
Это продолжение статьи о системах контекстных рекомендаций. В предыдущем посте мы обсудили теорию различных подходов к рекомендации песен для плейлиста. Этот пост посвящен представлению очистки и исследовательского анализа данных, выполненному на основе данных, реализации ранее обсуждавшихся подходов и сравнению производительности по показателям оценки.
Обработка и очистка данных
Датасет, предоставленный на конкурс, насчитывает более 2 миллионов уникальных треков, 1 миллион плейлистов[4]. Из-за такого гигантского размера данных Spotify разделил набор данных на 100 различных частей в виде файлов json. Даже в этом случае последовательная обработка таких огромных данных для Macbook Pro является довольно сложной задачей. Принимая во внимание вычислительные ограничения, я выбрал 4000 плейлистов из 1 миллиона уникальных плейлистов. Эти 4000 плейлистов представляют собой небольшую часть 1 миллиона плейлистов, которые имеют несколько широких категорий. На рис. 1 мы видим, что выборочное распределение данных по основным категориям плейлистов очень похоже на исходные данные.

Более того, прогнозирование вероятности присутствия песни в плейлисте совершенно неэффективно с вычислительной точки зрения, поскольку уникальных треков более 2 миллионов. Если бы нам пришлось создать большую матрицу из 2 миллионов уникальных треков и 1 миллиона плейлистов, это была бы гигантская разреженная матрица, полная нулей, поскольку средняя длина плейлистов составляет 200 треков. 200 из 2 миллионов — это 0,0001% данных для каждого плейлиста в матрице. Это очень разреженное и вычислительно неэффективное представление. Вместо этого мы должны предсказать вероятность появления исполнителя в плейлисте. Почему художники? Потому что обычно один исполнитель ассоциируется только с одним музыкальным жанром. Итак, если плейлист посвящен определенному жанру или настроению, то он может быть представлен в виде коллекции исполнителей, а не треков. Я объединяю уникальные треки в большие группы исполнителей, чтобы уменьшить разреженность. Кластеризация по исполнителям изменила динамику, но мой Macbook Pro по-прежнему не мог выделить память для матрицы 22000 (Исполнители) x 4000 (списки воспроизведения).

Чтобы создать локальную выборочную модель, я принял более строгие меры по удалению разреженных данных из матрицы. Зная количество уникальных треков на каждого исполнителя, я могу оценить вероятность появления исполнителя в плейлисте. Артисты с очень небольшим количеством уникальных треков являются новичками на платформе, и публике требуется время, чтобы узнать исполнителя. Исполнителей отбирают в плейлист на основе их популярности, которая прямо пропорциональна количеству треков (за исключением нескольких вундеркиндов). Я исходю из того, что исполнители с большим количеством треков имеют высокую вероятность попасть в плейлист. Логично создать запас для уменьшения данных. Используя критерий наличия более двух песен на исполнителя, мы можем отфильтровать «непопулярных» исполнителей. Таким образом, я многим жертвую точностью модели, потому что отвергаю большую часть прогнозируемой совокупности.

Разведочный анализ данных и разработка функций
Это жизненно важная часть любого исследования, в ходе которого данные изучаются для построения функций, которые могут быть актуальны на основе определенных гипотез. После того как мы обработали данные для моделирования, нам нужно построить гипотезы, которые необходимо доказать с помощью прогнозного моделирования. Здесь нам предоставляются данные плейлистов и треков, присутствующих в этих плейлистах, с метаданными — названием трека, позицией трека, именем исполнителя, названием альбома, продолжительностью песни. Чтобы смоделировать релевантность трека для плейлиста, я выдвинул гипотезу о том, что важную роль будут играть исторические закономерности треков. Следовательно, я создаю следующие функции для ранжирования предлагаемых треков в плейлисте:
- Сходство плейлиста с предыдущими плейлистами треков. Эта функция пытается уловить взаимосвязь между текущим плейлистом и историческими плейлистами трека. Используя BERT Transformer, я генерирую внедрения для всех списков воспроизведения, присутствующих в данных. Эти внедрения представляют собой числовые представления названий списков воспроизведения. Я использую косинусное сходство для оценки семантического расстояния/сходства между названиями плейлистов в векторном пространстве.
- Появилось раньше: это функция частоты, позволяющая фиксировать появление трека в том же плейлисте ранее. Это показывает актуальность песни для конкретного плейлиста. Например, если песни Майлза Дэвиса чаще встречаются в плейлисте «Джаз», чем в плейлисте «Вечеринка», это означает, что песни Майлза Дэвиса больше подходят для плейлиста «Джаз».
- Позиционные характеристики (среднее, максимальное, минимальное). Эта функция фиксирует исторические позиции трека в похожих плейлистах. Это помогает модели определить диапазон релевантности трека в списке воспроизведения. Если минимальная и максимальная позиция песни Дрейка равна 3,6. Это означает, что Дрейк всегда находится в первых шести песнях плейлиста. Эта гипотеза отражает прямую связь с релевантностью.
- Количество уникальных позиций. Эта функция отражает популярность трека/исполнителя. Если трек появился во многих плейлистах, это означает, что трек очень популярен и имеет высокую вероятность быть добавленным в плейлист.
Предлагаемые подходы к рекомендации артистов
Предложение по контекстуальному сходству
Прежде чем перейти к математическим расчетам и декомпозиции матриц, я выдвинул гипотезу об объяснимом рекомендательном подходе к решению этой проблемы. Вместо использования совместной фильтрации в качестве общего метода нам следует сократить выбор, используя встраивание слов. Это означает, что для каждого обучающего плейлиста конвейер предварительно вычисляет встраивание слов с помощью BERT. Используя внедрения BERT, мы можем вычислить косинусное сходство между двумя списками воспроизведения. Это даст оценку K похожих плейлистов. Это также называется «ленивым обучением» [5].
Используя K соседних плейлистов, мы можем понять, какие исполнители будут присутствовать в этих похожих плейлистах. Исходя из этой гипотезы, я могу использовать исполнителей S из похожих плейлистов, чтобы предлагать новые песни в плейлист. В случае, если в плейлисте нет названия и в нем всего несколько песен, я прибегаю к использованию уже имеющихся исполнителей для оценки похожих исполнителей. Я использую уже существующих исполнителей, чтобы отфильтровать плейлисты, в которых есть эти исполнители. Используя отфильтрованные плейлисты, этот метод может предлагать выбранных исполнителей/песни в новый плейлист. Этот подход предполагает настройку двух разных параметров: K (Соседи) и S (Исполнитель). Увеличение этих параметров обеспечит большую генерализацию и лучшую запоминание, но требует больше времени на прогнозирование. Принимая во внимание, что уменьшение этих параметров уменьшит время вычислений, но также снизит производительность. Этот алгоритм работает быстрее, когда использует меньший объем данных.

Архитектура матричной факторизации
Теперь, когда мы реализовали интуитивный подход, пришло время перейти к математическим моделям, где мы используем методы обобщения для создания модели матричной декомпозиции [14]. Матричная факторизация — это наиболее распространенная форма совместной фильтрации, при которой мы извлекаем две скрытые матрицы из матрицы пользовательских элементов. Чтобы реализовать это на Python, я использовал библиотеку сюрприз [10]. Я подгоняю модель SVD (разложение сингулярных значений) к матрице элементов художника x, чтобы извлечь скрытые матрицы. Используя библиотеку тонкой настройки Hyper-opt, оптимальное количество скрытых факторов для матрицы было спрогнозировано равным 20. Для прогнозирования нам нужно создать массив новых плейлистов с тем же количеством исполнителей, что и для обучающих данных. Используя этот массив, мы прогнозируем вероятность присутствия исполнителя в плейлисте.
Простая архитектура VAE
Чтобы сравнить и сопоставить производительность Contextual-CVAE, я также принимаю во внимание простую архитектуру VAE [9], которая оценивает распределение скрытого вектора из обучающей матрицы. Для построения архитектуры VAE я использовал PyTorch благодаря его определениям объектно-ориентированного программирования и легко оптимизируемым свойствам. Кроме того, в PyTorch только что добавлена поддержка использования графического процессора на Macbook Pro для обучения моделей. Это сокращает время обучения моделей на 50%. Поскольку мы пытаемся построить очень простую модель, я использовал только 4 линейных уровня кодера и декодера для архитектуры VAE [9]. Всего за 50 эпох модель смогла сойтись в матрице «исполнитель x плейлист».
Архитектура VAE очень похожа на матричную факторизацию, когда дело касается прогнозов. Он предсказывает вероятность присутствия исполнителя в плейлисте и, используя пороговые значения, мы должны определить идеальный баланс между точностью и отзывом.
Контекстная архитектура CVAE
Контекстная архитектура CVAE основана на условно-вариационном автокодировщике. CVAE — это автокодировщик, снабженный либо одним вектором горячего кодирования, либо дополнительной информацией, относящейся к элементу/пользователю[20]. Он введен для того, чтобы помочь автокодировщикам генерировать лучшие скрытые представления. Обусловливание рассматривается как ограничение, и реконструкция должна это учитывать[20]. Это означает, что, как правило, ожидаемый результат представляет собой отфильтрованную версию входных данных, из которой отбрасываются элементы, не удовлетворяющие ограничению.

Хотя контекстная архитектура использует встраивания BERT для контекста, предсказания не полностью зависят от него. На диаграмме производительности (рис. 9) мы видим, что даже при удалении контекстной информации эта архитектура сохраняет производительность.

Чтобы реализовать трюк с перепараметризацией, я определяю случайный вектор и умножаю его на стандартное отклонение. Этот случайный вектор не оптимизирован и предназначен для введения случайного распределения скрытых параметров. Для справедливого сравнения VAE и контекстного CVAE я сохранил одинаковое количество параметров и скрытых слоев. Количество эпох, используемых для обучения модели, также остается прежним. Это обеспечит справедливое сравнение яблок с яблоками.
Рейтинг с помощью LambdaMART
LambdaMART[3] — это ансамблевая модель, которая использует деревья повышения градиента с заменой пар для прогнозирования оценки релевантности документа для запроса. Это модель plug-n-predict, в которой вы используете функции и влияние ранжирования, чтобы найти шаблон ранжирования. Влияние рейтинга DCG называется Lambda. Для каждого документа, полученного по запросу, эта модель вычисляет лямбда-выражение путем замены пар. Он определяет пару документов и меняет их местами для расчета положительного/отрицательного влияния на метрику DCG (метрику оценки для ранжирования) [3]. После того как модель вычислила лямбда-выражение, она использует такие функции моделирования, как история, частота появления документа и т. д., чтобы спрогнозировать оценку релевантности для каждого документа. Чтобы предсказать релевантность, он использует повышение градиента из-за его надежности и техники обобщения. Дуг Тернулл написал отличную статью, в которой подробно объясняет LambdaMART с помощью кода [21].
Чтобы реализовать LambdaMART в Python, я использовал библиотеку Lightgbm. Мы просто определяем целевой параметр как лямбдаранк. Обучение модели заняло менее 5 минут. Я также использую вероятности/релевантность прогнозирования из моделей совместной фильтрации в качестве входных данных для модели.
Выводы из обучения моделей и прогнозов исполнителей
Сравнивая кривую PR VAE (рис. 6) и CVAE (рис. 7), мы не можем наблюдать существенной разницы в точности, однако отзыв CVAE выше при более низких порогах. Когда мы увеличиваем порог вероятности, наблюдается огромный провал в отзыве, а также в показателе F1 (рис. 7). Вероятности прогнозирования ограничены до 0,8, поэтому на графике мы видим 0 баллов точности, отзыва и F1. Потеря контекстного CVAE происходит более плавно по сравнению с VAE. На кривой точности имеется седловая точка на уровне 11 %, поскольку мы удалили из данных «непопулярных» исполнителей в целях экономии памяти. Следовательно, модель имеет ограниченное пространство художника для прогнозирования из-за обработки данных.


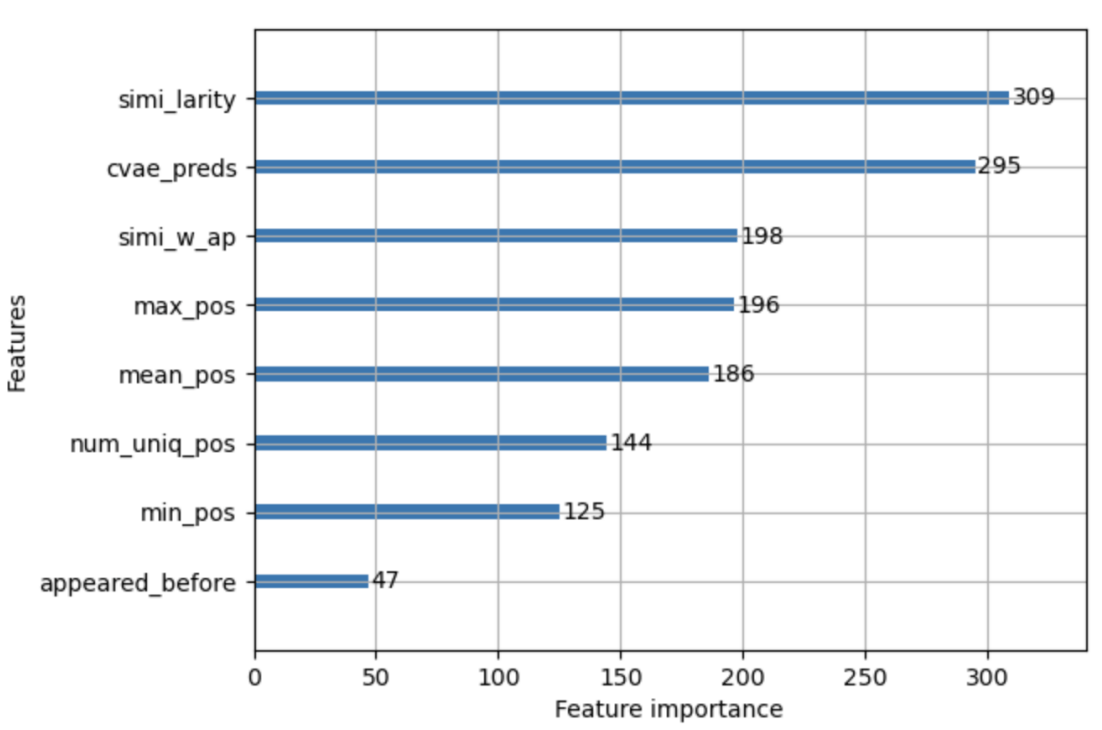
График важности функций (рис. 8) показывает, как каждая функция влияет на прогнозируемый рейтинг треков в списке воспроизведения. «simi_larity» и «cvae preds» являются наиболее важными функциями LambdaMART для прогнозирования рейтинга. «simi_larity» — это косинусное сходство между плейлистами наиболее часто появлявшихся треков в прошлом и текущим плейлистом. Эта функция позволяет модели оценить порог сходства между историей треков и текущим плейлистом. «cvae preds» — это результат контекстной архитектуры, которая прогнозирует вероятность присутствия исполнителя в данном плейлисте. Функция «simi_w_ap» — это взвешенное косинусное сходство между историческими плейлистами треков и текущим плейлистом. Вес определяется количеством раз, когда трек появлялся в любом списке воспроизведения. Модель ранжирования подтверждает гипотезы, выдвинутые на этапе исследования, путем придания важности правильным характеристикам данных.
Метрики оценки механизма рекомендаций
Оценка механизмов рекомендаций очень похожа на оценку алгоритма регрессии или классификации. Мы рассчитываем, насколько близка прогнозируемая релевантность к фактической релевантности или насколько хорошо модель способна предсказать фактический рейтинг песни. Я разделил эту модель на два разных этапа, где первая модель предсказывает вероятность присутствия исполнителя в плейлисте. А вторая модель прогнозирует рейтинг треков выбранных исполнителей. Чтобы разработать набор тестов для этого исследования, я применил тот же подход, что и конкуренты Spotify [4]. Плейлисты тестового набора будут состоять всего из 5–10 исходных треков. Некоторые плейлисты не содержат названий плейлистов и содержат только начальные треки. Модель спрогнозирует 500 песен для плейлиста, а для измерения производительности будет использоваться показатель NDCG. Чтобы обеспечить справедливое сравнение нескольких алгоритмов, я случайным образом выбрал 1000 плейлистов из пропущенных данных. Мы наблюдаем разрыв в производительности контекстных алгоритмов на тестовом наборе, когда имя плейлиста отсутствует и присутствует всего 5–10 начальных песен.
Правильная идентификация исполнителя/трека
Чтобы оценить архитектуру первого этапа рекомендации лучшего исполнителя с помощью совместной фильтрации, я рассчитываю правильное количество исполнителей, угаданных алгоритмом, из реальных исполнителей в плейлисте. Это также называется точностью. Из рисунка 9 я вижу, что когда я использую контекстную информацию в алгоритме рекомендаций, количество художников, идентифицированных моделью, значительно выше. Матричная факторизация и Vanilla VAE способны идентифицировать только половину совокупности предположений о контекстуальном сходстве.

Однако мы видим снижение эффективности предложений по контекстуальному сходству, когда модели не указано название плейлиста. Контекстный CVAE демонстрирует признаки высокой производительности, поскольку отсутствие имени списка воспроизведения практически не влияет на его производительность. Если мы посмотрим на точность с точки зрения треков, контекстные алгоритмы показывают огромный прирост производительности. В то время как матричная факторизация и VAE с трудом могут предсказать хотя бы один правильный трек для лучших плейлистов в тестовом наборе.

Оценка DCG и карта
Дисконтированный совокупный выигрыш используется для оценки качества рейтинга в поисковых системах[13]. Он широко используется, поскольку учитывает релевантность, а также положение элемента для измерения рейтинга. DCG измеряет, насколько хорошо алгоритм ранжирования размещает наиболее релевантные элементы в верхней части списка и насколько релевантность снижается вниз по списку. Оценка DCG не имеет ограничений и находится в диапазоне положительных целых чисел. Однако, чтобы обеспечить более количественную оценку, рассчитывается нормализованный показатель DCG. Это называется NDCG Score. Он рассчитывается путем деления прогнозируемого показателя DCG на идеальный показатель DCG для этого списка [13]. Оценка NDCG «1» — это идеальная оценка для метода ранжирования. Средняя средняя точность — это средняя точность, рассчитываемая для каждого запроса и вычисляющая среднее значение по всем запросам. Он показывает, насколько хорошо модель способна угадать соответствующие документы в определенной позиции в списке. Глядя на показатели производительности, мы видим, что существует очень незначительная разница в производительности в метрике NDCG алгоритмов контекстного сходства, однако Contextual CVAE имеет самый высокий показатель теста NDCG. А по метрике MAP «Предложение контекстного сходства» работает в 10 раз лучше, чем любой другой алгоритм. Это также можно наблюдать по уникальным трекам, идентифицированным с помощью контекстного сходства на рисунке 10. Контекстная информация, предоставляемая из внедрений BERT, значительно улучшает идентификацию треков в процессе рекомендаций.

Время исполнения
Все вышеупомянутые архитектуры имеют хорошую производительность с точки зрения NDCG Score, но являются ли они масштабируемыми? Время выполнения является важным фактором, когда дело доходит до развертывания архитектуры мобильного приложения. Время прогнозирования играет жизненно важную роль в выборе правильного алгоритма: предложения меняются при каждом новом атрибуте, добавляемом в данные. Например, пользователь только что купил товар, и рекомендуемое системное время, чтобы показать пользователю новую рекомендацию на основе недавней покупки, повлияет на взаимодействие с пользователем. Если рекомендации медленные, пользователь может не покупать больше товаров или не будет потреблять больше контента с платформы.

На рисунке 11 контекстный CVAE показывает более быстрое время обучения, а также время прогнозирования, чем любой другой механизм рекомендаций. Предложение контекстного сходства имеет самое короткое время обучения, поскольку оно лениво обучается [5]. Время обучения — это время создания вложений для всех заголовков обучающего плейлиста. Однако время прогнозирования для плейлистов без названий плейлистов является самым высоким из-за процесса фильтрации. Масштабирование этого процесса для очень больших запасов — неэффективный процесс. Однако Contextual CVAE обучается быстрее и демонстрирует высокую производительность в обоих процессах.
Заключение
Я сравнил различную архитектуру механизма рекомендаций и рейтинг выборочных данных из конкурса автоматического продолжения плейлиста [4]. Я выдвинул гипотезу о том, что добавление контекстной информации в механизмы рекомендаций обеспечивает повышение производительности. Таблица 1 показывает, что контекстная информация приводит к созданию надежной и более точной системы рекомендаций. Я провел t-тест для прогнозов предположений контекстного сходства и матричной факторизации, и они оказались значительно лучше. Контекстная информация действует как дополнительный параметр модели и вводит больше информации для компенсации разреженности в матрице «Пользователь-элемент». Это серьезная проблема, с которой сталкиваются все системы рекомендаций. В этом посте представлено несколько гипотез, призванных смягчить влияние скудных данных на рекомендации.
- Создавайте кластеры пользователей. Системы рекомендаций могут столкнуться с проблемами обобщения, если в качестве основного объекта используются пользователи. Вместо этого следует создавать меньшие кластеры пользователей, чтобы уменьшить разреженность данных. Это создаст новые отношения между определенными клиентами и устранит шум в данных. Большинство социальных платформ получают трафик только от почти 50% общей пользовательской базы веб-сайта [15]. Это показывает, что если механизм рекомендаций учитывает каждого пользователя, он в конечном итоге будет соответствовать очень разреженным и зашумленным данным.
- Использовать контекстную информацию. Если весь механизм рекомендаций основывается только на поведении пользователя, отношения между двумя разными элементами игнорируются. Использование контекстной информации повышает производительность, а также облегчает обобщение данных. Контекстная информация может быть в форме статических переменных элементов или вектора BERT для добавления лингвистической информации в модель. Векторы BERT в CVAE никогда раньше не использовались, и я с нетерпением жду возможности проверить эту гипотезу на большем количестве наборов данных и представить результаты.
Рекомендации
[1] Ники Пармар, Якоб Ушкорейт, Лайон Джонс, Эйдан Н. Гомес, Лукаш Кайзер, Илья Полосухин, Ашиш Васвани, Ноам Шазир. Внимание – это все, что вам нужно. В книге «Вычисления и язык», стр. 15, 2017 г.
[2] Берт Арнрих Бьерн Пфицнер. Dpd-fvae: генерация синтетических данных с использованием объединенных вариационных автокодировщиков с дифференциально-частным декодером. В области машинного обучения, 2022 г.
[3] Си Джей Берджес. От раннета до лямбдаранка и лямбдамарта: обзор. В журнале «Поиск информации о исследованиях Microsoft», стр. 82, 2010 г.
[4] М. Шедл К. В. Чен, П. Ламере и Х. Замани. Задача Recsys 2018: автоматическое продолжение музыкального плейлиста. В RecSys '18: материалы 12-й конференции ACM по рекомендательным системам, 2018 г.
[5] Ю. Юнцюань Д.А. Аденийи, З. Вэй. Автоматизированная система сбора данных об использовании Интернета и система рекомендаций с использованием метода классификации k-ближайшего соседа (knn). В области прикладных вычислений и информатики, 2016.
[6] Понвон Су Дэрён Ким. Улучшение возможностей совместной фильтрации: гибкие механизмы пропускания априорных значений. На тринадцатой конференции ACM по рекомендательным системам (RecSys '19), стр. 5, 2019 г.
[7] Макс Веллинг Дидерик П. Кингма. Введение в вариационные автоэнкодеры. В книге «Основы и тенденции машинного обучения», страницы 307–392, 2019 г.
[8] Ламере П. К. В. Чен. Х. Замани, М. Шедль. Анализ подходов, использованных в проекте ACM Recsys Challenge 2018 для автоматического продолжения списка воспроизведения музыки. В разделе «Автоматическое продолжение списка воспроизведения музыки», стр. 20, 2018 г.
[9] Салахутдинов Р. Р. Хинтон Г. Э. Уменьшение размерности данных с помощью нейронных сетей. В журнале Science, стр. 504–507, 2006 г. [10] Николас Хуг. Набор Python для рекомендательных систем. В Рекомендательных системах, 2015.
[10] Николас Хуг. Набор Python для рекомендательных систем. В Рекомендательных системах, 2015.
[11] Кентон Ли, Кристина Тутанова, Джейкоб Девлин, Минг-Вэй Чанг. Берт: Предварительная подготовка глубоких двунаправленных преобразователей для понимания языка. В области вычислений и языка, 2019.
[12] Стэн Лэннинг Джеймс Беннетт. Премия Нетфликса. В наборе данных Netflix Prize, 2007. [13] Кекалайнен Дж. Ярвелин, К. Оценка IR-методов на основе совокупного выигрыша. В ¨ Транзакции ACM в информационных системах (TOIS), страницы 422–446, 2002 г.
[14] Белл Р. Волинский С. Корен, Ю. Методы матричной факторизации для рекомендательных систем. В IEEE Computer Society, страницы 30–37, 2009 г.
[15] Катерина Ева Матса Мейсон Уокер. Потребление новостей в социальных сетях в 2021 году. В Pew Research Center, 2021 год.
[16] Пол Резник и Хэл Р. Вариан. Рекомендательные системы. Сообщения ACM, 40(3):56–58, 1997.
[17] Датта М. Рой, Д. Систематический обзор и исследовательский взгляд на рекомендательные системы. В сфере больших данных, 2022 год.
[18] Бадрул Сарвар, Джордж Карипис, Джозеф Констан и Джон Ридл. Алгоритмы рекомендаций по совместной фильтрации на основе элементов. В материалах 10-й Международной конференции по Всемирной паутине, страницы 285–295, 2001 г.