
Этот пост написали Морган Фунтович, инженер по машинному обучению из Hugging Face, и Юфенг Ли, старший инженер-программист из Microsoft
Модели-преобразователи, используемые для обработки естественного языка (NLP), велики. BERT-base-uncased имеет ~ 110 миллионов параметров, RoBERTa-base имеет ~ 125 миллионов параметров, а GPT-2 имеет ~ 117 миллионов параметров. Каждый параметр представляет собой число с плавающей запятой, для которого требуется 32 бита (FP32). Это означает, что размеры файлов этих моделей огромны, как и потребляемая ими память. Не говоря уже обо всех вычислениях, которые должны произойти со всеми этими битами.
Эти проблемы затрудняют запуск моделей преобразователей на клиентских устройствах с ограниченными памятью и вычислительными ресурсами. Растущее понимание затрат на конфиденциальность и передачу данных делает вывод на устройстве привлекательным. Даже в облаке задержка и стоимость очень важны, и любое крупномасштабное приложение необходимо оптимизировать для них.
Квантование и дистилляция - это два метода, которые обычно используются для решения этих проблем с размером и производительностью. Эти методы дополняют друг друга и могут использоваться вместе. О дистилляции рассказывалось в предыдущем блоге Hugging Face. Здесь мы обсуждаем квантование, которое можно легко применить к вашим моделям без переобучения. Эта работа основана на оптимизированном логическом выводе с ONNX Runtime, о котором мы ранее рассказывали, и может дать вам дополнительный прирост производительности, а также разблокировать логический вывод на клиентских устройствах.
Квантование
Квантование приближает числа с плавающей запятой с числами с меньшей разрядностью, что значительно сокращает объем памяти и повышает производительность. Квантование может привести к потере точности, поскольку меньшее количество битов ограничивает точность и диапазон значений. Однако исследователи широко продемонстрировали, что веса и активации могут быть представлены с использованием 8-битных целых чисел (INT8) без существенной потери точности.
По сравнению с FP32 представление INT8 уменьшает объем хранилища данных и пропускную способность в 4 раза, что также снижает потребление энергии. С точки зрения производительности вывода целочисленные вычисления более эффективны, чем вычисления с плавающей запятой.
Более быстрый вывод
Производительность зависит от входных данных и оборудования. Для интерактивного вывода обычно используется небольшой размер пакета (количество входов). Длина последовательности (размер входных данных) зависит от сценария. В нашем тесте мы измерили размер пакетов 1 и 4 с длиной последовательности от 4 до 512. Современные процессоры поддерживают набор инструкций Advanced Vector Extensions 2 (AVX2) для высокопроизводительных вычислений. Последние процессоры Intel также поддерживают команды векторной нейронной сети AVX512 (AVX512 VNNI), которые предназначены для повышения производительности вывода INT8 при глубоком обучении. Мы протестировали производительность для BERT-base-uncased, RoBERTa-base и GPT-2 на двух машинах:
- AVX2: Intel (R) Xeon (R) CPU E5–1650 v4 @ 3,60 ГГц
- VNNI: Intel (R) Xeon (R) Gold 6252 CPU @ 2,10 ГГц
Для PyTorch мы использовали PyTorch 1.6 с TorchScript. Для PyTorch + ONNX Runtime мы использовали метод convert_graph_to_onnx Hugging Face и сделали вывод с помощью ONNX Runtime 1.4.
Мы увидели значительный прирост производительности по сравнению с исходной моделью благодаря использованию квантования ONNX Runtime:
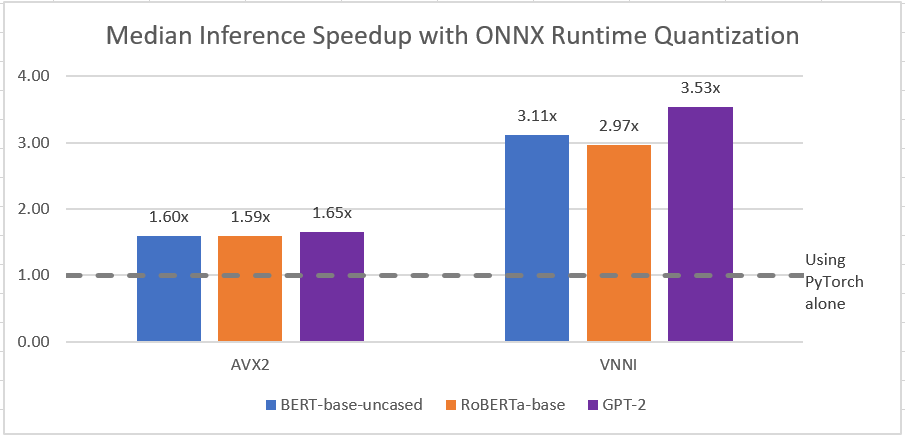
Ускорение по сравнению с исходной моделью PyTorch происходит как за счет квантования, так и за счет ускорения ONNX Runtime. Посмотрим, как это сломается. По сравнению с ONNX Runtime FP32, мы увидели, что квантование ONNX Runtime INT8 может повысить производительность вывода до 6 раз для всех трех моделей на машине VNNI. Мы видели меньшее, но все же значительное ускорение на машине AVX2.

Использование квантования INT8 в ONNX Runtime последовательно показало прирост производительности по сравнению с использованием квантования PyTorch INT8 на машинах AVX2 и VNNI:

Наши подробные данные опубликованы в конце этого поста.
Меньшие модели
После преобразования исходной модели PyTorch FP32 в формат ONNX FP32 размер модели был почти таким же, как и ожидалось. Затем мы применили соответствующий процесс квантования INT8 к обеим моделям. ONNX Runtime смогла квантовать больше слоев и уменьшить размер модели почти в 4 раза, получив модель примерно вдвое меньше, чем квантованная модель PyTorch.
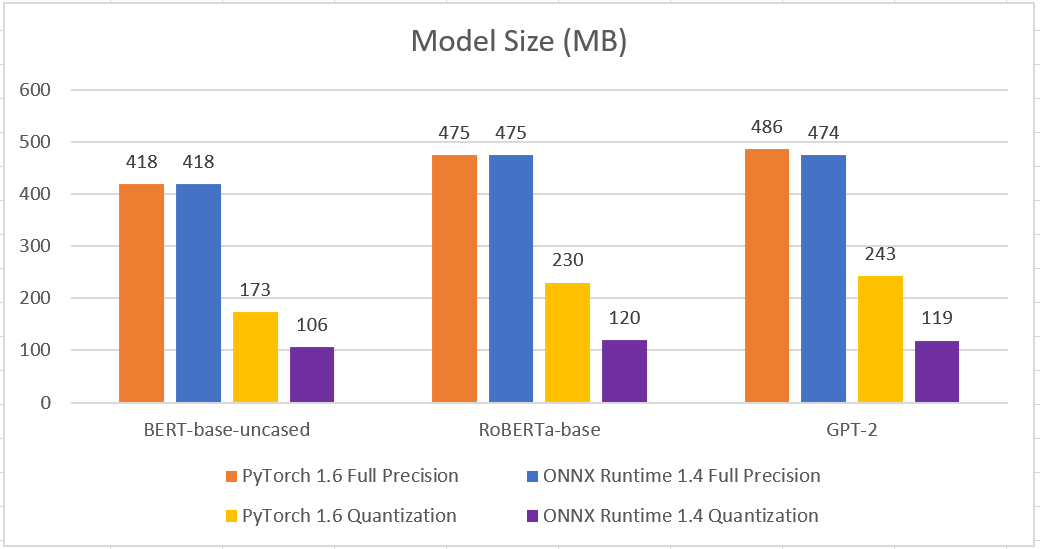
Не забывай о точности
Меньше и быстрее - это здорово, но мы также должны убедиться, что модель дает хорошие результаты. Учитывая, что точность зависит от задачи, мы взяли доработанную модель BERT для тестирования точности. Эта модель настраивается с использованием модели без корпуса BERT в Hugging Face Transformers для Microsoft Research Paraphrase Corpus (MRPC) task в тесте General Language Understanding Evaluation (GLUE). MRPC - это обычная задача НЛП для классификации языковых пар.
Точность измеряет количество правильно предсказанных значений среди общего предсказанного значения. Это не полная мера, поскольку она не работает, когда цена ложных негативов высока. Таким образом, мы также рассчитываем оценку F1, которая учитывает как точность, так и отзывчивость. Это более полезно, когда вы больше заботитесь о положительном классе. По сравнению с квантованием PyTorch, даже с меньшей моделью, квантование ONNX Runtime показало такую же точность и немного более высокую оценку F1.

Начать
Мы надеемся, что вы заинтригованы тем, что попробуете это сами. Вот инструкции, чтобы начать квантование ваших моделей обнимающего лица, чтобы уменьшить размер и ускорить вывод.
Шаг 1. Экспортируйте модель Hugging Face Transformer в ONNX
Библиотека Hugging Face Transformers включает инструмент, позволяющий легко использовать среду выполнения ONNX. Сценарий convert_graph_to_onnx.py расположен непосредственно в корне репозитория Transformers и принимает несколько аргументов, таких как модель, которую нужно экспортировать, и структура, из которой вы хотите экспортировать (PyTorch или TensorFlow), для создания связанного графа ONNX.
В сочетании с поддержкой квантования в выпуске ONNX Runtime 1.4 мы также обновили сценарий преобразования Hugging Face Transformers и добавили новый аргумент командной строки --quantize, чтобы легко экспортировать квантованные модели ONNX непосредственно из Transformers:
python convert_graph_to_onnx.py --framework pt --model bert-base-uncased --quantize bert-base-uncased.onnx
Это выведет как модель ONNX полной точности, так и квантованную модель ONNX.
Примечание: в настоящее время существует ограничение на размер модели менее 2 ГБ для использования параметра - quantize. В следующем выпуске ONNX Runtime это будет удалено.
Более подробную информацию вы можете найти в документации Hugging Face.
Шаг 2. Вывод со средой выполнения ONNX
Получив квантованную модель, вы можете вывести эту модель INT8 в ONNX Runtime так же, как обычно. ONNX Runtime предоставляет множество API-интерфейсов для разных языков, включая Python, C, C ++, C #, Java и JavaScript, поэтому вы можете интегрировать его в существующий стек обслуживания. Вот как будет выглядеть код Python:
session = onnxruntime.InferenceSession(onnx_model_path) session.run(None, ort_inputs)
Вы можете найти эти шаги в этой записной книжке в репозитории Hugging Face на GitHub. Эта записная книжка показывает сквозной поток с использованием точно настроенной модели Hugging Face BERT для задачи MPRC с данными GLUE.
Ресурсы
Квантование INT8 в среде выполнения ONNX показывает очень многообещающие результаты как для повышения производительности, так и для уменьшения размера модели на моделях преобразователя Hugging Face. Мы будем рады услышать любые отзывы или предложения, когда вы попробуете это в своих производственных сценариях. Вы также можете принять участие в наших репозиториях на GitHub (Библиотека Hugging Face Transformers и ONNX Runtime).
До сих пор мы обсуждали оптимизацию вывода. В будущих блогах мы расскажем об оптимизации обучения, чтобы помочь вам значительно сократить время, необходимое для обучения и настройки ваших моделей НЛП.
Результаты производительности
Задержки, указанные ниже, измеряются в миллисекундах. PyTorch относится к PyTorch 1.6 с TorchScript. PyTorch + ONNX Runtime относится к версиям PyTorch моделей Hugging Face, экспортированных и созданных с помощью ONNX Runtime 1.4.
BERT

RoBERTa

GPT-2
