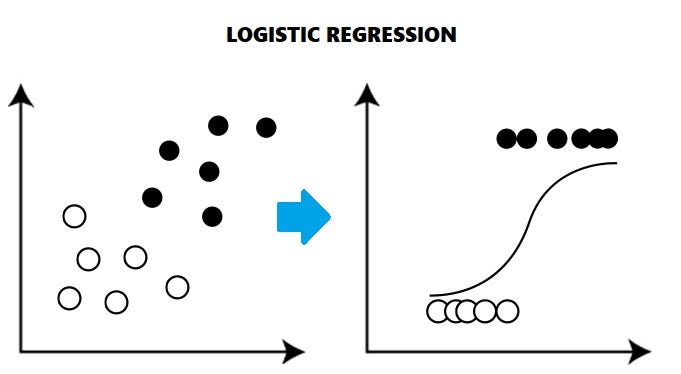
В моем предыдущем блоге я попытался объяснить линейную регрессию и то, как она работает. Давайте посмотрим, почему логистическая регрессия является одной из важных тем для понимания.
Вот ссылка на мою предыдущую статью о линейной регрессии на случай, если вы его пропустили.
Содержание
- Что такое логистическая регрессия?
- Типы логистической регрессии.
- Предположения логистической регрессии.
- Почему не линейная регрессия для классификации?
- Логистическая модель.
- Интерпретация коэффициентов.
- Отношение шансов и логит
- Граница решения.
- Функция затрат логистической регрессии.
- Градиентный спуск в логистической регрессии.
- Оценка модели логистической регрессии.
Давайте начнем

Что такое логистическая регрессия?
- Логистическая регрессия - это контролируемый статистический метод для определения вероятности зависимой переменной (классов, присутствующих в переменной).
- В логистической регрессии используются функции, называемые функциями логита, которые помогают вывести связь между зависимой переменной и независимыми переменными путем прогнозирования вероятностей или шансов возникновения.
- Логистические функции (также известные как сигмоидные функции) преобразуют вероятности в двоичные значения, которые в дальнейшем можно использовать для прогнозов.
Типы логистической регрессии:
- Двоичная логистическая регрессия:
Зависимая переменная имеет только два возможных результата / класса.
Пример - мужской или женский. - Полиномиальная логистическая регрессия:
Зависимая переменная имеет только два 3 или более возможных результата / класса без упорядочения.
Пример: прогнозирование качества еды (хорошее, отличное и плохое). - Порядковая логистическая регрессия:
Зависимая переменная имеет только два 3 или более возможных результата / классов с упорядочением. Пример: оценка от 1 до 5.
Теперь, когда ясны различные типы логистической регрессии, давайте посмотрим на предположения логистической регрессии. Эти предположения следует учитывать при построении модели.
Допущения логистической регрессии:
Несмотря на то, что логистическая регрессия относится к линейным моделям, она не делает никаких предположений относительно моделей линейной регрессии, например:
→ Она не требует линейной связи между зависимыми и независимыми переменными.
→ Условия ошибки не требует нормального распространения.
→ Гомоскедастичность не требуется.
Однако у него мало собственных предположений:
- Предполагается, что между независимыми переменными существует минимальная или отсутствует мультиколлинеарность.
Лучший способ проверить наличие мультиколлинеарности - выполнить VIF (коэффициент инфляции дисперсии). - Предполагается, что независимые переменные линейно связаны с журналом шансов.
Это можно проверить с помощью теста Бокса-Тидвелла. - Для хорошего прогноза предполагается наличие большой выборки.
- Предполагается, что наблюдения не зависят друг от друга.
- В непрерывных предикторах (независимых переменных) нет влиятельных значений (выбросов).
Это можно проверить с помощью IQR, z-score или визуализировать с помощью прямоугольных или скрипичных графиков. . - Логистическая регрессия с 2 классами, в которых зависимая переменная является двоичной, а для упорядоченной логистической регрессии требуется, чтобы зависимая переменная была упорядочена.
Также может возникнуть вопрос, почему мы не можем просто использовать линейную регрессию для задач классификации, кроме использования логистической регрессии. Давайте посмотрим ниже, почему мы не должны использовать линейную регрессию для задач классификации.

Почему не линейная регрессия для классификации?
Поскольку мы представили логистическую регрессию для решения проблем классификации, будь то двоичная классификация или проблема классификации нескольких классов, но почему мы не можем использовать линейную регрессию?
- Линейная регрессия предсказывает непрерывные переменные, такие как цена дома, а результат линейной регрессии может варьироваться от отрицательной бесконечности до положительной бесконечности.
- Поскольку прогнозируемые значения - это не значение вероятности, а непрерывное значение для классов, будет очень сложно найти правильный порог, который поможет различать классы.
- Предположим, вам повезло с порогом и вы определили правильный порог для задачи двоичного класса. Однако, если проблема будет многоклассовой, она не даст желаемого прогноза.
- В мультиклассовой задаче может быть n классов. Теперь каждый класс будет помечен от 0 до n.
Предположим, у нас есть 5 задач класса 0,1,2,3 и 4, которые эти классы не будут переносить или выиграли не будут иметь никакого значимого порядка. Однако они были бы вынуждены установить некую связь между зависимыми и независимыми признаками. - Более того, зависимые переменные будут взяты как непрерывные числа, а линия наилучшего соответствия будет проходить через среднее значение точек, давая выходное значение непрерывного значения, которое может опускаться ниже 0 и может превышать 4.
Логистическая модель
Все проблемы, упомянутые выше, решаются с помощью логистической регрессии.
Логистическая регрессия вместо подбора линии наилучшего соответствия сжимает выходные данные линейной функции между 0 и 1.

В формуле логистической модели,
когда b0 + b1X == 0, то p будет 0,5,
аналогично b0 + b1X ›0 , тогда p будет стремиться к 1 и
b0 + b1X ‹0, тогда p будет стремиться к 0.
Интерпретация коэффициентов
- Интерпретация весов отличается от линейной регрессии, поскольку выходные данные логистической регрессии находятся в диапазоне вероятностей от 0 до 1.
- Вместо коэффициента наклона (b), представляющего собой скорость изменения p при изменении x, теперь коэффициент наклона интерпретируется как скорость изменения «логарифмических коэффициентов» при изменении X.

Чтобы узнать об этом подробнее, перейдите по этой ссылке.
Теперь давайте разберемся, что такое логарифмические шансы.
Отношение шансов и логит
Отношение шансов определяется как отношение шансов при наличии B и шансов A при отсутствии B и наоборот.
Другими словами, Шансы - это отношение вероятности успеха к вероятности неудачи, а Логит - это просто логарифм отношения шансов.
Давайте понять это на примере:
Предположим, что вероятность успеха составляет 0,6.
Таким образом, вероятность неудачи будет (1–0,6) = 0,4
Шансы определяются из вероятностей и находятся в диапазоне от 0 до ∞.
Итак, теперь шансы (Успех) = p / (1-p) или p / q = 0,6 / 0,4 = 1,5
Кроме того, шансы ( Отказ) = 0,4 / 0,6 = 0,66667
Теперь, когда у вас есть базовое представление о том, что такое отношение шансов, я рекомендую вам перейти по этой ссылке, чтобы понять, как оно используется в логистической регрессии и математические выкладки, лежащие в основе этого.
Формула шансов:
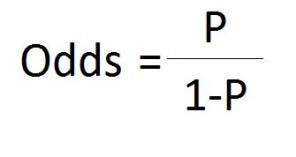
Если нам нужно соотношение шансов между бинарными классами, тогда:

Логит-функция - это просто журнал шансов, а формула имеет следующий вид:

В логистической регрессии мы можем рассчитать отношение шансов между классами:

Теперь, когда вы поняли, что такое отношение шансов, давайте посмотрим, какова граница принятия решения:
Граница решения
- Граница решения - это линия или поле, разделяющее классы.
- Алгоритм классификации - это поиск границы решения, которая помогает отличать классы идеально или близкие к идеальным.
- Логистическая регрессия определяет подходящую подгонку к границе решения, чтобы мы могли предсказать, какому классу будут соответствовать новые данные.
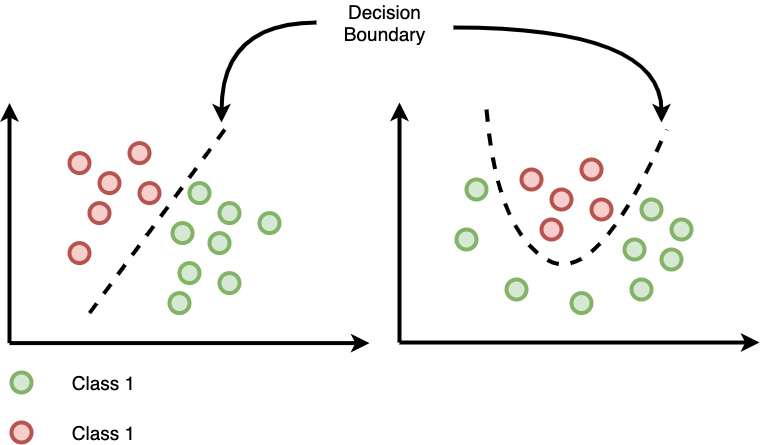
Я настоятельно рекомендую пройти по этой ссылке , чтобы понять математику того, как определяется граница принятия решения в логистической регрессии.
Теперь, когда вы поняли, что такое граница принятия решения и как она находится, давайте посмотрим на функцию стоимости логистической регрессии.
Функция затрат логистической регрессии

Функция стоимости - это функция, которая измеряет производительность модели машинного обучения для заданных данных.
Функция стоимости - это в основном вычисление ошибки между прогнозируемыми и ожидаемыми значениями. values и представляет его в виде единственного действительного числа.
Многие путают функцию затрат и функцию потерь, < br /> Проще говоря, функция затрат - это среднее значение ошибки n-выборки в данных, а функция потерь - ошибка для отдельных точек данных. Другими словами, Функция потерь предназначена для одного обучающего примера, Функция затрат - для всего обучающего набора.
Итак, когда станет ясно, что это за функция стоимости, давайте продолжим.
Мы знаем, что логистическая функция:
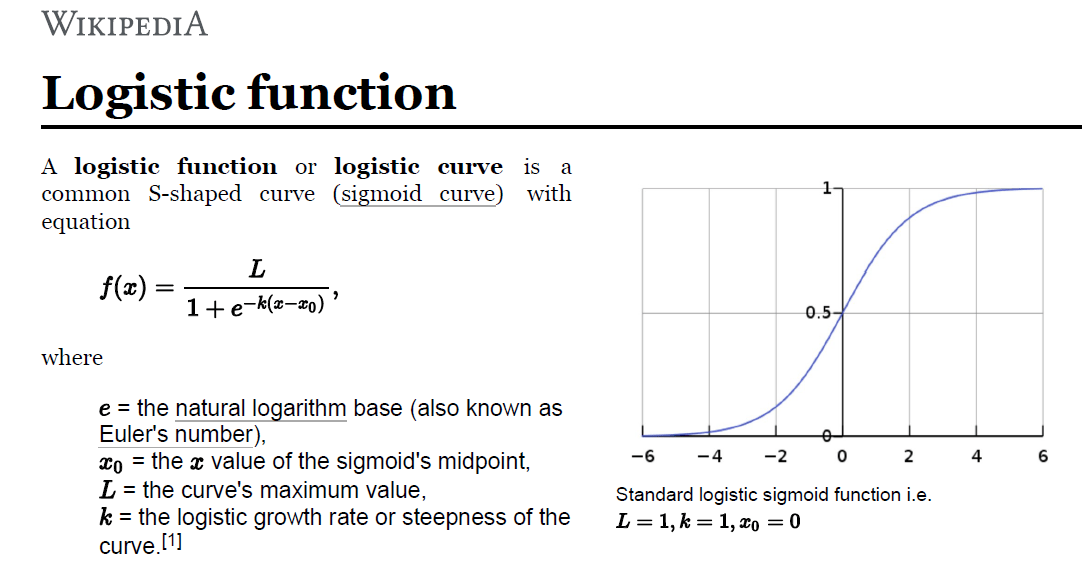
Основная задача для нас - найти лучший параметр (x) в приведенном выше уравнении, присутствующем на изображении, чтобы минимизировать ошибку.
Теперь, если вы видели математику за границей решения, вы будете знать, что параметр ( x) не ограничивается логистической функцией, он также вносит вклад в уравнение границы принятия решения.
Это очень похоже на линейную регрессию, определение функции стоимости для поиска ошибки, а затем выполнение градиентного спуска для обновления параметра и минимизации функции стоимости.
Но мы не можем использовать функцию стоимости модели линейной регрессии.
Почему мы не можем использовать функцию стоимости линейной регрессии?
Попытка использовать функцию стоимости модели линейной регрессии с использованием среднеквадратичной ошибки даст неконвексную функцию, которая даст график странной формы, который выглядит следующим образом.
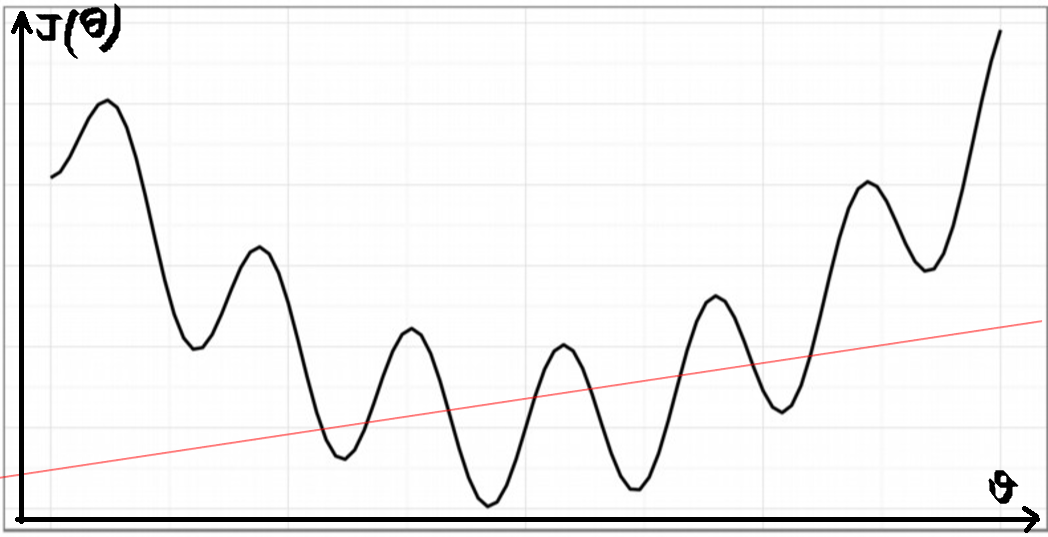
На этих графиках много локальных минимумов, поэтому функции стоимости очень сложно достичь глобального минимума и минимизировать ошибку.

Это происходит потому, что в логистической регрессии у нас есть сигмовидная функция, которая является нелинейной.
Вот почему функция затрат для логистической регрессии:
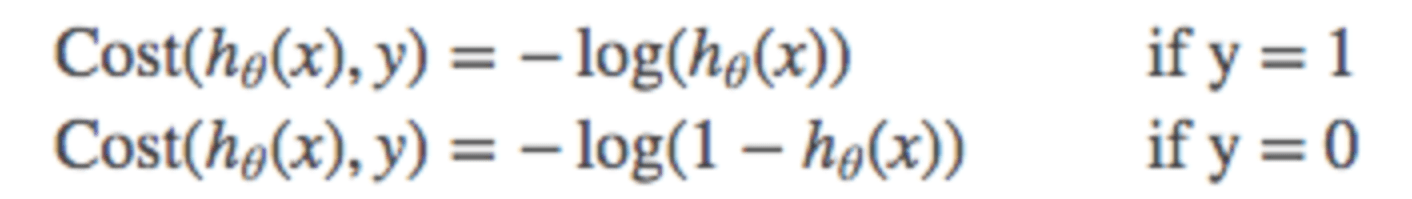

Если вы объедините два приведенных выше уравнения в одно, вы получите выпуклую функцию, и эта функция стоимости поможет модели логистической регрессии быстрее приблизиться к глобальному минимуму.

Вам должно быть интересно, почему в функции стоимости стоит знак минус (-),
Ну, если вы видите, значения, представленные в журнале, будут вероятностями от 0 до 1, Итак, значение log1 равно 0 и значение log0 - отрицательная (-) бесконечность.
Значения из функции стоимости всегда будут отрицательными, и поэтому мы добавляем к ней отрицательный знак (-).
Теперь, когда мы знаем функцию затрат логистической регрессии, давайте разберемся, как минимизировать ошибку, чтобы получить высокопроизводительную модель.
Градиентный спуск в логистической регрессии

Градиентный спуск - это алгоритм оптимизации, используемый для поиска значений параметров (коэффициентов) функции, которая минимизирует функцию стоимости (стоимость).
Чтобы узнать больше об этом и получить полное представление о градиентном спуске, я предлагаю прочитать Блог Джейсона Браунли.
Теперь, когда у вас есть интуиция о градиентном спуске, вы можете понять, почему нам нужно обновлять веса, чтобы достичь глобального минимума.
Шаги, за которыми следует градиентный спуск для получения функции более низкой стоимости:
Давайте посмотрим на логистическую (сигмовидную) функцию.
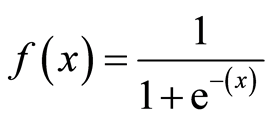
Здесь x = mx + b или x = b0 + b1x
→ Первоначально значения m и b будут равны 0, и в функцию будет введена скорость обучения (α).
Значение скорости обучения (α) взято очень маленьким, примерно от 0,01 до 0,0001.
Скорость обучения - это параметр настройки в алгоритме оптимизации, который определяет размер шага на каждой итерации при приближении к минимуму функции стоимости.
→ Затем вычисляется частная производная для функции затрат. После вычисления будет получено уравнение.

Ребята, знакомые с Calculus, поймут, как были сделаны производные, чтобы получить это уравнение.
Если вы не разбираетесь в исчислении, не волнуйтесь, просто поймите, как это работает, и этого будет более чем достаточно, чтобы интуитивно подумать, что происходит за кулисами, и тем, кто хочет знать процесс вывода, проверьте этот блог, в котором показан вывод функции стоимости.
→ После вычисления производных веса обновляются с помощью следующего уравнения.
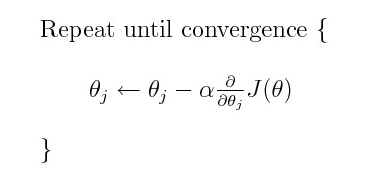
Что также можно записать как:

Если вы читали Блог Джейсона Браунли, возможно, вы поняли интуицию, лежащую в основе градиентного спуска, и то, как он пытается достичь глобального минимума (значение функции наименьшей стоимости).
Почему мы должны вычесть веса (m и b) из производной?
Градиент дает нам направление наискорейшего подъема функции потерь, а направление наискорейшего спуска противоположно к градиенту, поэтому мы вычитаем градиент из весов (m и b)
→ Процесс обновления весов будет продолжаться до тех пор, пока функция стоимости не достигнет идеального значения 0 или близкого к 0.
Теперь, когда вы создали модель с наилучшими характеристиками. Давайте посмотрим, как проверить качество модели.
Оценка модели логистической регрессии

После построения модели для нас очевидно, что мы должны проверить, насколько хорошо наша модель работает, насколько хорошо она соответствует нашим данным.
Один из способов сделать это - измерить, насколько хорошо вы можете предсказать зависимую переменную на основе нового набора независимых переменных.
- Значение R2 (R-Squared)
R-Squared, вычисленное для логистической регрессии, не то же самое, что R-Squared, вычисленное для моделей линейной регрессии.
Эти псевдо-R-Squared помогает измерить предсказательную силу модели.
Существует много различных способов вычисления значения R-Squared для логистической регрессии, однако ни один подход не признан лучшим. Но среди всех типов R- Значение в квадрате R-квадрат Макфаддена - лучший подход.
Перейдите по этой ссылке, чтобы просмотреть различные типы R-квадрат для логистической регрессии. - AIC (информационные критерии Akaike):
* AIC - это оценка степени соответствия модели.
* Каждый раз, когда мы создаем модель, мы теряем некоторую информацию, нет можно создать идеальную модель. AIC оценивает объем потери информации.
* Чем меньше значение AIC, тем меньше потеряна информация, что означает лучшую модель.
* Добавление переменных в модель не увеличивает значение AIC.
* Одним из видов использования AIC является также то, что он помогает в выборе модели. Мы можем подогнать все данные для обучения модели, сравнить значения AIC различных моделей и выбрать модель с лучшим значением AIC.
AIC = -2 / N * LL + 2 * K / N
Где N - количество выборок в обучающих данных, LL - Журнал правдоподобия модели на обучающих данных. и K - количество параметров в данных. - Другие методы включают матрицу неточностей, кривую Roc-Auc.
Вы можете прочитать о матрице неточностей и других связанных с ней показателях в моем блоге Расчет точности модели машинного обучения и Понимание« AUC -ROC Curve ».
Я надеюсь, что эта статья дает вам общее представление о модели логистической регрессии. В логистической регрессии гораздо больше, но мы коснулись ее только поверхностно.
Я рекомендую прочитать о логистической регрессии, поиске в Google, посмотрите видео на YouTube и попробуйте прочитать статьи, опубликованные на этом сайте.
С УЧЕНИЕМ !!!!!
Понравилась моя статья? Сделайте мне аплодисменты и поделитесь им, так как это повысит мою уверенность. Кроме того, я публикую новые статьи каждое воскресенье, так что оставайтесь на связи, чтобы в будущем написать статьи по основам науки о данных и машинного обучения.
Также свяжитесь со мной в LinkedIn.
