Введение
Кластеризация K-средних — это неконтролируемый алгоритм машинного обучения, который используется для решения проблем кластеризации в машинном обучении. В реальных сценариях немаркированные данные, которые могут существовать для решения проблем. В таких случаях алгоритм K-средних играет жизненно важную роль в решении проблемы. При этом неразмеченные данные разбиваются на подгруппы. Где группы можно назвать кластером. Группировка может быть выполнена по данным, имеющим схожий размер, форму, меру, характеристику. Наконец, сгруппируйте данные в отдельный кластер. Здесь приходят значения K, сколько кластеров нужно создать. Существует отдельная методика определения значения k. Мы рассмотрим позже в этой статье.
Что такое алгоритм K-средних?
Кластеризация K-средних — это алгоритм обучения без учителя, который группирует немаркированный набор данных в разные кластеры. Здесь K определяет количество предопределенных кластеров, которые необходимо создать в процессе, например, если K=2, будет два кластера, а при K=3 будет три кластера и так далее.
Это итеративный алгоритм, который делит немаркированный набор данных на k разных кластеров таким образом, что каждый набор данных принадлежит только одной группе со схожими свойствами.
Это позволяет нам группировать данные в разные группы и является удобным способом самостоятельного обнаружения категорий групп в немаркированном наборе данных без необходимости какого-либо обучения.
Это алгоритм на основе центроида, в котором каждый кластер связан с центроидом. Основная цель этого алгоритма — минимизировать сумму расстояний между точкой данных и их соответствующими кластерами.
Алгоритм принимает немаркированный набор данных в качестве входных данных, делит набор данных на k кластеров и повторяет процесс до тех пор, пока не найдет лучшие кластеры. В этом алгоритме значение k должно быть задано заранее.
Алгоритм кластеризации k-средних в основном выполняет две задачи:
- Определяет лучшее значение для K центральных точек или центроидов с помощью итеративного процесса.
- Назначает каждую точку данных ближайшему k-центру. Те точки данных, которые находятся рядом с конкретным k-центром, создают кластер.
Следовательно, каждый кластер имеет точки данных с некоторыми общими чертами и находится вдали от других кластеров.
На приведенной ниже диаграмме объясняется работа алгоритма кластеризации K-средних:

Как работает алгоритм K-средних?
Предположим, наша цель — найти несколько похожих групп в наборе данных, например:

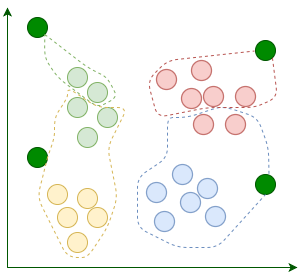
K-Means начинается с k случайно расположенных центроидов. Центроиды, как следует из их названия, являются центральными точками кластеров. Например, здесь мы добавляем четыре случайных центроида:

Затем мы назначаем каждую существующую точку данных ее ближайшему центроиду:
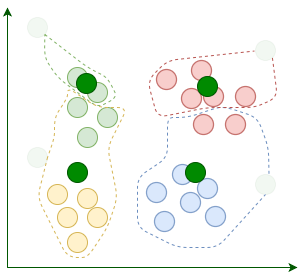
После назначения мы перемещаем центроиды в среднее расположение назначенных ему точек. Помните, что центроиды должны быть центральными точками кластеров:
Текущая итерация завершается каждый раз, когда мы завершаем перемещение центроидов. Мы повторяем эти итерации до тех пор, пока назначение между несколькими последовательными итерациями не перестанет меняться:
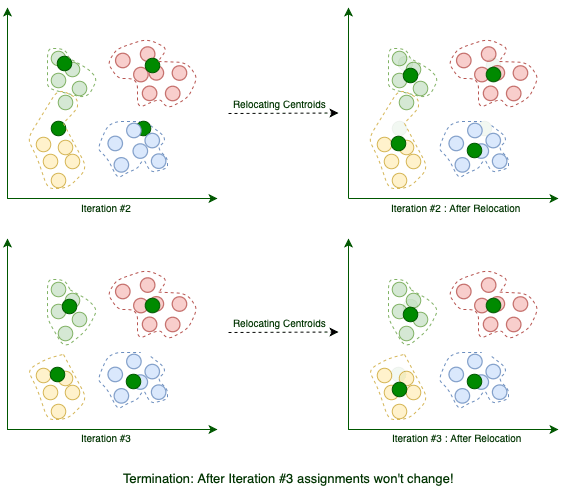
Когда алгоритм завершится, эти четыре кластера будут найдены, как и ожидалось.
Метод кластеризации K-средних:
Если k задано, алгоритм K-средних может быть выполнен в следующих шагах:
- Разбиение объектов на k непустых подмножеств
- Идентификация центроидов кластера (средняя точка) текущего раздела.
- Назначение каждой точки определенному кластеру
- Вычислите расстояния от каждой точки и назначьте точки кластеру, где расстояние от центроида минимально.
- После перераспределения точек найдите центр тяжести нового сформированного кластера.
Пошаговый процесс:
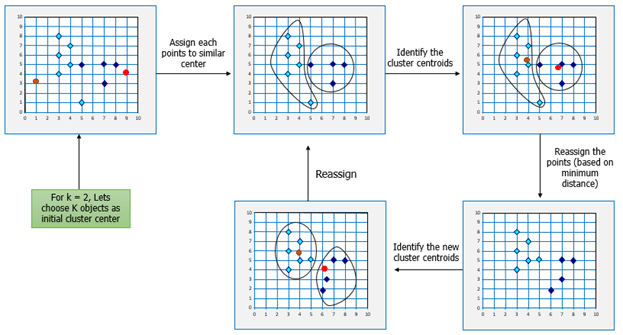
Чтобы определить k кластеров
Метод локтя — один из самых популярных способов нахождения оптимального количества кластеров. Этот метод использует концепцию значения WCSS. WCSS расшифровывается как Сумма квадратов внутри кластера, которая определяет общее количество вариаций внутри кластера. Формула для расчета значения WCSS (для 3 кластеров) приведена ниже:
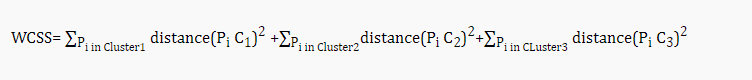
В приведенной выше формуле WCSS

Это сумма квадратов расстояний между каждой точкой данных и ее центром тяжести в кластере1 и то же самое для двух других членов.
Чтобы измерить расстояние между точками данных и центроидом, мы можем использовать любой метод, такой как евклидово расстояние или манхэттенское расстояние.
Давайте начнем реализацию с использованием Python для определения значения K. Здесь используется коллаб Google для реализации.
Импортировать библиотеки
import pandas as pd
import numpy as np
from google.colab import files
uploaded = files.upload()Загрузить набор данных
import io
train_data = pd.read_csv(io.StringIO(uploaded['Mall_Customers.csv'].decode('utf-8')))Отображение первых 5 записей из набора данных
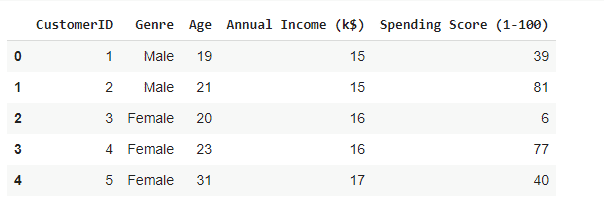
Определить значения X
Принимая годовой доход и счет расходов.
X= train_data.iloc[:,3:]
X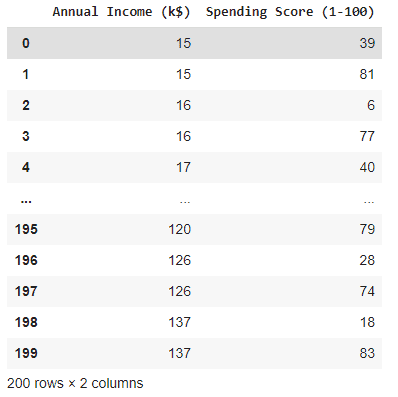
Определить значение K
from sklearn.cluster import KMeans from matplotlib import pyplot as plot wcss = []for i in range (1, 15): kmeans = KMeans(n_clusters=i, init='k-means++', random_state=42) kmeans.fit(X) wcss.append(kmeans.inertia_) plot.plot(range(1,15), wcss) plot.title('The Elbow Method') plot.xlabel('Number of clusters') plot.ylabel('WCSS') plot.show()
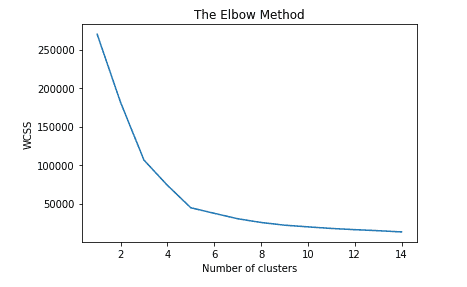
Острая точка изгиба или точка графика выглядит как рука, тогда эта точка считается лучшим значением K. Таким образом, оптимальное значение K равно 5.
Перейдем к применению значения K.
kmeans = KMeans(n_clusters=5, init='k-means++', random_state=42)
y_kmeans= kmeans.fit_predict(X)
y_kmeans
Визуализация
plot.scatter(X[y_kmeans == 0]['Annual Income (k$)'], X[y_kmeans == 0]['Spending Score (1-100)'], s = 100, c = 'red', label = 'Cluster 1')
plot.scatter(X[y_kmeans == 1]['Annual Income (k$)'], X[y_kmeans == 1]['Spending Score (1-100)'], s = 100, c = 'blue', label = 'Cluster 2')
plot.scatter(X[y_kmeans == 2]['Annual Income (k$)'], X[y_kmeans == 2]['Spending Score (1-100)'], s = 100, c = 'green', label = 'Cluster 3')
plot.scatter(X[y_kmeans == 3]['Annual Income (k$)'], X[y_kmeans == 3]['Spending Score (1-100)'], s = 100, c = 'cyan', label = 'Cluster 4')
plot.scatter(X[y_kmeans == 4]['Annual Income (k$)'], X[y_kmeans == 4]['Spending Score (1-100)'], s = 100, c = 'magenta', label = 'Cluster 5')
plot.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plot.title('Clusters of customers')
plot.xlabel('Annual Income (k$)')
plot.ylabel('Spending Score (1-100)')
plot.legend()
plot.show()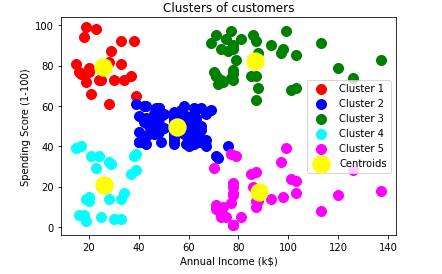
Выходное изображение четко показывает пять разных кластеров с разными цветами. Кластеры формируются между двумя параметрами набора данных; Годовой доход клиента и расходы. Мы можем изменить цвета и этикетки в соответствии с требованиями или выбором. Мы также можем наблюдать некоторые моменты из приведенных выше моделей, которые приведены ниже:
- Cluster1 показывает клиентов со средней зарплатой и средними расходами.
- Кластер 2 показывает, что у клиента высокий доход, но низкие расходы.
- Кластер 3 показывает низкий доход, а также низкие расходы
- Кластер 4 показывает клиентов с низким доходом и очень высокими расходами.
- Cluster5 показывает клиентов с высоким доходом и высокими расходами, поэтому их можно классифицировать как целевые, и эти клиенты могут быть самыми прибыльными клиентами для владельца торгового центра.
Теперь покажем, как мы можем использовать метод значения силуэта, чтобы найти значение «k».
from sklearn.metrics import silhouette_samples, silhouette_score
import seaborn as sns
clusters_range = range (2,15)
results = []
for i in clusters_range:
cluster = KMeans(n_clusters=i, init='k-means++', random_state=42)
cluster_labels= cluster.fit_predict(X)
silhouette_avg = silhouette_score(X, cluster_labels)
results.append([i, silhouette_avg])
result = pd.DataFrame(results, columns=['n_clusters','silhouette_score'])
pivot = pd.pivot_table(result,index='n_clusters', values='silhouette_score')
plot.figure()
sns.heatmap(pivot, annot=True, linewidths=.5, fmt='.3f', cmap=sns.cm.rocket_r)
plot.tight_layout()
Если мы наблюдаем, мы получаем оптимальное количество кластеров при n = 5, поэтому мы можем, наконец, выбрать значение k = 5.
Преимущества использования кластеризации методом k-средних
- Легко реализовать.
- При большом количестве переменных K-Means может быть быстрее в вычислительном отношении, чем иерархическая кластеризация (если K мало).
- k-Means может создавать более высокие кластеры, чем иерархическая кластеризация.
Недостатки использования кластеризации методом k-средних
- Трудно предсказать количество кластеров (K-значение).
- Первоначальные семена оказывают сильное влияние на конечные результаты.
Надеюсь, эта статья поможет вам лучше понять модель машинного обучения K-Means.
До новых встреч в очередной интересной статье.
Удачного обучения :)