Вы устали стоять в длинных очередях на кассе? Вы устали от того, что не знаете цену предмета, пока не дойдете до кассы? Что, если бы вы могли быть своим собственным кассиром? Представьте себе торговую систему, которая позволяет вам легко сравнивать цены на один и тот же товар разных брендов. И было бы здорово иметь инструмент, который поможет вам управлять своими расходами во время покупок? В этом сообщении блога мы углубимся в трансформационные технологии, которые меняют ландшафт розничной торговли. Присоединяйтесь к нам, пока мы изучаем ответы на эти вопросы и раскрываем будущее расширенного опыта покупок.
Эволюция умных решений для покупок
С появлением Amazon Dash Cart розничная торговля изменилась. Вы просто заходите в магазин, кладете нужные товары в корзину, и они моментально появляются на вашем экране. Оплата счета становится легкой задачей, позволяя вам быстро покинуть магазин. Больше не нужно ждать в скучных очередях или безустанно обыскивать весь магазин только для того, чтобы узнать цену товара. С этой умной тележкой вы становитесь кассиром сами себе.
Но как мы могли построить Dash Cart?
Возможно, вы уже задумывались над этим вопросом раньше: создание этой передовой технологии влечет за собой многочисленные проблемы, и есть несколько аспектов, которые мы должны учитывать:
- Аппаратное обеспечение
- Программные приложения, которые взаимодействуют с пользователями
- Обзор, который обрабатывается камерами, расположенными вокруг корзины.
- Подключение приложения к платежным сервисам
- Создание быстрой базы данных с продуктами розничного магазина
В первом разделе я углубился в оценку и выбор наиболее подходящей модели компьютерного зрения для нашего проекта. Путем исследований и анализа я определил идеальную модель, отвечающую нашим требованиям. Теперь, в этой статье, я хочу углубиться в аспекты машинного зрения и машинного обучения и поделиться своим опытом использования мощной библиотеки, которая позволила быстро и точно обнаруживать объекты. Присоединяйтесь ко мне, чтобы узнать, как эта библиотека стала ключом к раскрытию потенциала большой базы данных, содержащей почти 1000 продуктов.
Путь к мощной библиотеке обнаружения
Если вы будете искать в Интернете, вы будете поражены таким количеством библиотек. Какой из них лучше всего работает с огромными базами данных? Как мы должны создать нашу базу данных? Какой из них обнаруживает быстрее? Какой из них быстрее обучается? Какой из них более точен? Должен ли я вообще использовать обнаружение объектов, или мой сценарий можно обработать с помощью простой классификации изображений?
Давайте ответим на эти вопросы шаг за шагом. Прежде всего, « Почему обнаружение объектов вместо классификации изображений? ”
Самая важная причина заключается в том, что покупатели обычно пропускают товары через камеры и кладут их в корзину, что приводит к движению. Однако можем ли мы изменить сценарий, чтобы устранить движение? Было бы проще и быстрее добиться классификации изображений?
Конечно, мы можем изменить сценарий, введя дополнительное оборудование. Но может ли классификационная модель предложить лучшую скорость и эффективность? Я реализую 6 моделей классификации и обучаю их с нуля, чтобы проверить их скорость и точность. Давайте рассмотрим бенчмарк на основе моего тестирования:

Как видите, эти модели не только медленны в обучении, но и имеют очень низкий FPS (кадров в секунду), что делает их непригодными для целей реального времени. Даже MobileNet, облегченная модель, которая быстрее других моделей, демонстрирует возможности для улучшения с точки зрения скорости.
Итак, модели классификации не являются нашими кандидатами. Теперь другие вопросы остаются без ответа: Какую модель обнаружения нам следует использовать? ”
Я провел обширное тестирование ряда моделей обнаружения и обучил их нашей конкретной базе данных розничной торговли, чтобы определить наиболее подходящий вариант. К ним относятся YOLOv4, YOLOv4 tiny, YOLOv5, обнаружение объектов TF Lite, GroundingDINO (модель на основе трансформатора), DETR (еще одна модель на основе трансформатора), YOLO9000, RCNN и YOLOv8. Среди этих моделей YOLOv8 продемонстрировала превосходную производительность по сравнению с YOLO9000, которая может обнаруживать и распознавать 9000 классов. В моей оценке 1000 классов YOLOv8 продемонстрировал значительно лучшую производительность.
YOLOv4 tiny и TF Lite — легкие и быстрые модели сами по себе, но они не справляются со скоростью, достигнутой YOLOv8. Замечательная скорость и точность YOLOv8 делают его оптимальным выбором для реализации моего проекта.

Давайте посмотрим на результат YOLOv8 для 40 продуктов из нашей розничной базы данных в качестве образца, мы попробуем его на ЦП и двух разных графических процессорах с 1 камерой и 2 камерами, работающими параллельно. Как вы можете видеть, в худшем случае (ядро процессора i5 с 2 камерами) мы по-прежнему получаем около 30 кадров в секунду, что не только намного быстрее, чем модели классификации, но также быстрее и точнее, чем другие алгоритмы обнаружения. Во всех наших тестах мы примерно получаем точность выше 95 процентов.
И в нашем лучшем случае (GPU 3060, с одной камерой) мы получаем 200 FPS, что замечательно и подходит для проектов в реальном времени.
Чтобы еще больше проиллюстрировать замечательную производительность YOLOv8, давайте взглянем на его матрицу путаницы. Матрица путаницы демонстрирует способность модели правильно классифицировать объекты и выявлять ложноположительные и ложноотрицательные результаты. Результаты ясно подчеркивают превосходную точность YOLOv8 и минимальную путаницу при обнаружении и классификации объектов.
В целом, выдающаяся частота кадров, высокая точность и впечатляющая матрица путаницы YOLOv8 демонстрируют его исключительные возможности и делают его мощным решением для задач обнаружения объектов».

Определив YOLOv8 как нашу идеальную модель, я начал процесс настройки и тонкой настройки выбранной модели, чтобы обеспечить ее оптимальную производительность в нашем уникальном сценарии. Благодаря тщательному тестированию и самоотверженным усилиям я потратил много времени и опыта на настройку параметров, оптимизацию гиперпараметров и повторение процесса обучения. Эта настройка позволила мне адаптировать YOLOv8 к нашим конкретным потребностям, что привело к замечательной скорости и точности обнаружения объектов. Объединив информацию, полученную в результате оценки, выбора и настройки модели, я успешно достиг желаемого уровня производительности для нашего проекта.
В заключение, YOLOv8 демонстрирует исключительную производительность с точки зрения скорости и точности даже на слабом оборудовании. По сравнению с моделями классификации и обнаружения YOLOv8 выделяется как лучший выбор. Он эффективно решает наши проблемы и требования, отвечая на все наши вопросы, кроме одного: как нам создать базу данных?
Создание базы данных: создание основы для успеха YOLOv8
Одной из наших самых больших проблем в этом проекте было создание идеальной базы данных. База данных играет решающую роль в обучении и оптимизации производительности нашей модели. Благодаря обширным исследованиям и экспериментам я обнаружил несколько важных соображений, касающихся создания эффективной базы данных:
- Разрешение фотографий имеет первостепенное значение: для обеспечения точного обнаружения объектов необходимы фотографии с высоким разрешением. Мелкие детали и тонкие характеристики предметов могут сильно повлиять на производительность модели.
- Фотографии реального окружения: крайне важно сделать фотографии предметов в корзине, отражающих реальную обстановку, в которой будет выполняться обнаружение. Это помогает модели учиться и адаптироваться к конкретным условиям, с которыми она столкнется.
- Количество имеет значение: изначально у нас было около 100 фотографий. Однако для повышения надежности модели мы увеличили размер набора данных в 5 раз. Это расширение позволяет лучше обобщать и улучшает способность модели обрабатывать различные сценарии.
- Всеобъемлющее покрытие: для получения точных и надежных результатов в базу данных должны быть включены фотографии каждого предмета со всех сторон. Это позволяет модели обнаруживать объекты с разных точек зрения, повышая общую производительность.
- Баланс базы данных: важно обеспечить сбалансированное распределение фотографий для каждого элемента в базе данных. Наличие равного количества фотографий для каждого элемента помогает предотвратить предвзятость и гарантирует, что модель получает достаточную подготовку по всем классам, что приводит к более точным результатам обнаружения.
- Этапы предварительной обработки: перед обучением модели мы выполнили необходимые шаги предварительной обработки изображений. Это включало в себя такие настройки, как оптимизация условий освещения, поворот изображения и усиление контраста между фоном и целевым элементом. Эти шаги помогают устранить потенциальные препятствия и повысить точность процесса обнаружения.
Принимая во внимание эти аспекты и внедряя хорошо сбалансированную базу данных, мы можем максимально повысить эффективность и точность нашей модели YOLOv8, преодолев одну из основных проблем в нашем проекте. Как вы можете видеть на картинке, функция YOLOv8 замечательна.

В заключение мы изучили различные модели компьютерного зрения и определили наиболее подходящую для нашего проекта. Мы также узнали о создании эффективной базы данных. Двигаясь вперед, важно рассмотреть дополнительные функции для улучшения взаимодействия с пользователем. Одной из важных функций является возможность для пользователей добавлять и удалять товары из корзины. Для этого требуется плавная интеграция с нашей системой искусственного интеллекта и своевременные обновления на сервере. Внедряя эту функцию, мы можем предоставить пользователям беспрепятственный и удобный процесс совершения покупок, гарантируя точное обнаружение и быструю реакцию на изменения в содержимом корзины.
Управление корзиной: упрощение добавления и удаления товаров
У нас было две идеи реализации сценария добавления и удаления товаров из корзины: использование порогов и ограничивающих рамок и включение датчика веса. Каждый подход имеет свои преимущества и недостатки.
Первый сценарий, включающий использование порогов и ограничивающих рамок, предлагает исключительную скорость и простоту реализации. В этом сценарии нам нужно только проверить, превышает ли продукт пороговое значение и были ли предыдущие ограничивающие рамки выше, чем новые для сценария добавления. И наоборот, для сценария удаления все будет наоборот. Однако в некоторых случаях этот подход может не обеспечивать уровень точности, необходимый для точного обнаружения.

С другой стороны, второй сценарий с использованием датчика веса приводит к потенциальному замедлению. Мы неизбежно сталкиваемся с небольшой задержкой, пока ждем отправки запроса датчика на сервер. Несмотря на то, что мы предприняли усилия по оптимизации процесса для минимальной задержки, он по-прежнему вызывает некоторую системную задержку.
Чтобы учесть эти соображения, я разработал решение, сочетающее обе идеи. Мы обнаруживаем движение, используя пороги и ограничивающие рамки, и одновременно проверяем изменения с помощью датчика веса. Когда товар помещается в корзину и переходит границы, мы отправляем запрос на добавление на сервер. При этом датчик веса записывает и отправляет свои данные на сервер. Если два набора данных не совпадают, что свидетельствует о несоответствии, мы блокируем корзину и запрашиваем у пользователя разъяснения. Такой подход может привести к небольшой задержке при блокировке, но в случаях, когда все в порядке, пользователь не испытывает задержки.
Комбинируя эти подходы, мы достигаем баланса между скоростью и точностью, обеспечивая удобство работы пользователей и сохраняя при этом надежное управление предметами в корзине.
В заключение мы получили ценную информацию о моделях компьютерного зрения, определили наиболее подходящий вариант для нашего конкретного случая и развили понимание того, как создать эффективную базу данных. Имея эти компоненты, мы успешно справились с задачей управления корзиной, упростив добавление и удаление элементов.
Чтобы завершить часть нашего проекта, связанную с искусственным интеллектом, последним шагом будет решение вопроса о том, как отправлять данные на сервер, одновременно обрабатывая добавление и удаление элементов. Внедряя продуманную систему передачи данных, мы обеспечиваем оперативное обновление сервера, что позволяет точно и своевременно отслеживать содержимое корзины.
В следующем разделе мы углубимся в технические аспекты установления надежного соединения между нашей системой искусственного интеллекта и сервером, уделяя особое внимание эффективной обработке данных и обмену данными в реальном времени. Интегрируя эти элементы, мы стремимся предоставить пользователям мощную и удобную систему управления покупками.
Передача данных: интеграция ИИ с сервером
Чтобы обеспечить бесперебойную и эффективную передачу данных из нашей системы искусственного интеллекта на сервер, нам необходимо реализовать метод запустил и забыл. Наша цель — быстро отправлять обнаруженные элементы на сервер, не дожидаясь ответа. Скорость передачи данных имеет для нас первостепенное значение, поскольку мы стремимся к обработке в режиме реального времени и минимальному нарушению общего хода программы.
Для этого мы выполним процесс отправки данных в отдельном потоке. Таким образом, мы можем гарантировать, что другие части программы продолжат свое выполнение без каких-либо задержек, вызванных ожиданием отправки данных. Этот многопоточный подход позволяет нам эффективно обрабатывать задачу отправки данных в фоновом режиме, в то время как остальная часть программы работает непрерывно.
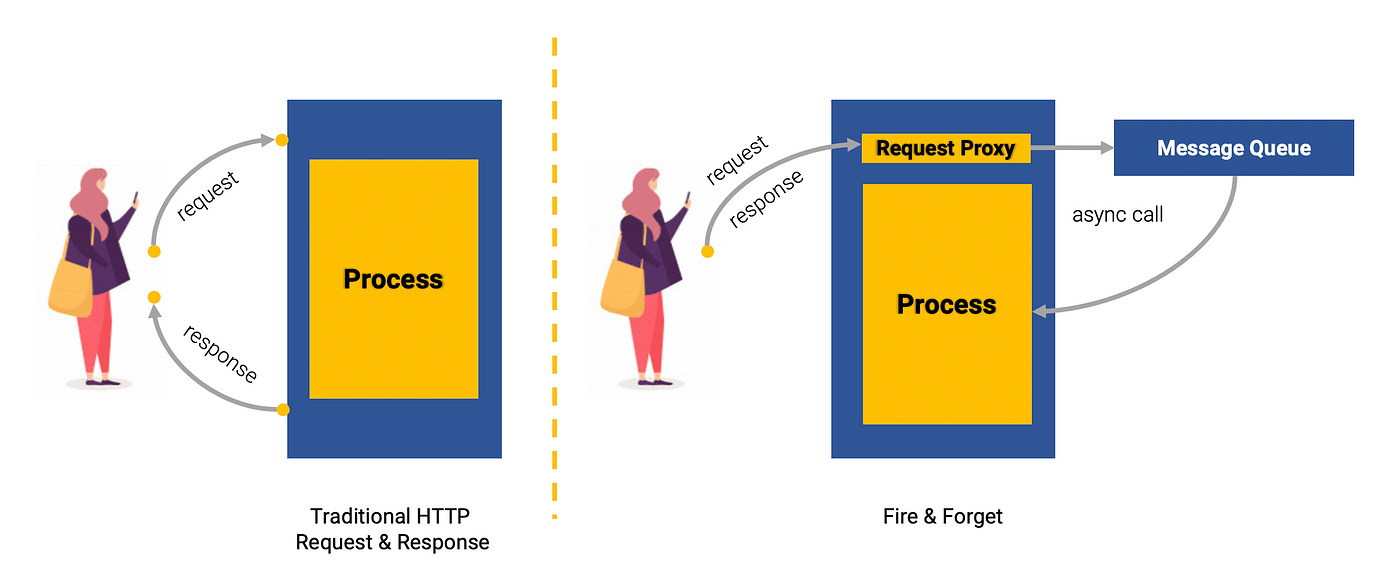
Реализуя метод «выстрелил и забыл» и используя отдельный поток для отправки данных, мы можем максимально увеличить скорость и эффективность нашей системы, обеспечивая почти мгновенную передачу обнаруженных элементов на сервер.
Заключение
В заключение мы изучили компьютерное зрение и ИИ в динамических покупках. Определив правильную модель, создав эффективную базу данных и решив такие проблемы, как управление корзиной и передача данных, мы заложили основу для беспрепятственного совершения покупок. Продолжая совершенствоваться, мы можем произвести революцию в покупках, повысив эффективность и точность. Будущее таит в себе огромный потенциал, поскольку мы формируем новую эру удобного и приятного обслуживания клиентов.
