Когда и как использовать.

Pandas - это высокоэффективный и широко используемый инструмент анализа данных. Основная структура данных Pandas - это фрейм данных, который представляет данные в табличной форме с помеченными строками и столбцами. DataFrame предлагает множество мощных и гибких функций и методов, которые упрощают и ускоряют процесс очистки и анализа данных.
Проекты в области науки о данных обычно требуют, чтобы мы собирали данные из разных источников. Следовательно, в рамках подготовки данных нам может потребоваться объединить фреймы данных. Обе функции concat и merge используются для объединения фреймов данных. В этом посте я объясню 3 основных различия между ними.
1. Способ объединения
Функция Concat объединяет фреймы данных по строкам или столбцам. Мы можем думать об этом как о наборе нескольких фреймов данных.
Слияние объединяет фреймы данных на основе значений в общих столбцах. Функция слияния предлагает большую гибкость по сравнению с функцией concat, поскольку позволяет комбинировать на основе условия.

Предположим, у вас есть набор данных, содержащий транзакции по кредитным картам. У вас есть несколько столбцов с подробностями транзакции и один столбец с идентификатором клиента. Другой фрейм данных включает в себя более подробную информацию о клиенте, а также идентификатор клиента. Чтобы объединить эти два фрейма данных, мы можем объединить их в столбце «Идентификатор клиента», чтобы записи совпадали. Случай, в котором мы будем использовать concat, - это объединить фреймы данных, которые содержат транзакции по кредитным картам в 2019 и 2020 годах. Мы можем просто сложить их, используя функцию concat.
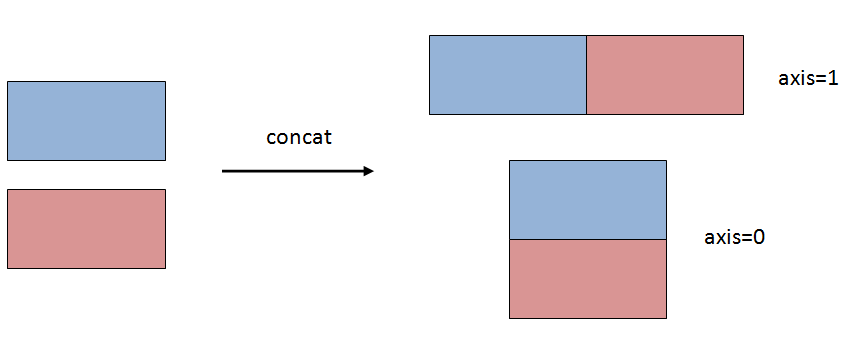
2. Параметр оси
Только функция concat имеет параметр оси. Слияние используется для объединения фреймов данных бок о бок на основе значений в общих столбцах, поэтому параметр оси не требуется.
Мы можем объединять фреймы данных по строкам (друг над другом) или столбцам (бок о бок) в зависимости от значения параметра оси. Значение по умолчанию для параметра оси - 0, что указывает на объединение по строкам.
Приведем несколько примеров.
import numpy as np
import pandas as pd
df1 = pd.DataFrame({
'A':[1,2,3,4],
'B':[True,False,True,True],
'C':['C1','C2','C3','C4']
})
df2 = pd.DataFrame({
'A':[5,7,8,5],
'B':[False,False,True,False],
'C':['C1','C3','C5','C8']
})

Ось = 0:

Ось = 1:

3. Присоединяйтесь к нам
Join - это параметр функции concat, а как параметр функции слияния. Их цель такая же, но методы работы немного отличаются.
Соединение указывает, как обрабатывать индексы в случае, если фреймы данных имеют разные индексы. Давайте создадим предыдущие фреймы данных с разными индексами.
df2 = pd.DataFrame({
'A':[5,7,8,5],
'B':[False,False,True,False],
'C':['C1','C3','C5','C8']},
index=[2,3,4,5]
)

Мы просто изменили индекс второго фрейма данных, передав значения индекса в параметр index.
Параметр соединения принимает два значения: внешнее и внутреннее.
- Внешний: взять все индексы (значение по умолчанию параметра join).
- Внутренний: брать только общие индексы

Мы берем все индексы, но во втором фрейме данных нет строк с индексом 0 и 1. Таким образом, значения во втором параметре данных заполняются NaN (маркер отсутствующего значения по умолчанию). Точно так же строки 4 и 5 в первом кадре данных заполнены значениями NaN.
Если мы установим соединение как внутреннее, будут отображаться только индексы, существующие в обоих фреймах данных. Итак, у нас не будет пропущенных значений из-за конкатенации.

Параметр how функции слияния работает аналогичным образом. Возможные значения для как: внутренний, внешний, левый, правый.
- inner: только строки с одинаковыми значениями в столбце, указанном параметром on (значение по умолчанию для параметра how)
- внешний: все строки
- left: все строки слева DataFrame
- справа: все строки из правого DataFrame
Рисунки ниже представляют концепцию того, как параметры более наглядно.
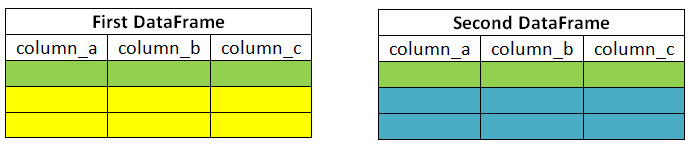
Прежде чем делать несколько примеров, давайте сначала вспомним наши фреймы данных.

Мы объединим df1 и df1 в столбце «C».

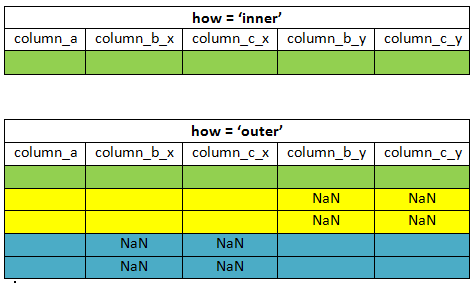
Значения, которые имеют как df1, так и df1 в столбце C, - это C1 и C3, поэтому только эти значения отображаются, когда как установлено как «внутреннее».
Как насчет внешнего?

Когда для параметра how выбран внешний, объединенный фрейм данных включает все значения столбца «C». Общие значения не дублируются, а значения, которых нет в df1 или df2, заполняются NaN.
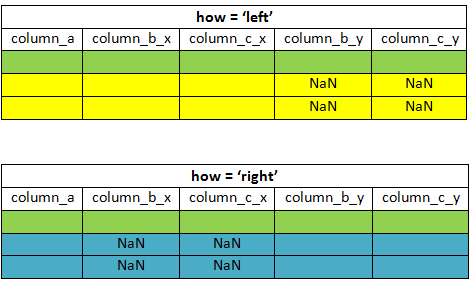
Когда в качестве параметра выбрано значение left, объединенный фрейм данных включает все строки из левого фрейма данных. Столбцы из правого фрейма данных заполняются значениями NaN, если значение в столбце «C» (столбец, который передается в параметр on) отсутствует в правом фрейме данных. Параметр Right используется редко, потому что мы можем просто изменить порядок фреймов данных в функции слияния (вместо (df1, df2) используйте (df2, df1)).

Спасибо за чтение. Пожалуйста, дайте мне знать, если у вас есть какие-либо отзывы.