Обеспечьте более быстрое взаимодействие с данными Hadoop
Авторы Охад Равив и Шай Эльбаз

Продукты PayPal, как общедоступные, так и внутренние, в значительной степени зависят от обработки данных с использованием самых разных методов и технологий. Мы, команда инженеров в глобальной группе науки о данных PayPal, несем ответственность за предоставление базовых решений для этих продуктов данных. Мы хотели бы поделиться интересным вариантом использования, с которым мы столкнулись, и тем, как мы его решили.
вступление
Экосистемы Spark, Hive и HDFS (распределенные файловые системы Hadoop) представляют собой технологии, ориентированные на онлайн-аналитическую обработку (OLAP). Они предназначены для обработки огромных объемов данных при полном сканировании. Время от времени пользователи хотят использовать одни и те же данные для более специализированных задач:
- Многострочная загрузка - исследуйте небольшие наборы (обычно 1%) данных по определенным идентификаторам (не случайным образом).
- Однострочная выборка - например, создание уровня обслуживания для выборки определенной строки по запросу REST-API.
Подобные задачи традиционно решаются с использованием выделенного хранилища и технологических стеков (HBase, Cassandra и т. Д.), Что требует дублирования данных и увеличивает эксплуатационные расходы.
В этом посте мы опишем наш путь к решению этой проблемы с использованием только Spark и HDFS. Мы начнем с представления примера использования, обобщим и определим требования, предложим несколько дополнительных решений и, наконец, погрузимся в наше окончательное решение.
Пример использования
В PayPal на нашей платформе работает более 30 миллионов продавцов. Чтобы помочь нам выявлять продавцов-мошенников или нарушения политик допустимого использования PayPal, мы периодически используем инструменты автоматического веб-сканирования для сбора общедоступной неконфиденциальной информации с выбранных веб-сайтов клиентов. Учитывая наш широкий круг продавцов, многие из которых имеют обширные веб-сайты, состоящие из многих страниц, эти усилия дают большие объемы данных.
Ежедневные данные сканирования вместе с дополнительными метаданными сохраняются в таблице Hive, которая разбита по датам.
В этом случае размер данных составляет ~ 150 ТБ для сжатых файлов, состоящих из ~ 2 Б веб-страниц, при среднем размере веб-страницы ~ 100 КБ.
Последующие приложения получают доступ к этим данным следующими способами:
- Полное сканирование - процессы пакетной аналитики просматривают все данные, например, для кластеризации похожих продавцов. Ожидаемое время работы часов.
- Многострочная загрузка. Наши специалисты по данным заинтересованы в определенном подмножестве веб-страниц продавцов, чтобы создать набор данных для их обучения модели. Ожидаемое время работы минут.
- Однострочная выборка. В некоторых случаях требуется получить определенную веб-страницу по ее URL-адресу. Например, REST-сервис для служб поддержки клиентов. Ожидаемое время выполнения секунд.

Мы заметили, что этот шаблон доступа к данным, который в основном используется для пакетной аналитики для большего количества специальных задач, появляется в большем количестве доменов по всей организации - Риск (данные транзакций, попытки входа в систему), Соответствие (кредитные обзоры), Маркетинг (управление кампаниями) , так далее.
Дополнительные решения

Таблица улья
Поняв необходимые задачи, мы начали с очень наивного решения - определить таблицу Hive поверх отсканированных данных и запросить ее с помощью Spark.
Это очень хорошо сработало для задачи пакетной обработки полного сканирования, поскольку именно в этом Spark преуспевает.
Однако когда пользователи пытались присоединиться к этой таблице с помощью многострочной выборки URL-адресов (обычно 0,1–1% строк), это заняло гораздо больше, чем ожидаемые несколько минут. Основные причины следующие:
- Перемешать - самая тяжелая операция в распределенных системах с точки зрения ЦП и сетевого ввода-вывода. Для набора URL-адресов среднего размера Spark использует соединение в случайном порядке (соединение с хешированием или слияние с сортировкой). При этом по сети передаются полные данные веб-страниц, даже если большинство строк отфильтрованы объединением с небольшой выборкой.
- Десериализация - даже для небольшого образца URL , когда Spark оптимизировался с помощью соединения на стороне карты (широковещательное соединение), ему все равно пришлось десериализовать все строки полные данные веб-страниц.
Получение одной строки определенной веб-страницы по запросу REST API было еще хуже с точки зрения взаимодействия с пользователем. Пользователям приходилось долго (несколько минут) ждать, пока Spark просканирует все данные веб-страниц.
Группирование
Группирование Hive и Spark - это шаг в правильном направлении для достижения того, что мы искали, по крайней мере, для задачи многострочной загрузки. Это механизм для хранения предварительно перемешанных данных для последующего использования их в операциях соединения, избегая повторяющихся перемешиваний одних и тех же данных. Это требует тесной взаимосвязи между метаданными и самими данными. Это означает, что пользователи не могут напрямую добавлять данные в базовые папки и, таким образом, отвлекаться от неуправляемой природы данных Hive и Spark.
В подходе с сегментацией нам нужно использовать Spark или Hive для сохранения данных в сегментах. При ведении все данные сохраняются в файлах, где каждый файл содержит только определенные ключи (по их хеш-значениям) и сортируется по ключу. Таким образом мы можем значительно улучшить многострочное соединение с данными.
Однако у этого подхода много недостатков:
- Нам нужно владеть или дублировать данные.
- Он поддерживает только один ключ для каждой таблицы.
- Нет готовой поддержки для выборки отдельной строки из данных в SLA в секундах, так как Spark не имеет API произвольного доступа.
- Spark и Hive bucketing несовместимы (СПАРК-19256).
- Возникает проблема Spark при чтении из нескольких файлов корзины (SPARK-24528).
Требования к продукту

Мы пришли к выводу, что готового решения для реализации всех необходимых шаблонов доступа к данным не существует. Основываясь на еще нескольких вариантах использования, с которыми мы столкнулись из различных групп в организации, мы решили обобщить наши предположения и требования, вытекающие из решения, чтобы охватить как можно больше вариантов использования:
Предположения
- Размер - данные потенциально огромны. Миллиарды строк, и каждая строка может иметь много столбцов или столбцов, содержащих большие полезные данные (например, веб-страницы ~ МБ).
- Модификация - данные предназначены только для добавления - например, каждый день добавляется новый раздел с новыми данными.
- Ключ - данные имеют естественные ключи, которые пользователи захотят запросить (может быть несколько ключей, и ключ может быть не уникальным).
- Право собственности - данные могут принадлежать другой команде (мы не можем изменять данные, их формат, макет и т. д.)
Требования
- Пользователи должны взаимодействовать с данными тремя упомянутыми способами - пакетной аналитикой, многострочной загрузкой и однорядной выборкой в определенных SLA.
- Избегайте дублирования данных (соображения стоимости - хранение, вычисления, операции).
- Поддержка нескольких ключей.
- Желательно использовать один и тот же стек технологий.
Подход к индексации
Уточнение предположений и требований привело нас к выводу, что нам нужен другой подход. Индексирование естественно подошло. Идея состоит в том, чтобы иметь тонкий слой, содержащий некоторые метаданные и указатели на «настоящие» данные. Таким образом, мы потенциально могли бы проделать большую часть работы с этим индексом и избежать или отложить работу с самими данными.
Техника индексирования очень распространена в системах данных и широко используется почти во всех доступных базах данных, даже в среде больших данных. Например, он доступен в Teradata, Netezza, Google's BigQuery и многих других. Естественно, что такая возможность есть и в экосистеме Spark.
Мы попытались найти предыдущие попытки в этом направлении и нашли Hyperspace от Microsoft, недавнюю работу, в которой делается попытка интегрировать подсистему индексирования в Spark. Однако, несмотря на то, что у них есть некоторые общие черты с тем, что нам нужно, их текущая функциональность и общее направление не соответствуют нашим упомянутым шаблонам доступа.
Мы решили продолжить наши усилия по созданию системы индексирования, интегрированной в Spark, Hive или HDFS.
Хранилища "ключ-значение"
Для решения задач загрузки нескольких строк и выборки одной строки нам нужен быстрый способ выполнения выборки по ключу. Для этого имеет смысл использовать специальный сервис «ключ-значение». На выбор есть множество вариантов, таких как HBase, Cassandra, Aerospike и др. Однако у этого направления есть много недостатков:
- Это чрезмерно для нашей задачи - эти технологии предназначены для обработки гораздо более сложных сценариев с гораздо меньшей задержкой.
- Хранилища «ключ-значение» управляют данными, поэтому вам нужно «владеть» данными или дублировать их.
- Это живые службы. Им требуются выделенные ресурсы и накладные расходы на операции, настройку, мониторинг и т. Д.
- Такие системы также используются критически важными приложениями реального времени. Массовое сканирование пакетными приложениями снизит общую производительность системы, что приведет к задержкам в работе критически важных приложений.
Диона

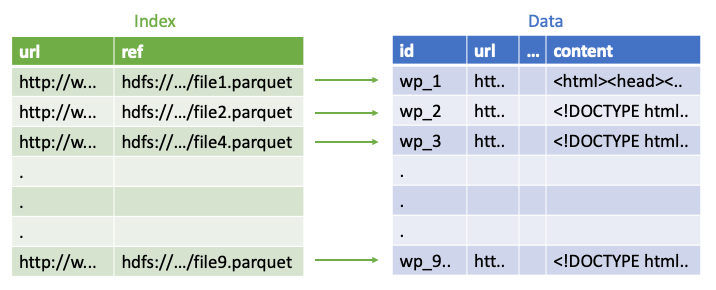
Поскольку предложенные выше направления не соответствовали нашим требованиям, мы решили создать и открыть новую библиотеку индексирования - Dione. Основная идея заключается в том, что индекс представляет собой теневую таблицу исходных данных. Он содержит только ключевые столбцы и указатели на данные. Сохраняется в специальном формате, вдохновленном Авро и ведерками. На основе этого индекса библиотека предоставляет API для соединения, запроса и извлечения исходных данных в требуемых SLA.
Основные преимущества:
- Полагается только на Spark, Hive и HDFS. Никаких внешних сервисов.
- Полууправляемый - мы не изменяем, не дублируем и не перемещаем исходные данные.
- Поддерживает несколько индексов для одних и тех же данных.
- Индекс представлен как стандартная таблица Hive.
- Наш специальный формат Avro B-Tree поддерживает произвольную выборку одной строки в SLA за секунды.
Архитектура
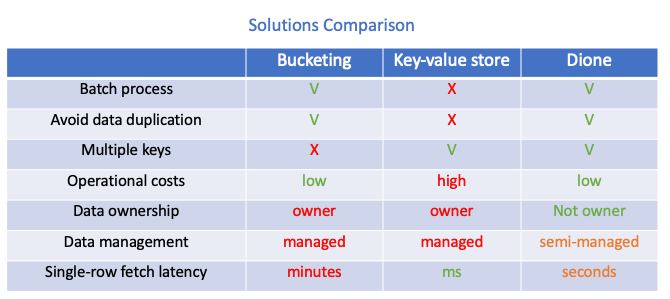
Диона решает две основные задачи:
- Учитывая указатель (строку в индексе), как быстро получить данные?
- Как сохранить индексную таблицу для выполнения требуемых SLA?
Таким образом, мы создали два основных компонента - Indexer и AvroBtreeFormat. Окончательное индексное решение состоит из взаимосвязей между этими компонентами, хотя в принципе каждый из них может стоять сам по себе.
Индексатор
Основная цель индексатора - решить задачу загрузки нескольких строк. Он имеет две основные функции:
Создание индекса. Он сканирует данные один раз и извлекает соответствующие метаданные. Индекс сохраняется как стандартная таблица Hive, доступная для запросов пользователей. В настоящее время мы поддерживаем индексирование данных в форматах Parquet, Avro и SequenceFile, и мы планируем поддерживать больше форматов в будущем.
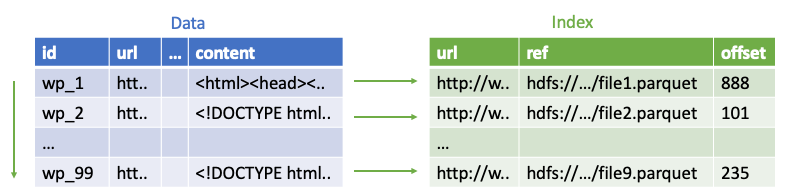
Использование индекса. Учитывая столбцы метаданных индекса, мы предоставляем API для быстрого получения исходных данных. Таким образом, пользователи могут загрузить индексную таблицу как стандартную таблицу Hive, отфильтровать ее с помощью стандартного соединения Hive / Spark с их выборкой данных и использовать API для чтения исходных данных для результирующего подмножества. Таким образом мы избегаем перетасовки и десериализации всех данных.
Формат файла Avro B-Tree
Индексатор решает задачу загрузки нескольких строк. Нам все еще нужно решить задачу выборки одной строки, поскольку использование Spark для сканирования всей индексной таблицы не соответствует нашему требуемому SLA. Для этого мы решили использовать еще одну степень свободы, которая у нас есть - формат хранения индекса. Вдохновленные Avro SortedKeyValueFile, сегментированием и традиционными системами индексирования баз данных, мы решили создать новый формат файлов - Avro B-Tree.
С технической точки зрения это просто файл Avro, совместимый с любым устройством чтения Avro. Однако мы добавили в каждую строку еще одно поле со ссылкой (не связанной с указателем индекса) на другую строку в том же файле. Кроме того, мы отсортировали строки в каждом файле в порядке B-Tree, поэтому, когда нам нужно выполнить произвольный поиск и выборку по определенному ключу, мы минимизируем количество переходов при чтении файла.

Чтобы понять, как мы используем этот формат файла Avro B-Tree в нашей системе индексирования, давайте взглянем на индекс, созданный индексатором. Данные индекса сохраняются в виде теневой таблицы исходной таблицы данных. Это файловая структура:
- Папки - например, каждая папка содержит данные с определенной даты (стандартное разбиение).
- Файлы - каждый файл содержит строки с одним и тем же ключевым хеш-модулем (например, с сегментацией).
- Формат файла - строки в файле сохраняются в виде B-Tree.
Когда пользователь запускает запрос API однорядной выборки, мы можем перейти прямо к запрошенной папке (по заданной дате запроса), затем прямо к нужному файлу по хешу ключа и, наконец, пройти через файл в порядке B-Tree, пока мы не найдем запрошенный ключ. Этот процесс занимает около одной секунды и соответствует нашему обязательному соглашению об уровне обслуживания.
Преимущества решения Avro B-Tree:
- Совместим со всеми ридерами Avro.
- Avro имеет хорошую поддержку произвольного доступа для чтения из определенного смещения файла.
- B-Tree минимизирует количество переходов при поиске по индексу.
- Включает прямой поиск в файле до тех пор, пока мы не найдем нужный ключ.
- Avro сохраняет данные в блоках, поэтому мы установили размер каждого блока равным размеру узла нашего B-дерева.
Spark API
Библиотеки Indexer и Avro B-Tree File Format являются независимыми пакетами и полагаются только на HDFS. Пользователи могут сохранить любую таблицу в формате Avro B-Tree, чтобы она была доступна как для пакетной аналитики с помощью Spark, так и для выборки по одной строке. В нашем полном решении для индексирования мы используем оба пакета. Для упрощения взаимодействия с пользователем Spark мы добавили высокоуровневый API Spark для создания и использования индекса. API доступен на Scala и Python.
Примеры кода владельца индекса
Определите индекс для таблицы `crawl_data` (выполнить один раз):
Отсканируйте таблицу данных и обновите индекс (запустить при обновлении таблицы данных):
Примеры кода клиента индекса
Многорядная загрузка:
Однострочная выборка:
Резюме
Напомним, мы создали Dione, библиотеку индексирования Spark, чтобы пользователи могли использовать свои данные пакетной аналитики для решения более интерактивных задач, таких как загрузка нескольких строк и выборка одной строки со значительно улучшенными SLA. Мы открыли исходный код этой библиотеки, чтобы поделиться этой функциональностью с сообществом и получить отзывы.
У нас уже есть много открытых проблем с интересными функциями и направлениями, которые мы можем добавить к основным функциям, включая оптимизацию соединений, лучшую интеграцию с оптимизатором Spark, возможности загрузки «машины времени» и многое другое.
Мы приглашаем вас попробовать и интересно услышать ваши мысли. Не стесняйтесь открывать проблемы и вносить свой код.