Все мы сталкиваемся с проблемой спама в наших почтовых ящиках. Давайте создадим программу классификатора спама на Python, которая может определить, является ли данное сообщение спамом! Мы можем сделать это, используя простую, но мощную теорему теории вероятностей, называемую теоремой Байя. Математически это выражается как

Постановка задачи
У нас есть сообщение m = (w 1, w 2,...., W n), где (w 1 , w 2,...., w n) - набор уникальных слов, содержащихся в сообщении. Нам нужно найти

Если мы предположим, что появление слова не зависит от всех других слов, мы можем упростить приведенное выше выражение до

Чтобы классифицировать, мы должны определить, какой из них больше
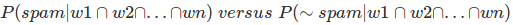
1. Загрузка зависимостей

Мы собираемся использовать NLTK для обработки сообщений, WordCloud и matplotlib для визуализации и pandas для загрузки данных, NumPy для генерации случайных вероятностей для разделения на поезд-тест.
2. Загрузка данных

Столбцы «Безымянный: 2», «Безымянный: 3» и «Безымянный: 4» не требуются, поэтому мы их удалим. Мы переименовываем столбец «v1» в «ярлык», а «v2» - на «сообщение». «Ham» заменяется на 0, а «spam» заменяется на 1 в столбце «label». Наконец, мы получаем следующий фрейм данных.

3. Сплит-тест
Чтобы протестировать нашу модель, мы должны разделить данные на набор данных поезда и набор данных для тестирования. Мы будем использовать набор данных поезда, чтобы обучить модель, а затем она будет протестирована на тестовом наборе данных. Мы будем использовать 75% набора данных как набор данных поезда, а остальное как набор тестовых данных. Выбор этих 75% данных является равномерно случайным.

4. Визуализация данных
Давайте посмотрим, какие слова чаще всего повторяются в спам-сообщениях! Для этого мы воспользуемся библиотекой WordCloud.

Это приводит к следующему

Как и ожидалось, эти сообщения в основном содержат такие слова, как «БЕСПЛАТНО», «звонок», «текст», «мелодия звонка», «запрос приза» и т. Д.
Точно так же wordcloud радиолюбительских сообщений выглядит следующим образом:

5. Обучение модели.
Мы собираемся реализовать две техники: мешок слов и TF-IDF. Я объясню их одну за другой. Давайте сначала начнем с Мешка слов.
Предварительная обработка: перед началом обучения мы должны предварительно обработать сообщения. Прежде всего, мы сделаем все символы строчными. Это потому, что «бесплатно» и «бесплатно» означают одно и то же, и мы не хотим рассматривать их как два разных слова.
Затем мы токенизируем каждое сообщение в наборе данных. Токенизация - это задача разбить сообщение на части и отбросить знаки препинания. Например:

Такие слова, как вперед, идет, иду, указывают на одно и то же действие. Мы можем заменить все эти слова одним словом вперед. Это называется стеммингом. Мы собираемся использовать Porter Stemmer, известный алгоритм стемминга.


Затем мы переходим к удалению стоп-слов. Стоп-слова - это слова, которые очень часто встречаются в любом тексте. Например, такие слова, как «the», «a», «an», «is», «to» и т. Д. Эти слова не дают нам никакой информации о содержании текста. Таким образом, не имеет значения, удаляем ли мы эти слова из текста.
Необязательно: вы также можете использовать n-граммы для повышения точности. На данный момент мы имели дело только с 1 словом. Но когда два слова соединяются вместе, значение полностью меняется. Например, «хорошо» и «плохо» имеют противоположное значение. Предположим, что текст содержит «не хорошо», лучше рассматривать «не хорошо» как один признак, а не «не хорошо» и «хорошо». Поэтому иногда точность повышается, когда мы разбиваем текст на токены из двух (или более) слов, а не только на слово.

Мешок слов. В модели "Мешок слов" мы находим "частоту термина", то есть количество вхождений каждого слова в наборе данных. Таким образом, для слова w,

а также

TF-IDF: TF-IDF расшифровывается как Term Frequency-Inverse Document Frequency. В дополнение к Term Frequency мы вычисляем обратную частоту документа.
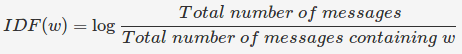
Например, в наборе данных есть два сообщения. «Привет, мир» и «привет, фу, бар». TF («привет») - 2. IDF («привет») - это журнал (2/2). Если слово встречается много, это означает, что слово дает меньше информации.
В этой модели каждое слово имеет оценку TF (w) * IDF (w). Вероятность каждого слова рассчитывается как:


Аддитивное сглаживание. Что, если мы встретим слово в тестовом наборе данных, которое не является частью набора данных поезда? В этом случае P (w) будет 0, что сделает P (spam | w) неопределенным (так как нам пришлось бы разделить на P (w), который равен 0. Помните формулу?). Чтобы решить эту проблему, мы вводим аддитивное сглаживание. При аддитивном сглаживании мы добавляем число альфа к числителю и складываем число классов, умноженное на число классов, для которых вероятность находится в знаменателе.
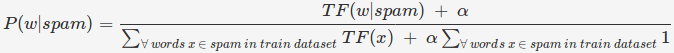
При использовании TF-IDF
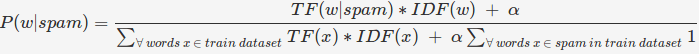
Это сделано для того, чтобы наименьшая вероятность любого слова теперь была конечным числом. Добавление в знаменатель делает итоговую сумму всех вероятностей слов в спам-письмах равной 1.
Когда альфа = 1, это называется сглаживанием Лапласа.
6. Классификация
Для классификации данного сообщения сначала мы его предварительно обрабатываем. Для каждого слова w в обработанном сообщении мы находим произведение P (w | спам). Если w не существует в наборе данных поезда, мы берем TF (w) как 0 и находим P (w | spam), используя приведенную выше формулу. Мы умножаем этот продукт на P (спам). В результате получается P (спам | сообщение). Аналогично находим P (ветчина | сообщение). В зависимости от того, какая из этих двух вероятностей больше, входному сообщению присваивается соответствующий тег (спам или любительский). Обратите внимание, что мы не делим на P (w), как указано в формуле. Это потому, что оба числа будут разделены на это, и это не повлияет на сравнение между ними.
7. Окончательный результат

Ресурсы
- Набор данных: https://www.kaggle.com/uciml/sms-spam-collection-dataset
- Http://machinelearning.wustl.edu/mlpapers/paper_files/icml2003_RennieSTK03.pdf
- Токенизация: https://nlp.stanford.edu/IR-book/html/htmledition/tokenization-1.html
- Построение: https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
- Стоп-слова: https://nlp.stanford.edu/IR-book/html/htmledition/dropping-common-terms-stop-words-1.html
- Https://www.youtube.com/watch?v=PrkiRVcrxOs
- Ссылка на код: https://github.com/tejank10/Spam-or-Ham