В то время как будущее машинного обучения и MLOps обсуждается, специалистам-практикам по-прежнему необходимо следить за своими моделями машинного обучения в производственной среде. Это непростая задача, поскольку инженеры машинного обучения должны постоянно оценивать качество данных, которые входят и выходят из их конвейеров, и следить за тем, чтобы их модели генерировали правильные прогнозы. Чтобы помочь инженерам машинного обучения решить эту задачу, было разработано несколько решений для мониторинга AI/ML.
За последние несколько недель я рассмотрел несколько из этих решений для мониторинга AI/ML для клиента. Мы рассматривали вендорские решения (Arize, Superwise, Aporia), open-source (Очевидно, Deepchecks) и даже создавали собственное решение. Эти обзоры дали мне много пищи для размышлений о сути мониторинга AI/ML и о том, как он должен вписываться в жизненный цикл MLOps.

В этой статье я расскажу о природе мониторинга AI/ML и о том, как он связан с проектированием данных. Во-первых, я представлю сходство между мониторингом AI/ML и проектированием данных. Во-вторых, я перечислю дополнительные функции, которые могут предоставить решения для мониторинга AI/ML. В-третьих, я кратко коснусь темы наблюдаемости AI/ML и ее связи с мониторингом AI/ML. Наконец, я представлю свое заключение о области мониторинга AI/ML и о том, как его следует рассматривать для обеспечения успеха вашего проекта AI/ML.
Мониторинг AI/ML — это инженерия данных…
Между мониторингом AI/ML и проектированием данных есть много общего. Давайте сначала посмотрим на упрощенный конвейер AI/ML в продакшене:

Мы можем выделить несколько общих моментов с конвейером разработки данных:
- Каждый шаг конвейера принимает и создает данные.
- Шаги могут быть объединены в цепочку (например, как конвейер UNIX).
- В конце процесса он создает оповещения, метрики и информационные панели.
Мы также можем заметить некоторые различия, характерные для конвейеров AI/ML:
- В какой-то момент используется модель AI/ML.
- … вот и все!
Имеет ли большое значение использование модели AI/ML в конвейере данных? С одной стороны, это всего лишь еще один шаг, на котором данные вводятся и генерируются. С другой стороны, модели AI/ML требуют особого внимания для правильной обработки методологии (например, предотвращения утечки данных), оборудования (например, с использованием графических процессоров) и новых компонентов (например, реестров моделей). Поскольку эта дополнительная сложность требует определенного набора навыков и опыта, я склонен думать, что это различие имеет значение. Лучшим доказательством является то, что нам нужны конкретные инженеры для решения этих задач (например, инженеры по машинному обучению).
Давайте теперь рассмотрим, как этот вопрос влияет на мониторинг AI/ML.
…и это больше, чем Data Engineering
Дополнительную ценность мониторинга AI/ML можно описать одним словом: семантика. Люди гораздо эффективнее работают с конкретными понятиями, чем с общими. Процитируем эту замечательную статью Франсуа Шолле (Дизайн взаимодействия с пользователем для API):
Как и большинство вещей, дизайн API не сложен, он просто включает в себя соблюдение нескольких основных правил. Все они основаны на основополагающем принципе: вы должны заботиться о своих пользователях. Все они. Не только умные, не только специалисты. Держите пользователя в центре внимания все время. Да, включая тех сбитых с толку новых пользователей с ограниченным контекстом и небольшим терпением. Каждое дизайнерское решение должно приниматься с мыслью о пользователе.
Например, в нейронных сетях мы можем использовать удобные для пользователя понятия, такие как «слои», «выпадение» и «объединение», вместо более общих терминов, таких как «операции», «фильтры» и «агрегации». Точно так же для мониторинга AI/ML мы можем адаптировать пользовательский интерфейс и API для работы с такими понятиями, как «сегменты», «базовые показатели» и «среды». Основополагающие методы можно найти в каждом конвейере обработки данных, но пользовательский интерфейс был адаптирован для того, чтобы сосредоточить внимание пользователей на их вариантах использования и помочь им стать более продуктивными.
В связи с этим возникает вопрос, ценна ли эта дополнительная семантическая ценность для специалистов по данным и инженеров по машинному обучению. Я считаю, что это так. Называть вещи (т. е. придумывать семантику) сложно, и люди склонны быть ленивыми (т. е. системы 1 и 2). Наша главная задача всегда состоит в том, чтобы структурировать решение и найти лучшие абстракции, чтобы расширить возможности разработчиков, не добавляя слишком много сложности. Поэтому лучше всего позволить экспертам в этой области думать о лучших решениях, как это делает большинство веб-разработчиков, когда они используют фреймворк, написанный специалистами в этой области.
Давайте теперь рассмотрим, как могут помочь авторы решений для мониторинга AI/ML.
Мое мнение о решениях для мониторинга AI/ML
Все решения для мониторинга AI/ML, которые я тестировал, справились с основным рабочим процессом: прием данных, вычисление метрик, уведомление о предупреждениях и визуализация ошибок. Хотя у каждого из них есть свои сильные и слабые стороны, я вижу, как каждое из этих решений может принести пользу конечным пользователям и помочь им начать работу с лучшими инструментами и практиками.
Однако я обнаружил серьезный недостаток большинства решений от поставщиков: они не позволяют экспортировать показатели в другие системы. Это проблематично по двум причинам. Во-первых, пользователи не могут использовать решения поставщиков для поддержки пользовательских вариантов использования (например, для предоставления метрик бизнесу или оптимизации обучения своих моделей). Это означает, что инженеры машинного обучения должны либо полностью принять решение поставщика и придерживаться его, либо воссоздать собственные конвейеры для удовлетворения других своих потребностей. Во-вторых, большинство поставщиков повторно реализуют существующие компоненты вместо того, чтобы использовать компоненты, разработанные другими поставщиками. Например, я бы предпочел использовать Tableau для визуализации и Datadog для оповещений, чем инструменты, предоставляемые поставщиками мониторинга AI/ML. Поставщики мониторинга AI / ML не могут догнать годы разработки и самоотверженности, которые другие поставщики данных вложили в свои продукты.
Я не виню в этом производителей мониторинга AI/ML. Создать все эти интеграции сложно, так как нет единого протокола для систем MLOps. У нас есть HTTP, SMTP и TCP/IP в качестве универсального моста для Интернета, но у нас нет ничего подобного для MLOps. В результате у инженеров машинного обучения остается только два варианта: (1) надеяться, что поставщики выполнят все свои варианты использования сейчас и в будущем, или (2) создать собственное решение и сосредоточиться на функциональной совместимости своей платформы. В зависимости от вашего профиля (т. е. конечный пользователь или инженер) вы можете выбрать один вариант вместо другого.

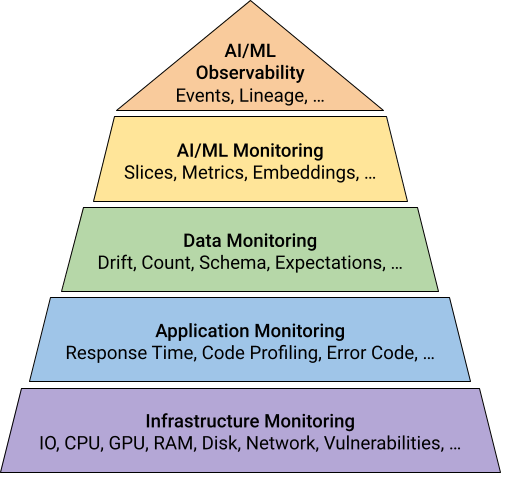
Примечание о наблюдаемости AI/ML
Недавно у нас была интересная дискуссия о мониторинге и наблюдаемости AI/ML в сообществе MLOps. Рафаэль Хугвлитс даже написал отличную статью, в которой обобщаются эти концепции. Короче говоря, мониторинг AI/ML относится к способности контролировать отдельные компоненты (например, какая ошибка произошла, где и когда), в то время как наблюдаемость AI/ML обеспечивает целостный и высокоуровневый обзор всей системы (например, почему произошла ошибка и что ее вызвало).
Многие поставщики мониторинга AI/ML рекламируют себя как «решения для наблюдения AI/ML». Однако я считаю, что это преувеличение, так как большинство их решений рассматривают только отдельные модели и учитывают только их входы и выходы. Они не отслеживают весь конвейер данных (например, первый использованный набор данных) и не могут связать события, происходящие во время его работы (например, новый столбец был добавлен другой командой).
В результате инженер ML должен обеспечить эти возможности наблюдения AI/ML по всему конвейеру. Инженеры машинного обучения могут использовать систему происхождения (например, OpenLineage) или внедрить Архитектуру, управляемую событиями (EDA) для отслеживания высокоуровневых сигналов, которые запускаются на протяжении всего жизненного цикла конвейера. Контракты данных также можно использовать для определения того, что является нормальным, а что нет. Я считаю, что это многообещающая область исследований, которая может улучшить зрелость платформ MLOps.
Выводы
Мониторинг AI/ML можно рассматривать как надмножество обработки данных, но его не следует рассматривать как подмножество. Таким образом, решения для мониторинга AI/ML могут помочь преодолеть разрыв между инструментами обработки данных и вариантами использования MLOps, если они не исключают возможности интеграции своих показателей с другими системами. Хотя искушение и ограничения для принятия лучших решений на рынке могут быть высокими, я призываю вас подумать, соответствует ли ценностное предложение как вашим потребностям, так и вашим принципам программного обеспечения.
В заключение этой статьи я хотел бы сослаться на одну из моих любимых книг: Гёдель, Эшер, Бах Дугласа Р. Хофштадтера. Мне нравится, как автор описывает бесконечный цикл, который возникает, когда системы остаются максимально открытыми, даже для самих себя. Например, ДНК создает белки, которые могут изменять ДНК или управлять ею, а программа может получать инструкции для создания другой программы (например, компилятора). Я нахожу сходство в конвейерах данных и AI/ML, и я был бы очарован процессом MLOps, который мог бы создать модель, способную управлять процессами MLOps. Мы должны стремиться сосредоточиться на компоновке и интероперабельности наших систем, поскольку мы никогда не знаем, что может произойти дальше.
