
В статье2, опубликованной на прошлой неделе, мы разобрались в концепции и нюансах различных алгоритмов классификации. Чтобы вычеркнуть все t, имеет смысл на самом деле приступить к их кодированию для решения реальных проблем. Я пошел искать конкурс Kaggle, который не видел большого обсуждения, что означает очень мало участия сообщества. Почему-то первое, что привлекло мое внимание, было Предсказать, какие кандидаты придут на собеседование. И я взял наживку. Что ж, оказалось, что данные были не в лучшем виде, поэтому много времени было потрачено на их очистку.
Для тех из вас, кто не знаком с ML, я хотел представить результаты заранее, чтобы у вас была необходимая информация, прежде чем вы начнете блуждать:

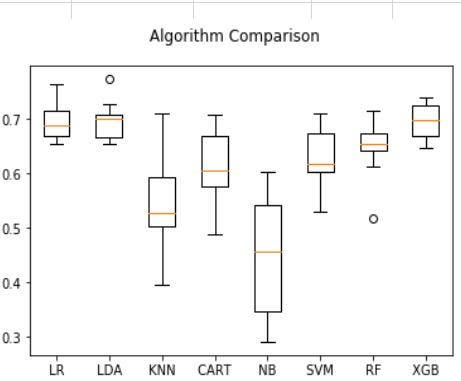
Таким образом, в этом случае XGB с точностью 70% работает лучше всего.
Я еще не расставил все точки над i, поэтому в следующей статье я сосредоточусь только на XGB, чтобы улучшить его производительность для этих данных. Что я намерен сделать, так это: во-первых, настроить гиперпараметры с помощью cvsearch, чтобы выбрать наилучшие значения, во-вторых, реализовать конвейер, чтобы избежать утечки данных, и в-третьих, внедрить ансамблевую модель, чтобы выжать из нее еще некоторые улучшения. Спасибо за чтение. Пожалуйста, не стесняйтесь связаться со мной в Twitter и LinkedIn.
Если вам нравится программировать, вы можете воспроизвести результаты, запустив код в своей собственной системе. Загрузите данные со страницы конкурса. Вырежьте и вставьте этот код в свою среду IDE и сохраните его в том же каталоге, что и файл данных. Я использовал python3 и scikit-learn.
#!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Created on Wed Apr 17 09:04:39 2019 @author: sshekhar """ import pandas as pd import numpy as np from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from xgboost import XGBClassifier from matplotlib import pyplot def clean_date(date): date = date.str.strip() date = date.str.split("&").str[0] date = date.str.replace('–', '/') date = date.str.replace('.', '/') date = date.str.replace('Apr', '04') date = date.str.replace('-', '/') date = date.str.replace(' ', '/') date = date.str.replace('//+', '/') return date df_raw = pd.read_csv('./Interview.csv') df_raw.head() # Removing empty variables # I'll go ahead and put all this work in a new df so I have an original copy if I need to go back for any reason. interview_df = df_raw.drop(['Unnamed: 23', 'Unnamed: 24', 'Unnamed: 25', 'Unnamed: 26', 'Unnamed: 27'], axis = 1) # Renaming variables to strings that are a little easier to work with. interview_df.columns = ['Date', 'Client', 'Industry', 'Location', 'Position', 'Skillset', 'Interview_Type', 'cand_ID', 'Gender', 'Cand_Loc', 'Job_Loc', 'Venue', 'Native_Loc', 'Permission', 'Unsch_meeting', 'Pre_interview_call', 'Alt_phone', 'Resume_Printout', 'Clarify_Venue', 'Interview_call_Letter', 'Expected', 'Attended', 'Martial_Status'] print(interview_df.shape) print(interview_df.head()) #Lets lowercase every column value and remove any space from them. interview_df = pd.concat([interview_df[c].astype(str).str.lower() for c in interview_df.columns], axis = 1) interview_df = pd.concat([interview_df[c].astype(str).str.strip() for c in interview_df.columns], axis = 1) #Clean the date column interview_df['Date'] = clean_date(interview_df['Date']) print(interview_df['Date'].unique()) #One or more rows have a null date value which has to be removed #Let's find out all the columns that has null values print(interview_df.loc[:, interview_df.isna().any()]) #Row# 1233 is a null row. So lets drop it interview_df.drop(interview_df.index[[1233]], inplace = True) #There are 3 more problems with the date column - one, some of the years are 2 digits and others are 4; two, some of the dates are projected in future 2020, 2021, 2022 and 2023; and three, some of the years have a trailing '/' #To address the problem# one, I will break-down the date column into three columns 'day', 'month' and 'year' and then add '20' to all the 2 digit year values. #To address the problem# two, I will replace all the future year values with '2019' because someone has done the '=!previous_value+1'. #I will ignore the third problem because solution to first one will take care of it interview_df['day'] = interview_df['Date'].str.split("/").str[0] interview_df['month'] = interview_df['Date'].str.split("/").str[1] interview_df['year'] = interview_df['Date'].str.split("/").str[2] print(interview_df['year'].unique()) future_years=['2020','2021','2022','2023'] print(interview_df.loc[interview_df['year'].isin(future_years)]) interview_df['year'].replace(['16', '15','2020','2021','2022','2023'], ['2016', '2015','2019','2019','2019','2019'], inplace = True) # Finally I create the new date column using cleaned values interview_df['date'] = pd.to_datetime(pd.DataFrame({'year': interview_df['year'],'month': interview_df['month'],'day': interview_df['day']}), format = '%Y-%m-%d', errors='coerce') #Makesure interview_df date column is of datetime data type interview_df['date'] = interview_df['date'].astype('datetime64[D]') interview_df.drop(['Date', 'year', 'month', 'day'], axis = 1, inplace = True) for c in interview_df.columns: print(c) print(interview_df[c].unique()) print(interview_df.dtypes) #The next column - Client has three redundant entries; lets replace them #aon hewitt gurgaon with aon hewitt, hewitt with aon hewitt and standard chartered bank chennai with standard chartered bank interview_df['Client'].replace(['standard chartered bank chennai', 'aon hewitt gurgaon', 'hewitt'], ['standard chartered bank', 'aon hewitt', 'aon hewitt'], inplace = True) #Industry column looks OK but Location has one bad entry interview_df['Location'].replace(['- cochin-'], ['cochin'], inplace = True) #Candidate ID column has 'Candidate' word. We don't need it, so lets replace it and make the column type as int64. interview_df['cand_ID'].replace(['candidate'], [' '],regex=True, inplace=True) interview_df['cand_ID'].astype(int) #Lets address Interview type column interview_df['Interview_Type'].replace(['scheduled walk in', 'sceduled walkin'],['scheduled walkin', 'scheduled walkin'], inplace = True) # I wonder why cochin is always messed up? interview_df['Cand_Loc'].replace(['- cochin-'], ['cochin'], inplace = True) interview_df['Job_Loc'].replace(['- cochin-'], ['cochin'], inplace = True) interview_df['Venue'].replace(['- cochin-'], ['cochin'], inplace = True) interview_df['Native_Loc'].replace(['- cochin-'], ['cochin'], inplace = True) #Permission column has few values like na, nan, not yet and yet to confirm, I will replace them all with to be decided (tbd) interview_df['Permission'].replace(['na', 'not yet', 'yet to confirm', 'nan'],['tbd', 'tbd', 'tbd','tbd'], inplace = True) #Lets do the same with the next two columns interview_df['Unsch_meeting'].replace(['na', 'nan', 'not sure', 'cant say'],['tbd', 'tbd', 'tbd','tbd'], inplace = True) interview_df['Pre_interview_call'].replace(['nan', 'na','no dont'],['tbd', 'tbd','no'], inplace = True) #For Alt_phone column lets replace all the na, nan etc with no interview_df['Alt_phone'].replace(['nan', 'no i have only thi number','na'],['no', 'no','no'], inplace = True) #For Resume_Printout,Clarify_venue and Interview_call_Letter we will replace all the na variants with tbd interview_df['Resume_Printout'].replace(['nan', 'no- will take it soon','not yet','na'],['tbd', 'tbd','tbd','tbd'], inplace = True) interview_df['Clarify_Venue'].replace(['nan', 'no- i need to check','na'],['tbd', 'tbd','tbd'], inplace = True) interview_df['Interview_call_Letter'].replace(['nan', 'havent checked','need to check','not sure','yet to check','not yet','na'],['tbd', 'tbd','tbd','tbd','tbd','tbd','tbd'], inplace = True) #Expected column has misleading entries, lets make them uniform - yes or no interview_df['Expected'].replace(['uncertain', 'nan','11:00 am','10.30 am'],['no', 'no','yes','yes'], inplace = True) #Takecare of skillset column #For now dropping it interview_df.drop(['Skillset'], axis = 1, inplace = True) #There is one other information that we want to extract from date column. For the purpose of interview lets assume that interviewees will be more comfortable with interview falling on Friday, Saturday or Sunday. So I will add another column called extn_weekend to the dataframe ## Adding more time columns date_series = interview_df.date interview_df.date = pd.to_datetime(date_series, infer_datetime_format=True, errors='coerce') for n in ('Year', 'Month', 'Week', 'Day', 'Weekday_Name', 'Dayofweek', 'Dayofyear'): interview_df['Date'+'_'+n] = getattr(date_series.dt, n.lower()) interview_df['extn_weekend'] = np.where(interview_df['Date_Dayofweek']>4,1,0) #Now lets look at the unique values again and convert catergorical values to numerical #Later on we will convert those numerical values to normalized spread, so that we get values between -1 to 1. Most algorithms will like it that way print(interview_df.dtypes) #It makes sense to categorize the following columns - Permission, Unsch_meeting, Pre_interview_call, Resume_Printout, Clarify_Venue, Interview_call_Letter; manually as they have values - yes, no and tbd. I want to make sure that yes is more important indicator as compared to tbd, which is more important than no. interview_df['Permission'] = pd.Categorical(interview_df['Permission']) interview_df['Permission'].cat.set_categories(['no', 'tbd', 'yes'], ordered=True, inplace=True) interview_df['Unsch_meeting'] = pd.Categorical(interview_df['Unsch_meeting']) interview_df['Unsch_meeting'].cat.set_categories(['no', 'tbd', 'yes'], ordered=True, inplace=True) interview_df['Pre_interview_call'] = pd.Categorical(interview_df['Pre_interview_call']) interview_df['Pre_interview_call'].cat.set_categories(['no', 'tbd', 'yes'], ordered=True, inplace=True) interview_df['Resume_Printout'] = pd.Categorical(interview_df['Resume_Printout']) interview_df['Resume_Printout'].cat.set_categories(['no', 'tbd', 'yes'], ordered=True, inplace=True) interview_df['Clarify_Venue'] = pd.Categorical(interview_df['Clarify_Venue']) interview_df['Clarify_Venue'].cat.set_categories(['no', 'tbd', 'yes'], ordered=True, inplace=True) interview_df['Interview_call_Letter'] = pd.Categorical(interview_df['Interview_call_Letter']) interview_df['Interview_call_Letter'].cat.set_categories(['no', 'tbd', 'yes'], ordered=True, inplace=True) #We will address two other columns in terms of importance to the model - Expected and Attended interview_df['Expected'] = pd.Categorical(interview_df['Expected']) pd.Categorical(interview_df['Expected']) interview_df['Expected'].cat.set_categories(['no', 'yes'], ordered=True, inplace=True) interview_df['Attended'] = pd.Categorical(interview_df['Attended']) pd.Categorical(interview_df['Attended']) interview_df['Attended'].cat.set_categories(['no', 'yes'], ordered=True, inplace=True) #Now we are ready to convert all string values to numerics #interview_df_with_dummies = pd.get_dummies(interview_df) obj_df = interview_df.select_dtypes(include=['object']).copy() #Lets drop candidate id from here, as it doesn't make sense to onehotencode it. We will add it back. obj_df.drop(['cand_ID'], axis = 1, inplace = True) #obj_df.head() #obj_df.columns #interview_df.dtypes modeling_df = pd.get_dummies(obj_df) modeling_df.head() cat_df = interview_df.select_dtypes(include=['category']).copy() #obj_df_onehotencoding['Permission'] = cat_df.Permission.cat.codes #obj_df_onehotencoding.drop(['Permission'], axis = 1, inplace = True) for col in cat_df.columns: modeling_df[col] = cat_df[col].cat.codes #Assess if any column is missing from interview_df print(interview_df.columns, interview_df.dtypes) for c in modeling_df.columns: print(c) #Now add the missing columns in extn_weekend, lets just add it from interview_df modeling_df['cand_ID'] = interview_df['cand_ID'] modeling_df['cand_ID'] = pd.to_numeric(modeling_df["cand_ID"]) modeling_df['extn_weekend'] = interview_df['extn_weekend'] print(modeling_df.dtypes, modeling_df.head() ) #Now we are ready to try different algorithms #Lets split the data into 80% for training and 20% for validation Y=modeling_df['Attended'] modeling_df.drop(['Attended'], axis = 1, inplace = True) print(modeling_df.dtypes) X=modeling_df # prepare models models = [] models.append(( ' LR ' , LogisticRegression())) models.append(( ' LDA ' , LinearDiscriminantAnalysis())) models.append(( ' KNN ' , KNeighborsClassifier())) models.append(( ' CART ' , DecisionTreeClassifier())) models.append(( ' NB ' , GaussianNB())) models.append(( ' SVM ' , SVC())) models.append(( ' RF ',RandomForestClassifier())) models.append(( ' XGB ' , XGBClassifier())) # evaluate each model in turn results = [] names = [] scoring = 'accuracy' for name, model in models: kfold = KFold(n_splits=10, random_state=7) cv_results = cross_val_score(model, X, Y, cv=kfold,scoring=scoring) results.append(cv_results) names.append(name) msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std()) print(msg) # boxplot algorithm comparison fig = pyplot.figure() fig.suptitle( ' Algorithm Comparison ' ) ax = fig.add_subplot(111) pyplot.boxplot(results) ax.set_xticklabels(names) pyplot.show()