КОДЕКС
Легко создавайте анимированные гонки на гистограммах с помощью Python
Практическое руководство по созданию гистограммы с помощью Python и мощной библиотеки bar_chart_race из набора данных реальных случаев COVID-19
Визуализация данных - одна из сильных сторон Python. Создавать красочные и содержательные диаграммы из набора данных с помощью Python всегда весело, особенно когда он анимирован! да. Вы правильно прочитали! Сегодня я собираюсь показать вам, как создать движущуюся линейчатую диаграмму гонок с помощью Python и библиотеки bar-chart-race.
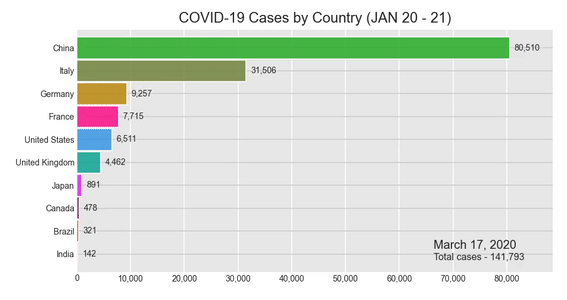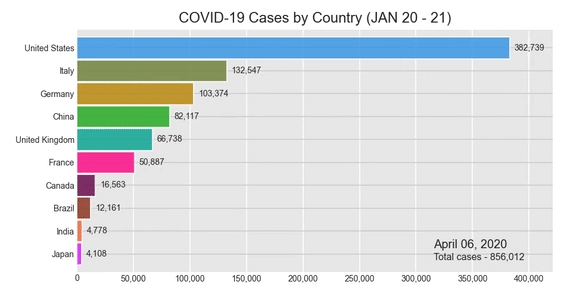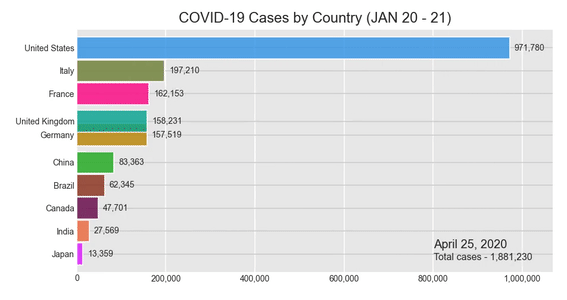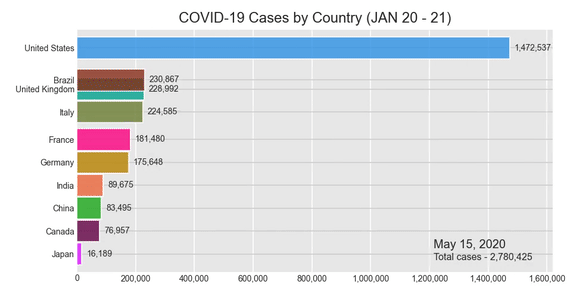
Вступление
Практики Python согласны с тем, что визуализация данных с помощью Python эффективна и увлекательна. Благодаря мощным библиотекам, таким как pandas, Matplotlib и s eaborn, наши возможности обработки и визуализации данных с помощью Python являются надежными. Цветные диаграммы отображают значимую информацию из наборов данных, которые мы хотим понять.
Есть еще одна мощная библиотека, которая может вывести нашу визуализацию на новый уровень! Представляем bar-chart-race, библиотеку, которая оживит вашу гистограмму и заставит столбцы расти и перемещаться друг за другом в красочной гонке.
Визуализация набора данных случая COVID-19
Помимо художественной значимости, визуализация данных может быть очень информативной и действенной, особенно при отражении текущих событий в мире.
В тот день, когда я опубликовал эту статью, все мы сталкиваемся с ситуацией с COVID-19 уже больше года. Это все еще продолжается по всему миру. Сейчас это уже не новость, но она по-прежнему несет в себе нежелательные последствия, с которыми мы должны сталкиваться ежедневно.
Правительства (предположительно) изо всех сил пытаются справиться с ситуацией и оптимизировать свою экономику в болезненно стесняющих обстоятельствах. Чтобы отследить, насколько эффективно страна справляется с этой ситуацией, можно визуализировать, насколько быстро вирус распространяется в этой стране по сравнению с его аналогами.
Чтобы сделать эту историю немного более интересной, мы рассмотрим набор данных о реальных случаях COVID-19 и сделаем из него гистограмму гонок. Мы визуализируем, насколько быстро вирус распространяется на территории ведущих экономик мира, с помощью гистограммы. Слово быстро подразумевает, что мы собираемся иметь дело с набором данных временных рядов, и время покажет интересное поведение на нашей диаграмме, как вы увидите, когда мы закончим его создавать.
Примечание I. Эта статья основана на Python 3.9.1, Jupyter Notebook 6.1.6, на 64-разрядном компьютере Windows 10 .
Практическая часть
Сделайте четкую цель
Прежде всего, нам нужно поставить четкую цель для нашего проекта. Это поможет нам собрать из набора данных только то, что нам действительно нужно, и завершить проект (надеюсь) быстрее, чем когда мы бесцельно исследуем и экспериментируем с данными.
С самого начала цель уже довольно ясна: мы создадим гистограмму гонок, чтобы визуализировать распространение вируса COVID-19 в некоторых ведущих странах мира.
Остается вопрос: в каких странах и как долго мы хотим визуализировать данные?
Мой выбор был произвольным. В этом случае я решил, что создам гистограмму забега случаев COVID-19, зарегистрированных в 10 ведущих экономиках мира. Список этих стран я получил на investopedia.com. Затем я решил, что временные рамки будут составлять примерно год, начиная с первого дня любых зарегистрированных данных в любой из этих стран в январе 2020 года до конца января 2021 года.
Сводка цели:
- Создание гистограммы для визуализации случаев COVID-19 в 10 ведущих странах мира
- Срок - 1 год (с января 2020 года по конец января 2021 года).
Все готово! Мы в порядке!
Исследование и изменение данных
Приготовься! Мы собираемся загрузить набор данных о реальных случаях COVID-19 по этой ссылке: https://ourworldindata.org/covid.
Вы также можете скачать набор данных и все коды Python, используемые в этом проекте, здесь: https://github.com/pkx8326/COVID-19-Race-Bar-Chart.git
Поместив файл .csv в ту же папку, в которой запущен Python, мы можем приступить к работе с клавиатурой.
Импорт библиотек:
Во-первых, нам нужно импортировать несколько библиотек, чтобы этот проект заработал:
import pandas as pd
import matplotlib.pyplot as plt #Not necessary
plt.style.use("seaborn-whitegrid") #Not necessary
import bar_chart_race as bcr
Pandas незаменим, потому что нам нужно будет придать нашим данным желаемую форму, прежде чем создавать окончательную гистограмму гонок.
Еще одна незаменимая библиотека в этом проекте - bar_chart_race. Мы будем творить чудеса с этой библиотекой. Нет необходимости импортировать matplotllib, но в этом случае я хочу, чтобы Python рисовал диаграмму на основе способности matplotlib, и я также хочу использовать seaborn-whitegrid на карте. Однако это мое личное предпочтение.
Создание фрейма данных:
Теперь, когда мы импортировали все необходимые библиотеки, перейдем к загрузке наших данных в фрейм данных и их изучению:
df = pd.read_csv("covid-data.csv")
df

В этом проекте я назвал файл covid-data.csv. Изначально мы видим, что данные содержат 71 061 строку и 59 столбцов. Я использовал df, а не df.head (), потому что я хотел видеть как начало, так и хвост этого фрейма данных. Судя по всему, у нас много стран, начинающихся в алфавитном порядке от Афганистан до Зимбабве. Но есть несколько строк с Афганистаном и несколько строк с Зимбабве. Все остальные страны между этими двумя должны быть одинаковыми, распределенными по нескольким строкам.
Оглядываясь назад на нашу сводку целей, единственная информация, которая нам нужна, - это название страны, даты с января 2020 года по январь 2021 года и количество случаев в каждой стране, в которые выполняются входы каждый день. Давайте сначала удалим всю остальную ненужную информацию и оставим только то, что нам нужно:
df = df[["location", "date", "new_cases"]] df

Большой! Осталось обработать только 3 столбца (пока).
Присмотревшись к столбцу дата, мы видим, что каждый новый день начинается с новой строки, содержащей всю остальную информацию, включая название страны. По этой причине названия стран в столбце местоположение повторяются.
Мы уже можем представить, что таблица с последовательными датами в качестве индекса и столбцы с названиями стран, заполненными номерами наблюдений, будут полезны для создания нашей гонки на гистограмме.
У нас уже есть узкий (иногда сложенный или высокий) фрейм данных. Этот тип фрейма данных содержит столбец с наивысшей степенью детализации. В данном случае это столбец new_cases с количеством ежедневных обращений. Остальные столбцы представляют собой столбцы контекста, содержащие контексты для значений, чтобы они были значимыми. Значения в столбцах контекста могут повторяться. В нашем случае это столбец местоположения, содержащий названия стран.
Сводка данных:
Очевидно, что мы не можем использовать этот тип фрейма данных для создания нашей гистограммы гонок. Давайте превратим наш фрейм данных во что-то более полезное с помощью функции pandas pivot:
df = df.pivot(index = "date", columns = "location", values = "new_cases").reset_index().rename_axis(None, axis=1) df
Я использовал функцию pivot, чтобы преобразовать наш фрейм данных в фрейм с последовательными датами в качестве столбца индекса и столбцы, содержащие названия стран, заполненные количеством наблюдений в качестве значений.
Хотя наша цель - создать фрейм данных с датами в качестве индекса, они мне пока не нужны, потому что я все еще хочу изменить формат даты, и мне нужен столбец date как обычный столбец. .
Цепочка .reset_index (). Rename_axis (None, axis = 1) сбросит индекс и удалит имя из столбца индекса.
Будьте готовы, в итоговом фрейме данных будет столько столбцов, сколько во всех странах в исходном фрейме данных:

В нашем новом фрейме данных 421 строка и 215 столбцов. Это означает, что исходный файл содержит информацию за 421 день регистрации данных для всех стран, а в этой таблице 215 стран. Нам не нужно столько дней и стран.
Из https://www.investopedia.com/insights/worlds-top-economies/ первые 10 ведущих экономик мира в 2020 г. - это США, Китай, Япония, Германия, Индия, Великобритания, Франция, Италия, Бразилия. , и Канада соответственно. Давайте оставим только эти 10 стран в нашем фрейме данных и отбросим все остальные:
df = df[["date", "United States", "China", "Japan", "Germany", "India", "United Kingdom", "France", "Italy", "Brazil", "Canada"]] df
Большой! Наш фрейм данных теперь намного меньше. После удаления всей информации по другим странам у нас остались только данные по первым 10 странам мира, которые могут уместиться во фреймворке 421 на 11.
Очистка данных:
Как мы видим, в заголовке нашего фрейма данных есть ячейки со значениями NaN (не числовыми). Эти ячейки начинаются 1 января 2020 г. (2020–01–01). Это означает, что ни одна страна из этих 10 не начала регистрировать данные первого января 2020 г. Мы не знаем точно, сколько NaN есть в каждой стране. Чем больше NaN, тем дольше мы должны ждать появления полосы в нашем конечном продукте.
Давайте разработаем стратегию, чтобы удалить как можно больше NaN из нашего фрейма данных. Само собой разумеется, что мы удалим NaN, не удаляя наши полезные значения регистра!
Во-первых, будет полезно узнать, кто первым начал регистрацию данных среди этих 10 стран. Мы удалим NaN до первого дня, когда первая страна начала регистрировать свои данные, а остальное оставим.
Чтобы узнать, кто первым начнет регистрацию данных, давайте посчитаем NaN каждой страны из первой строки фрейма данных:
import math
for i in df.columns[1:]:
j = 0
while math.isnan(df[i].iloc[j]):
j = j + 1
print(i, j)
United States 22
China 22
Japan 22
Germany 26
India 29
United Kingdom 30
France 23
Italy 30
Brazil 56
Canada 25
Вложенный цикл while в цикле for проверяет NaN в каждой строке каждой страны. Похоже, что США, Китай и Япония первыми начали регистрацию данных. Они тоже стартовали в тот же день.
Теперь мы знаем, что удалим NaN из всего этого фрейма данных с индекса 0 до 22:
for i in range(22):
df.drop(index = i, inplace = True)
df.head()

Теперь наш фрейм данных немного меньше. При более внимательном рассмотрении мы видим, что в США и Японии в первый день регистрации все еще было 0 случаев, в то время как в Китае уже было 95 случаев.
После удаления некоторых строк из заголовка нашего фрейма данных индекс больше не начинается с 0. Чтобы предотвратить возможную путаницу в будущем, давайте сбросим индекс фрейма данных, перезапустив его снова с 0:
df = df.reset_index() df.drop(columns = “index”, inplace = True) df.head()
Есть еще несколько строк, которые нам нужно удалить из нашего фрейма данных. Помните нашу цель? Последней датой в нашем фрейме данных должен быть конец января 2021 года (2021–01–31). Мы до сих пор не знаем, где это (какой индекс). Давайте узнаем об этом:
for i in df.index:
if df["date"].iloc[i] == "2021-01-31":
print(i)
374
Последний день наших данных записан с индексом № 374. Мы отбросим все строки, следующие за этим индексом:
for i in range(375, len(df.index), 1):
df.drop(index = i, inplace = True)
df
Мы немного уменьшили фреймворк с 421 на 11 до 375 на 11. Теперь мы стройные и здоровые! Но мы еще не там.
У нас все еще есть NaN, а тип данных нашего номера дела - float вместо int. Поскольку объект с плавающим типом требует большего выделения памяти. Это излишне отнимет у нас время обработки.
Давайте изменим все NaN на 0 и каждый номер случая на int:
df = df.fillna(0)
for i in df.columns[1:]:
df[i] = df[i].astype(int)
df

Мы действительно почти у цели! Есть еще пара вещей.
Посмотрите на столбец дата. Мне уже больно смотреть на формат даты. Я ненавижу этот формат. И поскольку мы собираемся отобразить дату изменения на нашем графике, я не могу с этим согласиться.
Вместо 2021–01–01 я хочу, чтобы это было 1 января 2021 года. На моем графике это будет выглядеть намного красивее (и значительнее).
В дате есть три элемента: год, номер месяца и день. Главное, что нам нужно изменить, - это месяц. Нам нужно изменить номер месяца на фактическое название месяца на английском языке. Я решил, что сначала нам нужно создать словарь, содержащий имена всех месяцев:
monthDict = {"01":"January", "02":"February", "03":"March", "04":"April", "05":"May", "06":"June", "07":"July", "08":"August","09":"September", "10":"October", "11":"November", "12":"December"}
Поскольку каждый элемент в дате разделен знаком «-», мы будем использовать метод string .split (), чтобы отделить каждый элемент друг от друга, поменять их позиции и заменить номер месяца на название месяца из нашего словаря.
Давайте протестируем эту стратегию с первой записью на дату (2020–01–23):
print(monthDict[df["date"].iloc[0].split("-")[1]], df["date"].iloc[0].split("-")[2]+",", df["date"].iloc[0].split("-")[0])
January 23, 2020
Большой! Функция печати дает нам желаемый формат даты. Мы должны преобразовать каждую запись даты в этот формат. Давайте создадим для этого функцию:
def correctDate(dateStr):
strList = dateStr.split("-")
dateFormat = str(monthDict[strList[1]]) + " " + str(strList[2]) + ", " + str(strList[0])
return dateFormat
Функция работает, меняя позиции исходных элементов даты и заменяя номер месяца названием месяца из словаря monthDict.
Давайте проверим эту функцию:
correctDate("2020-01-23")
'January 23, 2020'
Альт! Теперь применим эту функцию ко всем записям в столбце date с помощью лямбда-функции Python:
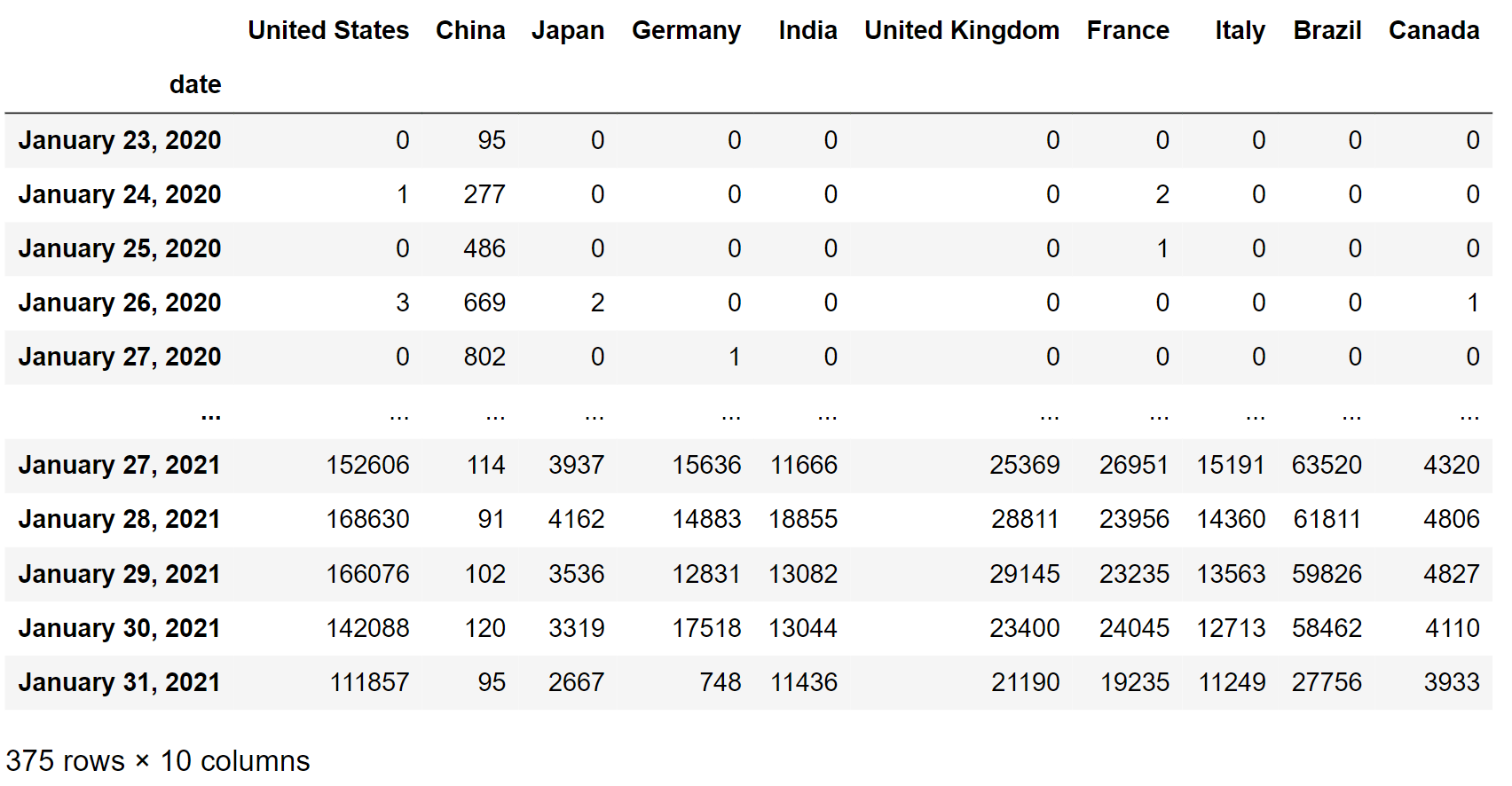
df["date"] = df["date"].apply(lambda x: correctDate(x)) df
Теперь последнее, что нам нужно сделать с этим фреймом данных перед созданием гонки на гистограмме, - это сделать столбец date столбцом индекса:
df.set_index("date", inplace = True)
df
Не забывайте, что в нашем фрейме данных есть ежедневные записи. На самом деле нам нужна совокупная сумма всех случаев для каждой страны. Кумулятивную сумму можно получить по следующему коду:
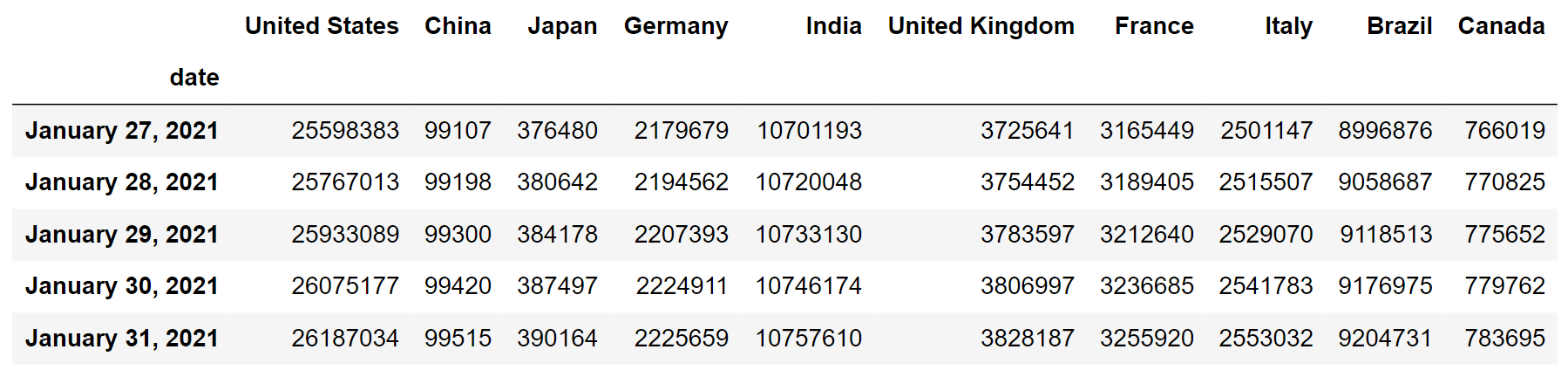
c_sumData = df.cumsum(axis = 0)
Я назначил новый фрейм данных c_sumData и установил его равным всей совокупной сумме наблюдений для каждой страны в нашем исходном фрейме данных. Параметр axis = 0 указывает, что суммирование происходит по строкам.
Давайте проверим хвост нашего нового фрейма данных, количество случаев должно быть огромным для каждой страны:
c_sumData.tail()
Создание гистограммы для случаев COVID-19
Теперь мы готовы вызвать нашу библиотеку рок-звезд и создать нашу диаграмму. Следуйте приведенному ниже коду, и в нашем блокноте Jupyter появится анимированная гистограмма. После запуска кода, в зависимости от вашей вычислительной мощности, вам, возможно, придется подождать несколько минут. Но результат, я гарантирую, того стоит.
Примечание II. Вы можете получать предупреждающие сообщения от Jupyter Notebook о настройках диаграммы. Вы можете игнорировать это.
Давайте создадим гонку на гистограмме !:
bcr.bar_chart_race(df = c_sumData, filename = None, period_summary_func = summary, period_label = {'x':.75, 'y': .1}, title = 'COVID-19 Cases by Country (JAN 20 - 21)')
Уведомление III. Вы можете получить сообщение об ошибке, утверждающее, что на вашем компьютере нет FFmpeg. Вы можете установить его с помощью ImageMagick, это бесплатно.
Результат:
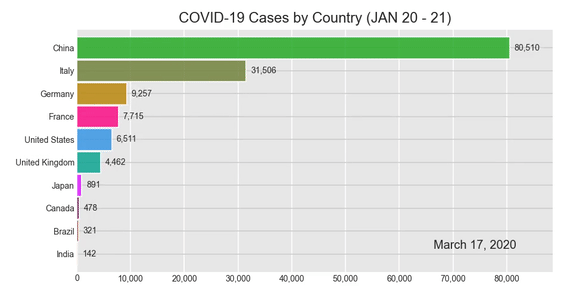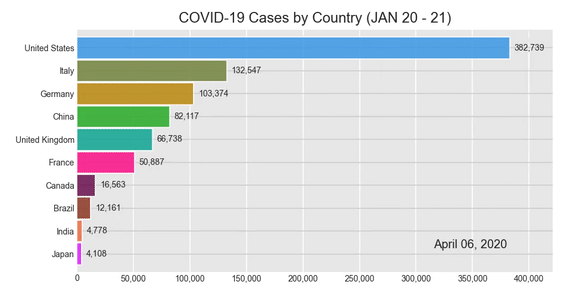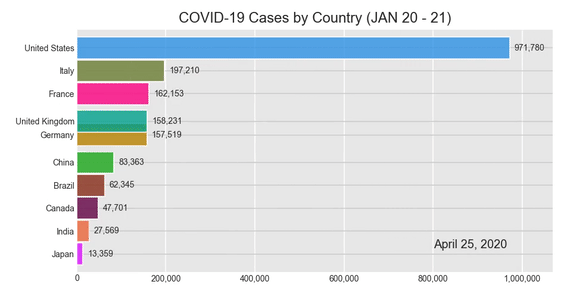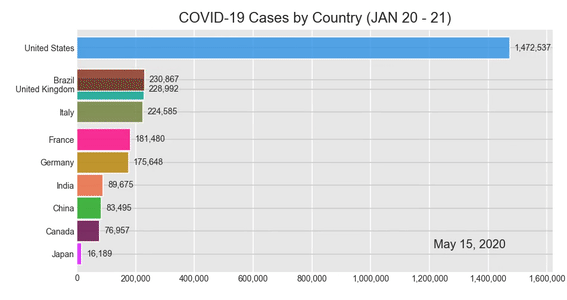
Несмотря на то, что в вашем Jupyter Notebook отображается гистограмма гонки, у вас будет возможность сохранить ее как видеофайл в формате .mp4. Попробуйте щелкнуть значок сохранения в правом нижнем углу диаграммы.
Согласно учебнику библиотеки гонок с гистограммами, если вам нужна дополнительная информация, например, если вы хотите, чтобы текущая сводка всех случаев отображалась под текущей датой, вы можете создать следующую функцию и использовать ее в качестве параметра внутри bar_chart_race () функция:
def summary(values, ranks):
total_cases = values.sum()
s = f"Total cases - {total_cases:,.0f}"
return {'x': .75, 'y': .05, 's': s, 'size': 8}
Теперь давайте снова применим функцию bar_chart_race () к нашим данным, на этот раз с помощью только что созданной функции summary ():
bcr.bar_chart_race(df = c_sumData, filename = None, period_summary_func = summary, period_label = {'x':.75, 'y': .1}, title = 'COVID-19 Cases by Country (JAN 20 - 21)')
Результат:
Теперь наш конечный продукт готов. Красиво, полезно и интересно, каким должно быть.
Заключение
Я показал вам, как преобразовать реальные данные о случаях COVID-19 в захватывающую гонку на гистограммах с помощью Python и библиотеки bar_chart_race ().
О чем нам говорит диаграмма?
Полученная гистограмма расы показывает нам, насколько быстро коронавирус распространяется в каждой стране в выбранный нами период времени, и этим все сказано. На самом деле это не отражает того, насколько эффективно правительство справляется с пандемией.
Полезное сообщение
Каждая страна с ее уникальным социальным и технологическим контекстом не может сравнивать свои показатели по смягчению кризиса с другими, просто глядя на то, насколько быстро вирус распространяется за определенный период времени. График может отражать эффективное вмешательство государства или возникновение слышимости, когда полоса значительно замедляется, но эта интерпретация все еще неоднозначна.
Однако создавать такую визуализацию всегда весело и полезно. Помимо рассмотрения случаев COVID-19, у этого типа диаграмм есть и другие приложения, такие как визуализация роста компаний в той же отрасли за выбранный период.
Благодаря библиотеке bar_chart_race код очень упрощен, а окончательная визуализация выглядит красивой и информативной. Однако большой частью остается подготовка, преобразование и очистка данных. Поэтому всегда полезно сначала поставить четкую цель и иметь представление о нашем готовом продукте, прежде чем погрузиться в какие-либо действия с данными. Тем не менее, мы всегда можем повеселиться с подготовкой данных.
Надеюсь, эта статья будет полезна вашим проектам визуализации.
До следующего раза, удачного кодирования!