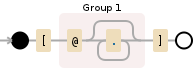
Из-за преобразований между pandoc-citeproc и латексом я хотел бы заменить это
[@Fotheringham1981]
с этим
\cite{Fotheringham1981}
.
Проблема обработки каждой скобки отдельно показана в воспроизводимом примере ниже.
x <- c("[@Fotheringham1981]", "df[1,2]")
x1 <- gsub("\\[@", "\\\\cite{", x)
x2 <- gsub("\\]", "\\}", x1)
x2[1] # good
## [1] "\\cite{Fotheringham1981}"
x2[2] # bad
## [1] "df[1,2}"
Видел похожую проблему решенную для С#, но не используя регулярное выражение R perly - есть идеи?
Редактировать:
Он должен быть в состоянии обрабатывать длинные документы, например.
old_rmd <- "$p = \alpha e^{\beta d}$ [@Wilson1971] and $p = \alpha d^{\beta}$
[@Fotheringham1981]."
new_rmd1 <- gsub("\\[@([^\\]]*)\\]", "\\\\cite{\\1}", old_rmd, perl = T)
new_rmd2 <- gsub("\\[@([^]]*)]", "\\\\cite{\\1}", old_rmd)
new_rmd1
## "$p = \alpha e^{\beta d}$ \\cite{Wilson1971} and $p = \alpha d^{\beta}$\n \\cite{Fotheringham1981}."
new_rmd2
## [1] "$p = \alpha e^{\beta d}$ \\cite{Wilson1971} and $p = \alpha d^{\beta}$\n\\cite{Fotheringham1981}."