
Эй, надеюсь, у тебя все хорошо. Итак, недавно я начал проходить курс глубокого обучения Fast.AI, где два блестящих человека — Джереми Ховард и Рэйчел Томас преподают глубокое обучение. Один очень опытный программист, а другой математик, так что может быть лучшая комбинация.
Обучение с Fast.AI
Интересная вещь в этом курсе заключается в том, что он использует нисходящий подход к обучению, то есть сначала вы кодируете и обучаете модели, а затем понимаете математику или лежащие в ее основе концепции. И, согласно различному опыту, этот подход работает лучше, чем метод обучения Эндрю Нг, т. е. метод обучения «снизу вверх», который также хорош. Все, что работает для вас. Я больше практичный парень, так что это здорово для меня.
ТЕСЛА или НЕТ!
Хорошо, теперь давайте к теме. Итак, в Уроке 2 вы узнаете, как распознавать изображения или идентифицировать объекты, а библиотека Fast.AI позволяет очень легко сделать это всего за несколько строк.
И, как я всегда повторяю в своих видео на YouTube, всегда пачкайте руки, потому что именно так вы действительно учитесь, поэтому я решил сделать модель, которая определяет, является ли автомобиль TESLA или НЕ. Очевидно, чего можно ожидать от поклонника Элона.
Как это сделать ?
Теперь давайте пройдемся по строкам кода, благодаря которым это происходит, и я объясню вам, что там на самом деле происходит.
Для большего контекста я написал это в блокноте Google Colab с экземпляром GPU для более быстрого обучения моделей.
1. Давайте установим некоторые необходимые пакеты, которые нам нужно использовать в программе.
!pip install fastai !pip install -Uqq fastbook
!pip install -Uqq fastbook
!pip install jmd_imagescraperТеперь, когда вы запустите это, и некоторые из них уже установлены в colab, вы можете получить что-то вроде этого:
Это просто говорит о том, что какой-то пакет уже установлен, и мы в безопасности, так что давайте двигаться дальше.
2. Давайте импортируем необходимые пакеты.
import fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.widgets import *
from pathlib import Path
from jmd_imagescraper.core import *3. Создание категорий классификации
classify_car = 'cars', 'tesla car'
tesla_models= 'tesla model x','tesla model y','tesla model s','tesla model 3', 'tesla roadster','tesla cybertruck'
path= Path('images')
path.mkdir(exist_ok= True)- Строка 1. Здесь я задаю две основные родительские категории, по которым мы будем классифицировать изображения.
- Строка 2. На самом деле, после того, как я просто скопировал изображения с помощью «автомобиля tesla», я понял, что это было слишком неоднозначно, поэтому я составил этот список, чтобы также обучить модель на основе всех конкретных моделей Telsa, чтобы увеличить точность модели и он сделал.
- Строка 3: здесь я просто задаю путь к другой папке с именем «images».
- Строка 4: здесь я создаю папку, используя функцию .mkdir и тег «exist_ok», который проверяет, создана ли папка уже или нет, поскольку мы запускаем ячейку много раз.
4. Давайте очистим и получим данные изображения.
Для лучшего контекста в настоящее время наша переменная «путь» находится в папке «изображения», которая в настоящее время пуста.
for model in classify_car: mpath = (path/model) mpath.mkdir(exist_ok= True) img = duckduckgo_search(mpath,'',f"{model}",max_results=150)for models in tesla_models : tpath=(path/'tesla car') img = duckduckgo_search(tpath,'',f"{model}",max_results=150)
- Строка 1. Здесь, как вы видите, я просматриваю две категории в массиве classify_car.
- Строка 2: здесь я задаю новый путь с категорией.
- Строка 3: здесь я создаю новую папку.
- Строка 4: здесь я использую функцию duckduckgo_search() для загрузки изображений.
Подробнее о функции duckduckgo_search():
- Первый аргумент: путь, по которому будут загружаться изображения.
- Второй аргумент: новая папка, в которую будут загружаться изображения, но она нам не нужна, так как мы уже создали папку, поэтому оставляем ее пустой.
- Третий аргумент: это поисковый запрос, который будет искаться в поисковой системе DuckDuckGo.
- Четвертый аргумент: это максимальное количество загружаемых изображений.
Итак, после его выполнения у вас должно быть две новые папки внутри «изображений», то есть «автомобили» и «автомобили tesla» по 150 изображений в каждом.
Теперь в следующем цикле for происходит то же самое, где я только что установил путь к «автомобилям tesla» и передаю конкретные модели из массива «tesla_models», чтобы также загрузить их изображения в папку.
5. Проверка изображений
files = get_image_files(path)
len(files)- Строка 1: получает все изображения из папки «images» .
- Строка 2: печатает общее количество файлов или изображений, которые у вас есть.
corrupted= verify_images(files)
corrupted- Это проверяет любые поврежденные изображения и отображает, если они были найдены.
corrupted.map( Path.unlink) #Remove corrupted files- Это удалит все изображения, которые были найдены поврежденными, и у нас останутся только хорошие изображения, готовые к обучению.
6. Подготовка данных к загрузке
data= DataBlock(blocks=(ImageBlock,CategoryBlock),
get_items=get_image_files,
get_y= parent_label,
splitter = RandomSplitter(valid_pct=0.2,seed=42 ),
item_tfms = Resize(128))Здесь мы используем DataBlock, который представляет собой API высокого уровня, который подготавливает окончательную форму данных перед их загрузкой в Dataloaders.
Давайте посмотрим, что здесь происходит :
- Строка 1: поскольку наша модель основана на изображениях в качестве входных данных и категории в качестве выходных данных, мы используем
blocks=(ImageBlock,CategoryBlock). - Строка 2: получаем все файлы изображений.
- Строка 3: здесь y считается выходом, поэтому мы устанавливаем его на «parent_label», который получает
- имя папки, в которой расположены изображения, что будет нашим выходом, когда мы классифицируем новое изображение.
- Строка 4. Здесь мы разделяем 20 % набора данных на проверочный набор.
- Строка 5: здесь мы преобразуем наши изображения, изменяя их размер до 128 x 128 квадратов, чтобы сохранить единообразие в наборе данных.
7. Загрузка данных
data_load = data.dataloaders(path)- Здесь мы, наконец, загружаем данные в DataLoader.
data_load.valid.show_batch(max_n=10 , nrows=2)- Это показывает вам некоторые изображения в данных.
data = data.new(item_tfms=Resize(128), batch_tfms=aug_transforms())
data_load = data.dataloaders(path)Здесь мы дополнительно оптимизируем набор данных, используя aug_transformer, который является служебной функцией, позволяющей легко создавать список преобразований отражения, поворота, масштабирования, деформации и освещения.
8. Давайте обучим модель
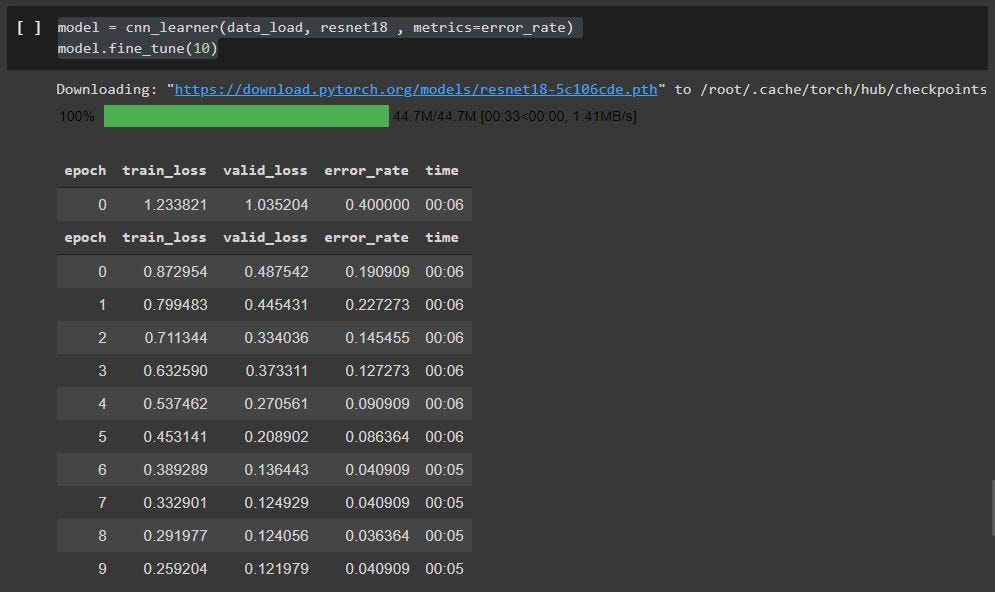
model = cnn_learner(data_load, resnet18 , metrics=error_rate)
model.fine_tune(10)Здесь мы обучаем модель с помощью фабричного метода cnn_learner, который помогает автоматически получить предварительно обученную модель из заданной архитектуры с настраиваемой головкой, подходящей для ваших данных.
Вы должны увидеть что-то подобное после того, как ваша модель закончит обучение:
Теперь давайте посмотрим на матрицу путаницы, чтобы увидеть, как работает наша модель:
interp= ClassificationInterpretation.from_learner(model)
interp.plot_confusion_matrix( )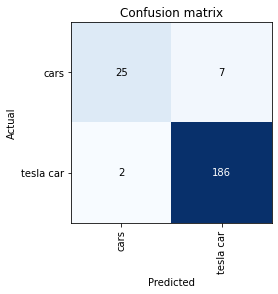
Выглядит хорошо! Поздравляем, вы успешно обучили модель!
Давайте предскажем сейчас — Момент истины
tst= (path/'test') tst.mkdir(exist_ok=True) img = download_images(tst,urls=['https://www.businessinsider.in/photo/52674243/with-model-3-demand-surging-tesla-is-bringing-back-a-66000-version-of-its-model-s.jpg']) image = PILImage.create('/content/images/test/00000000.jpg')pred, predId, prob = model.predict('/content/images/test/00000000.jpg') if pred=='cars': print(f'Hey I am {prob[predId]*100:.04f} % sure that this image is a NOT a Tesla ') else : print(f'Hey I am {prob[predId]*100:.04f}% sure that this image is a Tesla !') image
Вы можете просто изменить URL-адрес в «urls=[…]» на любой URL-адрес изображения, которое вы хотите протестировать.
Вот как это должно выглядеть:
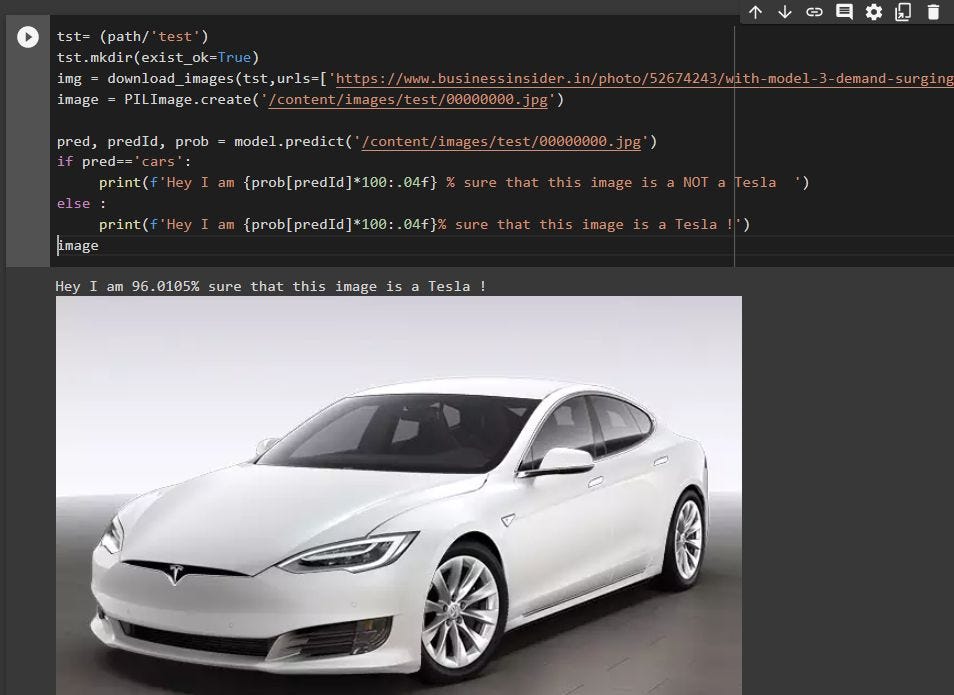
Я буду работать над его развертыванием сейчас!
Вы можете найти весь код на моем GitHub ЗДЕСЬ. Если вам это нравится, поставьте звезду 🌟 !!
Я также создаю контент, связанный с информатикой, на Youtube в разделе Future Driven и веду блоги на своем Личном сайте. 🧡✔
Подключаем:
📹 Канал на YouTube: FutureDriven
✍️ Персональный сайт: Thecsengineer.com
🐦 Твиттер: saumya4real
👨💻 LinkedIn: saumya66
🔥 GitHub: saumya66
Надеюсь, вам понравилось и вы узнали что-то новое.🤞😃