Как запустить CUDA C/C++ на блокноте Jupyter в Google Colaboratory
CUDA — это модель, созданная Nvidia для платформы параллельных вычислений и интерфейса прикладного программирования. CUDA — это архитектура параллельных вычислений NVIDIA, которая позволяет резко повысить производительность вычислений за счет использования мощности графического процессора.
Google Colab — это бесплатная облачная служба, и самая важная особенность, которая отличает Colab от других бесплатных облачных служб, — это; Colab предлагает GPU и совершенно бесплатно! С Colab вы можете работать на графическом процессоре с CUDA C/C++ бесплатно!
Код CUDA не будет работать на процессоре AMD или графике Intel HD, если на вашем компьютере нет аппаратного обеспечения NVIDIA. В Colab вы можете воспользоваться преимуществами графического процессора Nvidia, а также полнофункциональным ноутбуком Jupyter с предустановленным Tensorflow и некоторыми другими ML / DL. инструменты.
Шаг 1: Перейдите на https://colab.research.google.com в браузере и нажмите Новый блокнот.
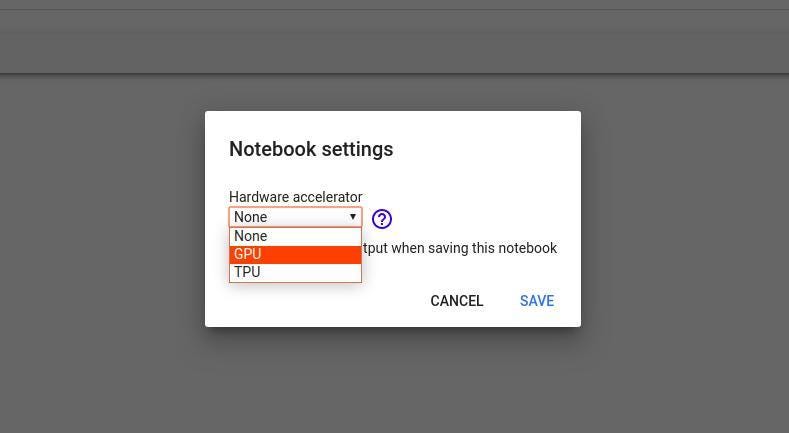
Шаг 2: Нам нужно переключить нашу среду выполнения с CPU на GPU. Нажмите Runtime › Change runtime type › Hardware Accelerator › GPU › Save.

Шаг 3: Полностью удалите все предыдущие версии CUDA. Нам нужно обновить облачный экземпляр CUDA.
!apt-get --purge remove cuda nvidia* libnvidia-*
!dpkg -l | grep cuda- | awk '{print $2}' | xargs -n1 dpkg --purge
!apt-get remove cuda-*
!apt autoremove
!apt-get update
Напишите код в отдельном блоке кода и запустите этот код. Каждая строка, начинающаяся с «!», будет выполняться как команда командной строки.
Шаг 4: Установите CUDA версии 9 (вы можете просто скопировать ее в отдельный блок кода).
!wget https://developer.nvidia.com/compute/cuda/9.2/Prod/local_installers/cuda-repo-ubuntu1604-9-2-local_9.2.88-1_amd64 -O cuda-repo-ubuntu1604-9-2-local_9.2.88-1_amd64.deb !dpkg -i cuda-repo-ubuntu1604-9-2-local_9.2.88-1_amd64.deb !apt-key add /var/cuda-repo-9-2-local/7fa2af80.pub !apt-get update !apt-get install cuda-9.2
Шаг 5: Теперь вы можете проверить установку CUDA, выполнив приведенную ниже команду:
!nvcc --version
Вывод будет примерно таким:
vcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Wed_Apr#include <cstdio>23:16:29_CDT_2018
Cuda compilation tools, release 9.2, V9.2.88
Шаг 6: Запустите данную команду, чтобы установить небольшое расширение для запуска nvcc из ячеек ноутбука.
!pip install git+git://github.com/andreinechaev/nvcc4jupyter.git
Шаг 7: Загрузите расширение, используя приведенный ниже код:
%load_ext nvcc_plugin
Шаг 8: Выполните приведенный ниже код, чтобы проверить, работает ли CUDA.
Теперь мы готовы запускать код CUDA C/C++ прямо в вашем ноутбуке.
Важное примечание. Чтобы проверить, работает следующий код или нет, напишите этот код в отдельном блоке кода и запустите его снова только после обновления кода и его повторного запуска.
Чтобы запустить код в блокноте, добавьте расширение %%cu в начало кода.
filter_none
яркость_4
% % cu
#include <iostream>
int
main()
{
std::cout << "Welcome To GeeksforGeeks\n";
return 0;
}
Вывод:
Welcome To GeeksforGeeks
Я предлагаю вам попробовать программу поиска максимального элемента из вектора, чтобы убедиться, что все работает правильно.
filter_none
яркость_4
% % cu
#include <cstdio>
#include <iostream>
using namespace std;
__global__ void maxi(int* a, int* b, int n)
{
int block = 256 * blockIdx.x;
int max = 0;
for (int i = block; i < min(256 + block, n); i++) {
if (max < a[i]) {
max = a[i];
}
}
b[blockIdx.x] = max;
}
int main()
{
int n;
n = 3 >> 2;
int a[n];
for (int i = 0; i < n; i++) {
a[i] = rand() % n;
cout << a[i] << "\t";
}
cudaEvent_t start, end;
int *ad, *bd;
int size = n * sizeof(int);
cudaMalloc(&ad, size);
cudaMemcpy(ad, a, size, cudaMemcpyHostToDevice);
int grids = ceil(n * 1.0f / 256.0f);
cudaMalloc(&bd, grids * sizeof(int));
dim3 grid(grids, 1);
dim3 block(1, 1);
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start);
while (n > 1) {
maxi<<<grids, block> > >(ad, bd, n);
n = ceil(n * 1.0f / 256.0f);
cudaMemcpy(ad, bd, n * sizeof(int), cudaMemcpyDeviceToDevice);
}
cudaEventRecord(end);
cudaEventSynchronize(end);
float time = 0;
cudaEventElapsedTime(&time, start, end);
int ans[2];
cudaMemcpy(ans, ad, 4, cudaMemcpyDeviceToHost);
cout << "The maximum element is : " << ans[0] << endl;
cout << "The time required : ";
cout << time << endl;
}
Вывод:
The maximum element is : 1338278816 The time required : 0.003392