R, Веб-парсинг
R Project - веб-парсинг с помощью R - с использованием R и rvest
узнайте, как очистить данные из Интернета с помощью R и экспортировать их в формат CSV!
Отказ от ответственности: эта статья предназначена только для образовательных целей. Мы не призываем кого-либо очищать веб-сайты, особенно те веб-ресурсы, которые могут иметь положения и условия, запрещающие такие действия.
Информация везде. Информационный поток в Интернете непрерывен. Благодаря всем технологическим достижениям стало еще проще собирать, записывать, хранить и получать доступ к данным. Поэтому Интернет наполнен большим количеством наборов данных, которые вы можете использовать для своих личных проектов. Иногда вам может повезти, и вы получите доступ к полному, аккуратному и чистому набору данных. В других случаях вам не повезет, и у вас не будет доступа к полному набору данных. В таких случаях вам придется выполнять парсинг веб-страниц. В этой статье я расскажу вам, как очистить данные из Интернета с помощью языка программирования R.
В этой статье мы рассмотрим следующие вещи -
- Что такое парсинг?
- Методы парсинга
- Предварительные условия для очистки данных с помощью R
- Веб-парсинг с помощью R
- Анализ данных с помощью R

1. Что такое веб-парсинг?
Веб-парсинг или веб-сбор данных - это процесс сбора данных с разных веб-сайтов. Это метод, используемый для преобразования неструктурированных данных (формат HTML) в структурированный формат, к которому можно получить доступ и легко использовать. С помощью этого метода данные можно легко собирать и хранить в базах данных или электронных таблицах для дальнейшего анализа. В целом веб-сбор данных используется людьми, организациями и предприятиями по всему миру, которые хотят использовать большой объем общедоступных данных для принятия более эффективных и содержательных решений.
2. Методы парсинга веб-страниц
Существуют различные методы очистки данных из Интернета. Некоторые из способов -
- Соответствие текстовому шаблону
- Копипаст человека
- HTTP программирование
- Разбор HTML
- Парсинг DOM
3. Предварительные условия для очистки данных с помощью R
Чтобы начать работу с веб-парсингом, вы должны иметь практические знания языка программирования R. R очень легко изучить и использовать. В этой статье мы будем использовать пакет rvest, созданный знаменитым Хэдли Уикхемом. Сначала вам нужно установить этот пакет. Вы можете ознакомиться с документацией здесь. Также будут полезны дополнительные знания HTML и CSS. В Интернете доступно множество ресурсов для изучения обоих языков.
Поскольку HTML и CSS не являются основными навыками, необходимыми для того, чтобы стать специалистом по обработке данных, мы будем использовать здесь расширение Selector Gadget для очистки данных. Selector Gadget - это бесплатное расширение селектора CSS с открытым исходным кодом, доступное в интернет-магазине Google Chrome. Вы можете скачать и установить его здесь. Пожалуйста, убедитесь, что вы установили его, прежде чем запускать парсинг веб-страниц. Используя это расширение, вы можете выбрать любую часть веб-сайта и получить соответствующие теги, чтобы получить доступ к этой части, просто нажав на эту часть веб-сайта. Но если вы действительно хотите овладеть искусством парсинга веб-страниц, я рекомендую изучить HTML и CSS.
4. Веб-парсинг с помощью R
А теперь давайте приступим к поиску на веб-сайте IMDB лучших победителей конкурса фотографий 1927–2019 годов. Вы можете посетить сайт здесь.
# Lets fist install rvest package for parsing of HTML and / or XML files
install.packages("rvest")
Теперь давайте установим другие пакеты -
#lets install lubridate and tidyverse package for date and time manipulation
install.packages(c("lubridate", "tidyverse"))
Мы установили необходимые пакеты. Загрузим их.
# load all the necessary packages library(tidyverse) library(lubridate) library(rvest)
После загрузки пакетов пора указать URL-адрес желаемого веб-сайта, который нужно очистить.
# now specify the url for desired website to be scraped link <- "https://www.imdb.com/search/title/?count=100&groups=oscar_best_picture_winners&sort=year%2Cdesc&ref_=nv_ch_osc" #Read the HTML code from the website website <- read_html(link) website str(website)
Вы получите следующий результат -
{html_document}
<html xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n<script type="text/javascript">var ue ...
[2] <body id="styleguide-v2" class="fixed">\n <img height="1" width="1" style="display:none;visibility:hidd ...
> str(website)
List of 2
$ node:<externalptr>
$ doc :<externalptr>
- attr(*, "class")= chr [1:2] "xml_document" "xml_node"
Мы очистим следующие данные с веб-сайта:
- Классифицировать
- Заголовок
- Описание
- Время выполнения
- Жанр
- Рейтинг
- Metascore
- Голоса
- Валовая выручка
- Актер
- Директор
Начнем с очистки поля «Ранги». Для этого воспользуемся расширением Selector Gadget. Используйте это расширение, чтобы указать селекторы CSS, которые включают раздел рейтинга веб-страницы. Просто нажмите на расширение в браузере и выберите курсором поле рейтинга. Это будет выглядеть примерно так -

Убедитесь, что все рейтинги выбраны правильно. Как только вы выберете все рейтинги, скопируйте соответствующий селектор CSS, указанный внизу. В данном случае это .text-primary.
Теперь мы знаем селектор CSS. Мы будем использовать этот простой код R, чтобы получить все рейтинги -
# using CSS selectors to scrape the rankings selection rankings_html <- html_nodes(website, ".text-primary") #converting the rankings data to the text format ranks_data <- html_text(rankings_html) #now lets have a look at our data View(ranks_data) #lets view some top elements head(ranks_data)
После запуска этого кода вы получите следующий результат:
[1] "1." "2." "3." "4." "5." "6."
После получения данных убедитесь, что они имеют желаемый формат. Итак, давайте преобразуем наши данные в числовой формат -
# lets convert rankings data to numerical format ranks_data <- as.numeric(ranks_data) head(ranks_data)
Теперь наш результат будет выглядеть так -
[1] 1 2 3 4 5 6
Теперь мы очистим предыдущий выбор и выделим все заголовки.
# using CSS selectors to scrape the title selection title_html <- html_nodes(website, ".lister-item-header a") #converting the title data to the text format title_data <- html_text(title_html) #now lets have a look at our data View(title_data) # lets look at some top elements head(title_data)
Результат будет выглядеть так -
[1] "Gisaengchung" "Green Book" [3] "The Shape of Water" "Moonlight" [5] "Spotlight" "Birdman or (The Unexpected Virtue of Ignorance)"
Теперь давайте сделаем это для данных описания -
# using CSS selectors to scrape the description selection description_html <- html_nodes(website, ".ratings-bar+ .text-muted") #converting the description data to the text format description_data <- html_text(description_html) # lets look at some top elements head(description_data)
Вы получите результат как -
[1] "\n Greed and class discrimination threaten the newly formed symbiotic relationship between the wealthy Park family and the destitute Kim clan." [2] "\n A working-class Italian-American bouncer becomes the driver of an African-American classical pianist on a tour of venues through the 1960s American South." [3] "\n At a top secret research facility in the 1960s, a lonely janitor forms a unique relationship with an amphibious creature that is being held in captivity." [4] "\n A young African-American man grapples with his identity and sexuality while experiencing the everyday struggles of childhood, adolescence, and burgeoning adulthood." [5] "\n The true story of how the Boston Globe uncovered the massive scandal of child molestation and cover-up within the local Catholic Archdiocese, shaking the entire Catholic Church to its core." [6] "\n A washed-up superhero actor attempts to revive his fading career by writing, directing, and starring in a Broadway production."
Теперь давайте очистим данные -
#lets process this data and remove "\n"
description_data <- gsub("\n", "", description_data)
#lets have another look at description data
head(description_data)
Вы получите результат как -
[1] "Greed and class discrimination threaten the newly formed symbiotic relationship between the wealthy Park family and the destitute Kim clan." [2] "A working-class Italian-American bouncer becomes the driver of an African-American classical pianist on a tour of venues through the 1960s American South." [3] "At a top secret research facility in the 1960s, a lonely janitor forms a unique relationship with an amphibious creature that is being held in captivity." [4] "A young African-American man grapples with his identity and sexuality while experiencing the everyday struggles of childhood, adolescence, and burgeoning adulthood." [5] "The true story of how the Boston Globe uncovered the massive scandal of child molestation and cover-up within the local Catholic Archdiocese, shaking the entire Catholic Church to its core." [6] "A washed-up superhero actor attempts to revive his fading career by writing, directing, and starring in a Broadway production."
Давайте выполним этот код для выбора среды выполнения -
#using CSS selectors to scrape the movie run time section runtime_html <- html_nodes(website, ".runtime") #converting the run time data to text format runtime_data <- html_text(runtime_html) #lets look at some of the top elements head(runtime_data)
Вы получите следующий результат -
[1] "132 min" "130 min" "123 min" "111 min" "129 min" "119 min"
Теперь давайте очистим данные -
#lets remove the min and convert it to numerical value
runtime_data <- gsub("min", "", runtime_data)
runtime_data <- as.numeric(runtime_data)
#lets have another look at the data
head(runtime_data)
Вы получите результат как -
[1] 132 130 123 111 129 119
А теперь давайте посмотрим на подборку жанров -
##Using CSS selectors to scrape the Movie genre section genre_html <- html_nodes(website, ".genre") #lets convert genre data to text format genre_data <- html_text(genre_html) #lets look at some of the top elements of the data head(genre_data)
Вы получите результат как -
[1] "\nComedy, Drama, Thriller " "\nBiography, Comedy, Drama " [3] "\nAdventure, Drama, Fantasy " "\nDrama " [5] "\nBiography, Crime, Drama " "\nComedy, Drama
Теперь давайте очистим данные -
#lets process this data and remove "\n", excess spaces and keeping only first genre of the data
genre_data <- gsub("\n", "", genre_data)
genre_data<-gsub(" ","",genre_data)
genre_data<-gsub(",.*","",genre_data)
#Converting each genre from text to factor
genre_data <- as.factor(genre_data)
#lets have another look at the data
head(genre_data)
Вы получите результат как -
[1] Comedy Biography Adventure Drama Biography Comedy
Теперь давайте посмотрим на выбор рейтинга IMDB -
#Using CSS selectors to scrape the IMDB rating section IMDB_ratings_html <- html_nodes(website, ".ratings-imdb-rating") #lets convert html data to text data IMDB_ratings_data <- html_text(IMDB_ratings_html) #lets look at some of the top elements of the data head(IMDB_ratings_data)
Вы получите результат как -
[1] "\n \n 8.6\n " "\n \n 8.2\n " "\n \n 7.3\n " [4] "\n \n 7.4\n " "\n \n 8.1\n " "\n \n 7.7\n "
Теперь давайте очистим данные -
#lets convert the strings data to numerical data and convert it to numeric
IMDB_ratings_data <- gsub("\n", "", IMDB_ratings_data)
IMDB_ratings_data <- as.numeric(IMDB_ratings_data)
#lets look at some of the top elements of the data
head(IMDB_ratings_data)
Вы получите результат как -
[1] 8.6 8.2 7.3 7.4 8.1 7.7
Теперь давайте посмотрим на выбор голосов -
#Using CSS selectors to scrape the votes section votes_html <- html_nodes(website, ".sort-num_votes-visible span:nth-child(2)") #lets convert votes data to text data votes_data <- html_text(votes_html) #lets look at some of the top elements of the data head(votes_data)
Вы получите результат как -
[1] "550,381" "376,701" "370,690" "273,379" "419,883" "579,887"
Теперь давайте очистим данные -
#lets remove the commas and convert votes to numerical
votes_data <- gsub(",", "", votes_data)
votes_data <- as.numeric(votes_data)
#lets look at some of the top elements of the data
head(votes_data)
Вы получите результат как -
[1] 550381 376701 370690 273379 419883 579887
А теперь давайте посмотрим на выбор директоров -
#Using CSS selectors to scrape the directors names directors_html <- html_nodes(website, ".text-muted+ p a:nth-child(1)") #lets convert directors data to text directors_data <- html_text(directors_html) #lets look a some of the top elements head(directors_data)
Вы получите результат как -
[1] "Bong Joon Ho" "Peter Farrelly" "Guillermo del Toro" "Barry Jenkins" [5] "Tom McCarthy" "Alejandro G. Iñárritu"
Теперь давайте очистим данные -
#lets convert directors data into factors directors_data <- as.factor(directors_data) #lets look a some of the top elements head(directors_data)
Вы получите результат как -
[1] Bong Joon Ho Peter Farrelly Guillermo del Toro Barry Jenkins Tom McCarthy [6] Alejandro G. Iñárritu
А теперь давайте посмотрим на выбор актеров -
#Using CSS selectors to scrape the actors section actors_html <- html_nodes(website, ".lister-item-content .ghost+ a") #lets convert actors data to text data actors_data <- html_text(actors_html) #lets look at some of the top elements head(actors_data)
Вы получите результат как -
[1] "Kang-ho Song" "Viggo Mortensen" "Sally Hawkins" "Mahershala Ali" "Mark Ruffalo" "Michael Keaton"
Теперь давайте очистим данные -
#lets convert data to factors actors_data <- as.factor(actors_data) #lets look at some of the top elements again head(actors_data)
Вы получите результат как -
[1] Kang-ho Song Viggo Mortensen Sally Hawkins Mahershala Ali Mark Ruffalo Michael Keaton
Теперь давайте посмотрим на выбор Metascore -
Я хочу, чтобы вы все внимательно изучили данные Metascore.
#Using CSS selectors to scrape the meta score section metascore_html <- html_nodes(website, ".metascore") #lets convert meta score data to text data metascore_data <- html_text(metascore_html) #lets look at some of the top elements head(metascore_data)
Вы получите результат как -
[1] "96 " "69 " "87 " "99 " "93 " "87 "
Теперь давайте очистим данные -
#lets remove the extra space from the data and convert them as factors
metascore_data<-gsub(" ","",metascore_data)
metascore_data <- as.factor(metascore_data)
#lets look at some of the top elements
head(metascore_data)
Вы получите результат как -
[1] 96 69 87 99 93 87
А теперь посмотри внимательно -
# lets view the metascore data View(metascore_data) # after looking at the data, you will see that this section has only 76 rows wile we are scraping the data for 93 movies #lets check the length of the meta score data length(metascore_data)
Вы получите следующий результат -
[1] 76
Это произошло из-за того, что в некоторых фильмах нет соответствующих полей Metascore, показанных на скриншоте ниже - Итак, мы добавим NA в остальные записи и продолжим -
Вот как вы должны это делать -
# from the output we can see that the length of metascore data is only 76 while we are scarping data for 93 movies.
#This is because some of the movies do not have the metascore fields as shown in the screen shot below.
# so lets put NAs into the rest of the field.
for (i in c(64,65,68,71,73,75,76,77,79,82,83,84,87,88,91,92,93)){
a <- metascore_data[1:(i-1)]
b <- metascore_data[i:length(metascore_data)]
metascore_data <- append(a, list("NA"))
metascore_data <- append(metascore_data, b)
}
metascore_data <- as.numeric(unlist(metascore_data))
# lets check the length again
length(metascore_data)
# we can see that it has 94 entries now. so lets remove extra one
metascore_data <- metascore_data[-94]
#lets check the length again
length(metascore_data)
После выполнения этого шага вы получите на выходе 93 записи.
#lets look at some of the top elements again head(metascore_data) # lets look at the summary statistics summary(metascore_data)
Вы получите следующий результат -
[1] 31 7 22 34 28 22 Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 1.00 12.75 20.00 18.62 25.25 34.00 17
Теперь давайте посмотрим на выборку валового дохода -
То же самое происходит с данными о валовом доходе.
#Using CSS selectors to scrape the gross revenue section gross_revenue_html <- html_nodes(website, ".ghost~ .text-muted+ span") # lets convert gross revenue data to text data gross_revenue_data <- html_text(gross_revenue_html) # lets look at some of the top elements head(gross_revenue_data)
Вы получите следующий результат -
[1] "$53.37M" "$85.08M" "$63.86M" "$27.85M" "$45.06M" "$42.34M"
Теперь давайте очистим данные -
# lets remove the $ and M signs
gross_revenue_data <- gsub("M", "", gross_revenue_data)
gross_revenue_data <- substring(gross_revenue_data, 2,6)
head(gross_revenue_data)
Давайте еще раз очистим данные -
# lets check the length of the data
length(gross_revenue_data)
#after checking the lenght of the data, you will notice the same thing which happened with metascore data.
#so lets put NAs into all the missing values
# lets fill missing values with NA
for (i in c(62,65,71,72,73,79,83,84,85,89)){
s <- gross_revenue_data[1:(i-1)]
d <- gross_revenue_data[i:length(gross_revenue_data)]
gross_revenue_data <- append(s, list("NA"))
gross_revenue_data <- append(gross_revenue_data, d)
}
#lets convert gross data to numerical
gross_revenue_data <- as.numeric(gross_revenue_data)
head(gross_revenue_data)
#Let's have another look at the length of gross revenue data
length(gross_revenue_data)
summary(gross_revenue_data)
Вы получите следующий результат -
[1] 93 Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 0.01 24.02 54.58 81.70 110.20 659.30 10
Мы успешно скопировали все 11 элементов из 93 фильмов-победителей с 1927 по 2019 год. Итак, теперь давайте создадим фрейм данных, объединяющий вышеупомянутые функции.
# combining all the lists to form the new data frame best_movies_data <- data.frame(Rank = ranks_data, Title = title_data, Description = description_data, Runtime = runtime_data, Genre = genre_data, IMDB_Ratings = IMDB_ratings_data, Votes = votes_data, Directors = directors_data, Actors = actors_data, Metascore = metascore_data, Gross_Revenue = gross_revenue_data) View(best_movies_data) # lets look at structure of the data frame str(best_movies_data)
Вы получите следующий результат -
'data.frame': 93 obs. of 11 variables: $ Rank : num 1 2 3 4 5 6 7 8 9 10 ... $ Title : chr "Gisaengchung" "Green Book" "The Shape of Water" "Moonlight" ... $ Description : chr " Greed and class discrimination threaten the newly formed symbiotic relationship between the wealthy Park f"| __truncated__ " A working-class Italian-American bouncer becomes the driver of an African-American classical pianist on a "| __truncated__ " At a top secret research facility in the 1960s, a lonely janitor forms a unique relationship with an amphi"| __truncated__ " A young African-American man grapples with his identity and sexuality while experiencing the everyday stru"| __truncated__ ... $ Runtime : num 132 130 123 111 129 119 134 120 100 118 ... $ Genre : Factor w/ 6 levels "Action","Adventure",..: 4 3 2 6 3 4 3 3 4 3 ... $ IMDB_Ratings : num 8.6 8.2 7.3 7.4 8.1 7.7 8.1 7.7 7.9 8 ... $ Votes : num 550381 376701 370690 273379 419883 ... $ Directors : Factor w/ 81 levels "Alejandro G. Iñárritu",..: 9 55 28 4 72 1 68 6 50 71 ... $ Actors : Factor w/ 86 levels "Al Pacino","Albert Finney",..: 48 82 76 56 58 62 15 4 43 19 ... $ Metascore : num 31 7 22 34 28 22 31 21 24 23 ... $ Gross_Revenue: num 53.4 85.1 63.9 27.9 45.1 ...
Теперь самый важный шаг. Давайте экспортируем наш фрейм данных из R в формат CSV. Сделаем это следующим образом -
# lets export this data to a csv file write.csv(best_movies_data, "C:\\Users\\Kunal Kulkarni\\Desktop\\R data\\bestmoviesdata.csv", row.names = FALSE)
Давайте проверим, каково среднее время выполнения -
# average runtime print(avg <- mean(best_movies_data$Runtime))
Вы получите следующий результат -
[1] 137.6129
Давайте проверим сводку -
summary(best_movies_data)
Вы получите следующий результат -
Rank Title Description Runtime Genre IMDB_Ratings Votes
Min. : 1 Length:93 Length:93 Min. : 90.0 Action : 3 Min. :5.700 Min. : 4584
1st Qu.:24 Class :character Class :character 1st Qu.:118.0 Adventure: 8 1st Qu.:7.500 1st Qu.: 34774
Median :47 Mode :character Mode :character Median :129.0 Biography:18 Median :7.900 Median : 178591
Mean :47 Mean :137.6 Comedy :13 Mean :7.788 Mean : 343034
3rd Qu.:70 3rd Qu.:155.0 Crime : 9 3rd Qu.:8.100 3rd Qu.: 472817
Max. :93 Max. :238.0 Drama :42 Max. :9.200 Max. :1807653
Directors Actors Metascore Gross_Revenue
William Wyler : 3 Dustin Hoffman : 3 Min. : 1.00 Min. : 0.01
Billy Wilder : 2 Clark Gable : 2 1st Qu.:12.75 1st Qu.: 24.02
Clint Eastwood : 2 Laurence Olivier : 2 Median :20.00 Median : 54.58
David Lean : 2 Leonardo DiCaprio: 2 Mean :18.62 Mean : 81.70
Elia Kazan : 2 Marlon Brando : 2 3rd Qu.:25.25 3rd Qu.:110.20
Francis Ford Coppola: 2 Russell Crowe : 2 Max. :34.00 Max. :659.30
(Other) :80 (Other) :80 NA's :17 NA's :10
Давайте проанализируем извлеченные из Интернета данные -
Когда у вас есть нужные данные, вы можете выполнять различные задачи, такие как анализ данных, очистка данных, визуализация данных и извлечение из них важной информации. Итак, давайте проанализируем данные, которые мы только что скопировали, и сделаем из них что-то значимое, визуализировав эти данные.
Начнем с установки и загрузки пакета ggplot2. Пакет ggplot2 является частью семейства пакетов Tidyverse, и это очень мощный пакет, созданный для визуализации данных. Его часто считают грамматикой графики. Подробнее о пакете ggplot2 читайте здесь. Также вы можете использовать шпаргалку по ggplot2 для справки. Его можно бесплатно загрузить в RStudio или вы можете скачать здесь. Итак, приступим -
# The easiest way to install ggplot2 package is to install the whole tidyverse package:
install.packages("tidyverse")
# Alternatively, you can just install just ggplot2 package from CRAN :
install.packages("ggplot2")
# load the library
library(tidyverse)
#or
library(ggplot2)
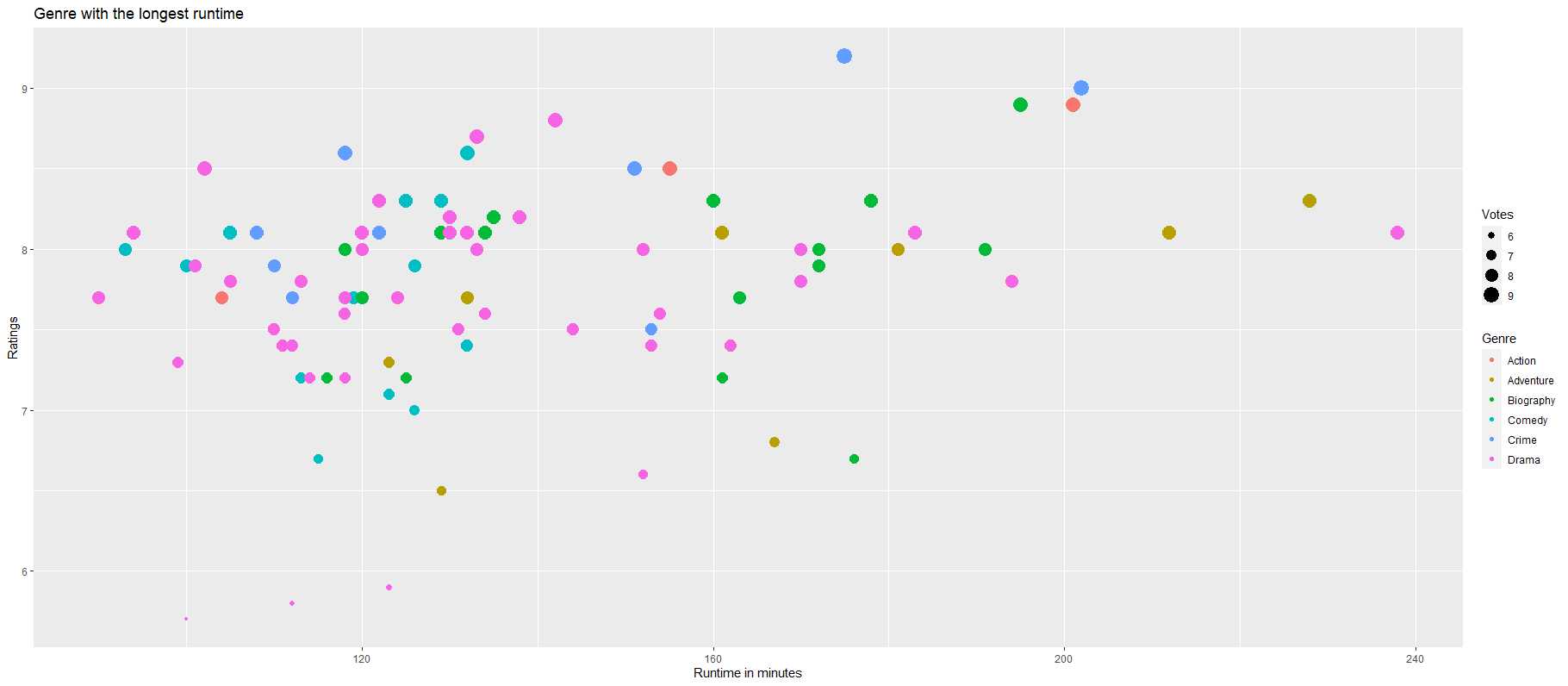
Основываясь на данных, которые мы только что соскребли, давайте посмотрим, какой фильм из какого жанра имеет самое продолжительное время просмотра -
# now lets analyze our data
#lets check which genre has the the longest runtime by plotting a graph of it
best_movies_data %>% ggplot(aes(Runtime, IMDB_Ratings, color = Genre, size = Votes, bins = 50)) + geom_point(aes(size = IMDB_Ratings)) + xlab("Runtime in minutes") + ylab("Ratings") + ggtitle("Genre with the longest runtime")
Вы получите следующий результат -
Давайте посмотрим, какой фильм заработал больше всего -
best_movies_data %>% ggplot(aes(Runtime, Gross_Revenue, color = Genre)) + geom_point() + ggtitle("Movie with the highest earning")
Вы получите следующий результат -

Основываясь на данных, которые мы только что проанализировали, давайте посмотрим, какой жанр приносит наибольший доход в миллионах -
# lets plot the graph of gross revenue and genre
best_movies_data %>% ggplot(aes(Genre, Gross_Revenue, color = Genre)) + geom_line() + ggtitle("Genre with the highest earnings")
Вы получите следующий результат -

Заключение
Я надеюсь, что эта статья даст вам базовый обзор того, как очистить данные из Интернета с помощью R и как их анализировать. Поскольку большинство данных, доступных в Интернете, представлены в неструктурированном формате, парсинг веб-страниц является действительно важным и обязательным навыком для любого специалиста по данным. Если у вас есть какие-либо вопросы по этой статье, дайте мне знать в разделе комментариев ниже.
Благодарю вас!