесс кластеризации и привести к неточным результатам маркировки. Крайне важно правильно идентифицировать и обрабатывать эти аномалии, чтобы обеспечить надежные результаты маркировки.
→ Несмотря на эти проблемы, продолжаются исследования, направленные на устранение ограничений неконтролируемой маркировки данных.
Исследователи изучают такие методы, как частично контролируемое обучение, активное обучение и перенос обучения, чтобы включить ограниченные объемы помеченных данных или знаний предметной области в процесс неконтролируемой маркировки.
Применение неконтролируемой маркировки данных
Неконтролируемая маркировка данных — это мощная техника, которая находит применение в различных областях, революционизируя способ извлечения значимой информации из немаркированных данных.
Категоризация изображений
При категоризации изображений неконтролируемая маркировка данных позволяет автоматически упорядочивать и классифицировать обширные коллекции изображений, не полагаясь на уже существующие помеченные наборы данных. Используя такие алгоритмы, как кластеризация и уменьшение размерности, изображения можно группировать на основе визуального сходства, что обеспечивает эффективный поиск и анализ.
Категоризация текста
При категоризации текста неконтролируемая маркировка данных оказывается бесценной за счет автоматической организации неструктурированных текстовых данных в значимые категории.
Используя такие методы, как тематическое моделирование и кластеризация документов, тексты можно группировать на основе их семантического содержания, что позволяет выполнять такие задачи, как поиск документов, анализ настроений и системы рекомендаций.
Обнаружение аномалий
Еще одним важным применением неконтролируемой маркировки данных является обнаружение аномалий. Путем обучения моделей нормальному или ожидаемому поведению аномалии или выбросы в данных могут быть идентифицированы без явного обозначения их.
Это имеет огромное значение в различных областях, таких как обнаружение мошенничества, обнаружение сетевых вторжений и профилактическое обслуживание, где критически важным является выявление необычных шаблонов или поведения.
Сегментация клиентов
Сегментация клиентов — еще одна область, в которой неконтролируемая маркировка данных находит огромное значение. Анализируя поведение клиентов и демографические данные, алгоритмы кластеризации могут автоматически идентифицировать отдельные сегменты клиентов на основе их предпочтений, моделей покупок или других соответствующих факторов.
Затем эту информацию можно использовать для разработки маркетинговых стратегий, персонализированных рекомендаций и оптимизации обслуживания клиентов.
Анализ социальных сетей
Анализ социальных сетей также значительно улучшается за счет методов неконтролируемой маркировки данных. Анализируя сетевые структуры, сообщества и модели взаимодействия, алгоритмы неконтролируемого обучения могут автоматически обнаруживать влиятельных пользователей, идентифицировать тематические кластеры и раскрывать скрытые отношения в социальных сетях. Эти знания можно использовать для целевого маркетинга, анализа социального влияния и понимания динамики распространения информации.
Гибридные подходы
Гибридные подходы появились как мощные методы, которые используют сильные стороны как неконтролируемых, так и контролируемых методов обучения. В этом разделе мы углубимся в мир гибридных подходов, где мы увидим интеграцию самоконтролируемого обучения, частично контролируемого обучения и методов трансферного обучения.
Комбинируя размеченные и неразмеченные данные, эти подходы направлены на повышение производительности и эффективности неконтролируемой маркировки данных.
Самостоятельное обучение
Самоконтролируемое обучение выделяется как выдающийся гибридный подход, который использует немаркированные данные для генерации управляющих сигналов.
Это достигается путем формулирования вспомогательных задач, которые позволяют модели изучать значимые представления из данных.
Затем эти представления можно использовать для управления неконтролируемым процессом маркировки, облегчая идентификацию шаблонов и структур в данных.
Полуконтролируемое обучение
В полууправляемых методах обучения используются как размеченные, так и неразмеченные данные, где ограниченные размеченные данные используются в сочетании с большим объемом неразмеченных данных.
В этом подходе используется предположение, что распределение размеченных и неразмеченных данных похоже.
Изучая размеченные данные и обобщая эти знания на неразмеченные данные, обучение с полуучителем устраняет разрыв между контролируемыми и неконтролируемыми методами, улучшая процесс маркировки.
Трансферное обучение
Трансферное обучение, еще один гибридный подход, позволяет передавать знания, полученные из одной задачи или области, в другую. Этот метод позволяет моделям использовать предварительно обученные знания о связанной задаче или наборе данных, что может значительно ускорить процесс маркировки. Используя размеченные данные из исходной задачи, модель получает ценную информацию, которую можно перенести в неконтролируемую задачу маркировки, что приводит к повышению производительности и эффективности.
→ Интеграция этих гибридных подходов дает множество преимуществ для неконтролируемой маркировки данных.
Используя как размеченные, так и неразмеченные данные, эти методы упрощают обнаружение скрытых шаблонов и структур, а также используют уже существующие знания.
В результате гибридные подходы повышают производительность и эффективность неконтролируемой маркировки данных, открывая возможности для более точного и эффективного анализа данных и принятия решений.
Этика и справедливость в неконтролируемой маркировке данных

Этика и справедливость играют решающую роль в неконтролируемой маркировке данных, и важно изучить этические последствия, вытекающие из этой практики.
Предвзятость
Одной из основных проблем является возможность предвзятости в процессе маркировки.
- Неконтролируемая маркировка данных основана на алгоритмах и методах машинного обучения для автоматического назначения меток неаннотированным данным.
- Однако эти алгоритмы могут наследовать предубеждения от обучающих данных или лежащих в их основе моделей, что приводит к несправедливым или дискриминационным ярлыкам.
- Жизненно важно решить эту проблему, разработав методы выявления и устранения предвзятости в процессе маркировки.
Справедливость
Справедливость — еще один важный аспект, который следует учитывать при неконтролируемой маркировке данных. Метки, созданные с помощью неконтролируемых методов, должны быть честными и непредвзятыми, одинаково относиться ко всем точкам данных, независимо от расы, пола или других защищенных характеристик.
Достижение справедливости требует тщательного мониторинга и оценки процесса маркировки, чтобы гарантировать, что он не увековечивает и не усиливает существующее неравенство.
Прозрачность
Прозрачность алгоритмов неконтролируемой маркировки и базовых источников данных необходима для обеспечения подотчетности и обеспечения внешнего контроля.
Конфиденциальность
Процесс маркировки часто требует доступа к большим наборам данных, некоторые из которых могут содержать конфиденциальную или личную информацию. Крайне важно обращаться с этими данными с максимальной осторожностью, обеспечивая защиту конфиденциальности и соблюдение правовых и этических норм. Методы анонимизации и протоколы защиты данных должны быть реализованы для защиты прав на неприкосновенность частной жизни и предотвращения любого неправомерного использования или несанкционированного доступа к данным.
Этические нормы неконтролируемой маркировки данных
Для продвижения этических практик при неконтролируемой маркировке данных можно принять несколько мер.
- Во-первых, должны быть четкие рекомендации и стандарты для проведения неконтролируемой маркировки, решения таких вопросов, как предвзятость, справедливость и конфиденциальность.
- Усилия по исследованиям и разработкам должны быть сосредоточены на разработке алгоритмов, менее подверженных предвзятости и обеспечивающих справедливость.
- Сотрудничество между специалистами по данным, специалистами по этике и экспертами в предметной области имеет решающее значение для обеспечения междисциплинарного подхода, учитывающего различные точки зрения и этические соображения.
- Регулярный аудит и оценка неконтролируемого процесса маркировки необходимы для выявления и исправления любых этических недостатков.
- Это включает в себя мониторинг производительности алгоритмов, проверку помеченных данных на предмет возможной систематической ошибки, а также проведение внешних аудитов или проверок независимыми организациями.
- Участие общественности и участие в дискуссиях, касающихся этики неконтролируемой маркировки данных, также может способствовать прозрачности, подотчетности и этичному принятию решений.
→ В заключение, этика и справедливость имеют первостепенное значение при неконтролируемой маркировке данных. Принимая во внимание эти соображения, мы можем способствовать ответственному и этичному использованию методов неконтролируемой маркировки данных, избегая при этом вреда и способствуя справедливости и прозрачности в более широкой экосистеме данных.
Будущие направления и направления исследований
В области неконтролируемой маркировки данных будущее несет многообещающие возможности и захватывающие направления исследований.
Погружаясь в последний раздел, мы обнаруживаем, что вглядываемся в горизонт возможностей.
Федеративное обучение
Одной из важных областей исследований является интеграция неконтролируемого обучения с другими развивающимися областями искусственного интеллекта и машинного обучения. Одной из таких областей является федеративное обучение, которое позволяет обучать модели на децентрализованных данных без необходимости совместного использования данных.
Комбинируя неконтролируемые методы маркировки данных с федеративным обучением, мы можем повысить конфиденциальность, используя коллективный интеллект распределенных наборов данных.
Обучение на протяжении всей жизни
Кроме того, концепция обучения на протяжении всей жизни, которая включает в себя постоянное получение знаний, представляет собой еще одно интригующее направление для будущих исследований.
Неконтролируемая маркировка данных может сыграть ключевую роль в обучении на протяжении всей жизни, позволяя автономным системам извлекать значимую информацию из немаркированных данных и соответствующим образом адаптировать свою базу знаний.
Постоянное обучение
Кроме того, непрерывное обучение, направленное на адаптацию моделей к новым задачам при сохранении ранее полученных знаний, может значительно выиграть от достижений в неконтролируемой маркировке данных.
Используя неконтролируемые методы, модели могут постоянно улучшать свое понимание неразмеченных данных и эффективно обобщать новые задачи.
→ Эти новые направления исследований подчеркивают важность неконтролируемой маркировки данных в формировании будущего искусственного интеллекта и машинного обучения, прокладывая путь к более надежным и универсальным системам, способным к автономному обучению и адаптации.
Заключение
Неконтролируемая маркировка данных — это преобразующий подход, который революционизирует извлечение значимой информации из немаркированных данных. Он имеет широкий спектр приложений и продолжает развивать область машинного обучения.
Благодаря автоматическому присвоению меток точкам данных без необходимости в предварительно помеченных обучающих данных неконтролируемая маркировка данных позволяет обнаруживать скрытые шаблоны, структуры и отношения в данных.
Для получения более увлекательного контента и идей обязательно подпишитесь на UBIAI в Твиттере @UBIAI5 и будьте в курсе последних обновлений и разработок в мире науки о данных и НЛП.