Изучение законов масштабирования Chinchilla и модели Meta LLaMA
Введение
В этом сообщении в блоге я буду обсуждать статью из Google DeepMind, в которой они проводят множество экспериментов по обучению больших языковых моделей, чтобы найти связь между размером модели, вычислительным бюджетом и нет. обучающих токенов. Я также расскажу о модели Meta LLaMA, которая была обучена с использованием результатов, полученных в результате экспериментов, проведенных DeepMind. Этот блог является частью моей серии блогов о больших языковых моделях. Вы можете просмотреть предыдущую публикацию о продвинутых методах подсказок здесь Навигация по пространству подсказок: методы эффективного исследования подсказок. В статье Чиншиллы в значительной степени упоминаются законы масштабирования для LLM от OpenAI. Итак, сначала я расскажу о результатах их работы.
Законы масштабирования для LLM от OpenAI
В 2020 году OpenAI опубликовал статью «Законы масштабирования для моделей нейронного языка». Они пришли к выводу, что потери масштабируются по степенному закону в зависимости от размера модели, размера набора данных и объема вычислений, используемых для обучения. Глубина и ширина сети оказывают минимальное влияние. Эти взаимосвязи помогли им прийти к выводу, что «Большие модели значительно более эффективны для выборки, так что оптимально эффективное с точки зрения вычислений обучение включает в себя обучение очень больших моделей на относительно небольшом количестве данных и значительные остановки перед конвергенцией».

Обучение оптимальным для вычислений LLM от DeepMind
Эта статья была опубликована в 2022 году. Основная цель этой статьи состояла в том, чтобы найти взаимосвязь между тремя факторами. Этими факторами являются размер модели, количество токенов и вычислительный бюджет. Они пришли к выводу, что нынешние LLM, такие как 175B GPT-3, 280B Gopher и 530B Megatron, значительно недоучены. Все эти модели увеличили количество параметров, но данные для обучения остались постоянными. Авторы отмечают, что для оптимального для вычислений обучения количество обучающих токенов и размер модели должны масштабироваться одинаково. Они обучили около 400 языковых моделей в диапазоне от 70 миллионов до более 16 миллиардов параметров на 5-500 миллиардах токенов.

Обнаружив взаимосвязь между тремя факторами, они обучили новый LLM под названием Chinchilla, который использует тот же вычислительный бюджет, что и 280B Gopher, но имеет 70B параметров и в 4 раза больше обучающих данных. Шиншилла превосходит Gopher (280B), GPT-3 (175B), Jurassic-1 (178B) и Megatron (530B). Этот результат противоречит «Законам масштабирования для LLM» OpenAI. Теперь относительно небольшие модели могут давать более высокую производительность, если обучаться на большем количестве данных. Меньшие модели легко поддаются тонкой настройке, а также имеют меньшую задержку при выводе. Эти модели не должны иметь минимальные возможные потери, чтобы быть оптимальными для вычислений.
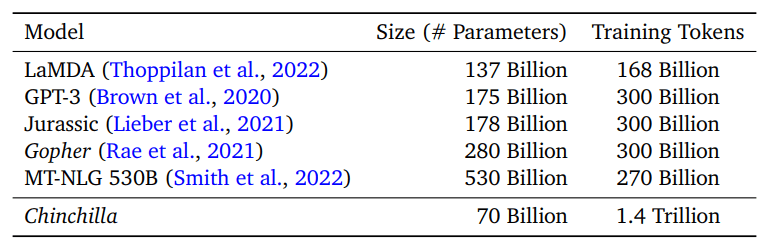
Главный вопрос для их исследования: «Учитывая фиксированный бюджет FLOP, как можно найти компромисс между размером модели и количеством обучающих токенов?». Они попробовали три разных подхода, чтобы ответить на этот вопрос. Они предположили степенную зависимость между вычислением и размером модели.
Подход 1. Исправьте размеры моделей и измените количество обучающих токенов
В первом подходе они зафиксировали размеры моделей (75 млн, 250 млн, 500 млн, 1 млрд, 2,5 млрд, 5 млрд, 10 млрд) и меняют количество обучающих токенов с фиксированным количеством FLOPS. Используя степенной закон, они выяснили, что оптимальный размер модели для вычислительного бюджета Gopher (5,76 × 10^23) составляет 67 млрд, а количество обучающих токенов должно составлять 1,5 трлн.

Подход 2: профили IsoFLOP
Во втором подходе они изменяют размер модели для фиксированного набора из 9 различных обучающих счетчиков FLOP (в диапазоне от 10 ^ 18 до 10 ^ 21 FLOP). Этот подход отвечает на вопрос «Для данного бюджета FLOP, каково оптимальное количество параметров?». Во время обучения они предполагают, что для модели с более чем 𝐷 маркерами предлагается длина косинусного цикла, которая затухает в 10 раз примерно на 𝐷 маркеров. Этот подход предполагает, что оптимальный размер модели для вычислительного бюджета Gopher составляет 63 млрд, а количество обучающих токенов должно составлять 1,4 трлн.

Подход 3. Подгонка параметрической функции потерь
Для третьего подхода они попытались объединить окончательную потерю двух вышеупомянутых подходов как параметрическую функцию параметров модели и количества токенов. Они предложили функциональную форму, а затем минимизировали потери Хубера, чтобы оценить оптимальный размер модели для бюджета Gopher Flop, равного 40 миллиардам параметров.

Все три подхода предполагают, что по мере увеличения бюджета вычислений размер модели и объем обучающих данных должны увеличиваться примерно в равных пропорциях. Первый и второй подходы дают очень похожие прогнозы для оптимальных размеров модели. Третий подход предполагает, что модели меньшего размера будут оптимальны для больших бюджетов вычислений. Модель Chinchilla, которую они обучили с использованием приведенных выше результатов, была обучена на MassiveText. Он использует оптимизатор AdamW и токенизатор SentencePiece. Примерно на 80% косинусного цикла AdamW проходит обучение модели на оптимизаторе Adam.
модели LLaMA
Meta выпустила коллекцию моделей с параметрами от 7B до 65B. Эти модели были эффективно обучены с использованием законов масштабирования Chinchilla. Эти меньшие модели дешевле при выводе и обучаются на общедоступных наборах данных. LLaMA-13B превосходит GPT-3 в большинстве тестов, несмотря на то, что он в 10 раз меньше. Эти модели не самые быстрые в обучении, но они быстрее делают выводы.

Они использовали кодирование парами байтов. Для моделей параметров 6B и 13B они прошли обучение с токенами 1T. Для моделей параметров 32B и 65B они прошли обучение с токенами 1,4T. Они использовали основные архитектурные детали оригинального Transformer, но с небольшими изменениями по сравнению с моделями Palm, GPT-3 и другими. Они использовали предварительную нормализацию, функцию активации SwiGLU и поворотные вложения вместо позиционных вложений. Они использовали оптимизатор AdamW и каузальное многоголовое внимание. Для эффективной реализации они отдали предпочтение сохранению активаций на случай их пересчета при обратном проходе.
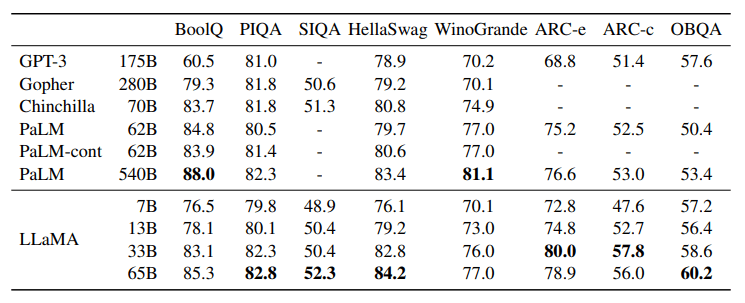
В статье представлены и другие бенчмарки, на которых тестировались модели LLaMA. Эти современные базовые модели с открытым исходным кодом доказали, что относительно небольшие модели могут превзойти большие модели при эффективном и длительном обучении.
Заключительные замечания
В заключение, применение закона масштабирования шиншиллы при обучении больших языковых моделей обеспечило прорыв в оптимизации использования вычислительных ресурсов и достижении эффективного обучения. Признавая необходимость обучения моделей в течение более длительного времени и большего количества токенов, закон масштабирования шиншиллы предлагает оптимальный для вычислений подход, который повышает производительность и возможности больших языковых моделей. Замечательная модель LLaMA является свидетельством эффективности этого подхода, поскольку она была обучена на впечатляющем 1 триллионе токенов при сохранении эффективности. В следующем сообщении блога я расскажу о таких языковых моделях, как Alpaca, Vicuna и WizardLM. Одна общая черта этих моделей заключается в том, что все три из них являются усовершенствованными версиями модели LLaMA. Я также объясню, чем эти модели отличаются от данных, которые они собрали для эффективной тонкой настройки.
Спасибо, что прочитали!
Подпишитесь на меня в LinkedIn!
Ссылки