
Вы когда-нибудь задумывались, как все данные, которыми мы располагаем, компьютеры могут так легко извлекать информацию, казалось бы, из воздуха? Неужели мы просто принимаем как должное, что компьютеры такие умные и могут запоминать список наших друзей и их адреса, как будто они понимают взаимосвязь между этими двумя точками данных.
Ну… в зависимости от того, на чьей вы стороне в споре, вы либо рады, либо нет тому, что они этого не делают, потому что мы должны их обмануть.
Хеш-карты — это относительно простая и красивая концепция для понимания. Хеш-карты используют массивы для заполнения информации. Обычно наш массив представляет собой список других массивов, и внутри каждого массива находится узел информации.
[[ключ, значение], [ключ, значение], [ключ, значение]…]
Здесь нам просто нужно знать, какой индекс нам нужен, чтобы найти адрес Фулано.
Мы могли бы даже использовать связанные списки в нашем массиве, чтобы он содержал больше информации, идущей еще глубже.
[ [[ключ, значение], [ключ, значение], [ключ, значение]], [[ключ, значение], [ключ, значение], [ключ, значение]] …[[],[] ,[]]…]
Здесь нам нужно знать, какой индекс искать, а затем пройтись по списку, чтобы найти Фулано.
Лично я предпочитаю вариант со списком ссылок, потому что иногда порядковый номер назначается более чем одной клавише.
В традиционном массиве нам нужно будет проверить, не пусто ли это место в индексе. Если это не так, мы перейдем к следующему индексу и посмотрим, пуст ли этот индекс. Это может продолжаться какое-то время и испортить другие ключи в будущем. Это известно как коллизии. Использование связанного списка просто добавит к нему и позволит ключам совместно использовать порядковые номера. Это называется раздельной цепочкой. Подробнее здесь.
Но откуда нам знать, какой индекс искать? Иногда наши массивы могут быть огромными, и перебирать их каждый раз, когда мы хотим найти Фулано, крайне неэффективно… как бы Фулано ни хотел остаться неизвестным.
Мы это сделаем! Хеширование — это просто выполнение математической операции над ключом. Хеширование выполняет функцию encode() для нашей ключевой информации — Фулано! Кодировка будет одинаковой каждый раз, так что это надежная константа. Затем мы возьмем сумму нашей кодировки, и это будет наш хэш-код!
Теперь это может привести к большому количеству и легко превзойти количество индексов в нашем массиве.
При создании хэш-карты размер нашего массива задается изначально и не может быть изменен. Поэтому, чтобы убедиться, что мы получим число, которое будет работать, нам нужно сжать этот хеш-код с помощью оператора по модулю на размер массива.
Вот как это будет выглядеть:

Эти две функции, работающие вместе, надежно присвоят ключу один и тот же номер индекса.
Обратите внимание, что с самого начала при создании нашего класса HashMap все, что нам нужно, это установить размер нашего массива, и оттуда мы создадим массив связанных списков.
Отсюда все, что нам нужно, — это возможность назначать нашу информацию индексу и возможность ее извлечения.
Для назначения мы создадим функцию assign(), которая принимает ключ и значение, которое нужно убрать. Мы будем использовать наши удобные функции hash() и compress(), чтобы определить индекс для его назначения. Затем загрузите наш [key, vaule] в класс Node.
Я также хочу проверить, находится ли наш ключ уже в нашем массиве. Если это так, я просто обновлю значение, так как наш ключ уже там. Если нет, то я буду использовать функцию insert() из моего класса LinkedList для вставки нового узла.
Извлечение его будет работать в обратном направлении и просто выполнять итерацию по назначенному индексу. Если ключ не найден, мы вернем None.
Вот как мы обманываем программы, заставляя их «запоминать» огромные объемы данных, и получаем возможность вспоминать лучше, чем любой человеческий разум.
Давайте проверим его. Я создам экземпляр HashMap с именем «местоположения», затем пройдусь по адресной книге, чтобы назначить их местоположениям, и посмотрю, не смогу ли я найти Fulano.
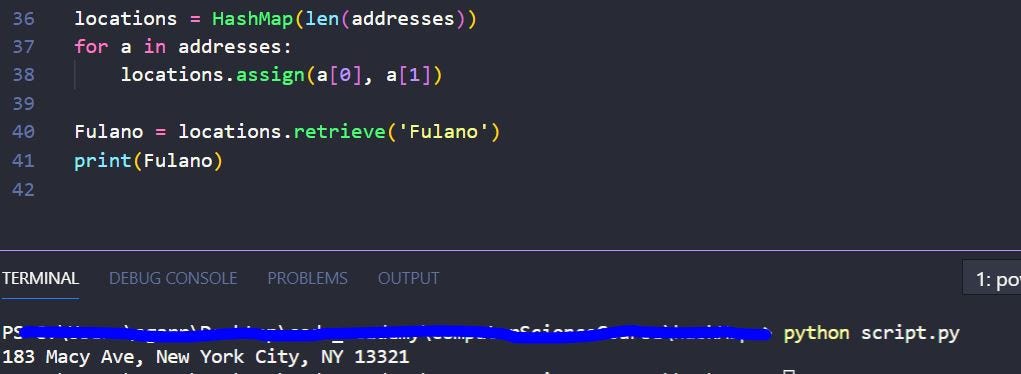
Лучше двигаться быстро. Кто знает, как долго он будет там.