Введение
Вы, вероятно, испытали хотя бы один или два раза в своей жизни, когда вы вошли в свой туалет и увидели полную катастрофу. Особенно, когда их приходится сортировать и систематизировать.
Но представьте себе мир, в котором вы можете просто управлять машиной или использовать пульт дистанционного управления, и все будет в порядке, а ваши белые и цветные футболки будут аккуратно сложены, разве это не удивительно?
Это в основном работа Hadoop в больших данных.
Позвольте мне провести вас через это
Во-первых, мне нужно, чтобы вы знали, что данные повсюду, и их обработка становится все более важной. Однако масштабная обработка данных может быть достигнута только при использовании масштабируемой архитектуры, способной управлять высокопроизводительными вычислительными системами.
В последнее десятилетие технологии больших данных пережили бум использования. С этим ростом растет спрос на более масштабируемые инструменты для обработки больших объемов данных. Традиционные базы данных не могут обеспечить достаточную производительность, поскольку они полагаются на один компьютер и один поток ЦП.
Это означает, что они не могут обрабатывать огромный объем данных, генерируемых современными передовыми приложениями, такими как программы искусственного интеллекта и машинного обучения.
В этой статье мы рассмотрим некоторые популярные инструменты обработки больших данных, такие как Hadoop, которые помогут решить эти проблемы с помощью их масштабируемых архитектур, а также способы их применения в реальных сценариях.
Что такое Hadoop?
Hadoop — это фреймворк для обработки больших объемов данных. Это проект Apache, что означает, что его исходный код доступен для общественности, и каждый может внести свой вклад.
Инфраструктура Hadoop управляет хранением и обработкой в кластерах компьютеров, что позволяет запускать приложения на тысячах или даже миллионах узлов для решения ресурсоемких задач.
По своей сути Hadoop использует модель программирования MapReduce (также известную как параллельная обработка), которая была впервые определена сотрудниками Google Джеффри Дином и Санджаем Гемаватом в 2004 году. MapReduce разбивает сложные задачи на более мелкие, которые могут обрабатываться параллельно несколькими серверами.
Программное обеспечение также включает в себя набор инструментов с открытым исходным кодом, которые помогут вам обрабатывать ваши данные, в том числе HDFS (распределенная файловая система Hadoop), которая обеспечивает хранение больших файлов на нескольких серверах.
И MapReduce, и HDFS имеют открытый исходный код, что означает, что любой может получить доступ к их коду, чтобы увидеть, как они работают, или внести свой вклад в их разработку.
Hadoop применялся для решения таких задач, как веб-индексирование, извлечение информации из текстовых документов, машинное обучение, интеллектуальный анализ данных и прогнозная аналитика.
Что такое ХДФ
HDFs (распределенная файловая система Hadoop) — это базовая файловая система платформы Hadoop. Он предоставляет механизм для управления хранением и обработкой очень больших наборов данных в распределенной среде. Это также способствует эффективному обмену данными между несколькими приложениями, работающими на платформе.
Распределенная файловая система Hadoop разработана для хранения больших файлов на нескольких компьютерах в организации или корпорации. HDFS имеет несколько функций, которые делают ее пригодной для обработки больших объемов данных:
- Отказоустойчивость — HDFS гарантирует, что данные реплицируются между несколькими узлами, чтобы избежать единичных сбоев в кластере. Если один узел выходит из строя, другой узел берет на себя его обязанности, в то время как выполняется ремонт для скорейшего восстановления работы.
- Масштабируемость — поскольку данные распределяются между несколькими узлами в кластере, можно легко увеличить емкость хранилища, добавив дополнительные узлы в сеть. По мере увеличения объема данных вы можете добавлять в свой кластер дополнительные узлы, и HDFS автоматически распределяет данные между ними.
- Целостность данных — файлы хранятся в блоках с вычислением контрольных сумм для каждого блока, чтобы ни один блок не был поврежден или потерян
HDFS хранит данные в больших блоках, называемых блоками (128 МБ). Он хранит данные на нескольких серверах с использованием коэффициента репликации 3, что означает, что у него есть три копии каждого блока в разных местах, поэтому в случае сбоя одного сервера два других сервера могут продолжать предоставлять доступ к данным.
HDF состоит из двух компонентов
- Узел имени
- Узел данных
Узел имени: узел NameNode служит центром файловой системы HDFS. Он поддерживает иерархическое дерево каждого файла в файловой системе и отслеживает, где в кластере хранятся данные каждого файла. Информация, содержащаяся в этих файлах, не сохраняется им (узел имени)
Узел даты: здесь хранится ваш HDF.

Пример
Распознавание изображений
Если бы мы искали изображение, разбитое на сотни файлов, Hadoop сначала нужно было бы узнать, где находятся данные. Затем он запросит узел имени, чтобы определить все места, где находится файл данных. Получив эту информацию, он отправит задание каждому из узлов. Каждый процессор индивидуально читает свой входной файл, ищет изображение, а затем выводит результат на локальный выход.
Что такое MapReduce
MapReduce — это алгоритм, который разбивает большую задачу на более мелкие, а затем объединяет их для получения результата. Этот алгоритм полезен, когда вам нужно быстро обработать огромные объемы данных.
MapReduce — это модель программирования для обработки и создания больших наборов данных с помощью параллельного распределенного алгоритма в кластере. Например, вы можете использовать MapReduce для сортировки данных, хранящихся на многих серверах, разбивая работу на несколько частей и распределяя их по кластеру. Когда все части завершены, они объединяются в одну часть выходных данных.
Существует несколько этапов использования MapReduce:
- Этап ввода — отдельные отсортированные потоки от каждого преобразователя объединяются в один большой отсортированный поток.
- Этап разделения или сопоставления. Ключ каждой входной записи разбивается на несколько частей, называемых «разделителями». Значения каждого разделителя группируются по соответствующему ключевому значению; эти группы называются «осколками».
- Этап перетасовки — выходные данные функции карты сортируются по ключам и отправляются в нужный редуктор; этот процесс происходит за пределами любого заданного узла, поэтому при необходимости его можно распределить между несколькими узлами.
- Этап редукции: на стадии редукции записывается каждая пара ключ-значение, которая проходит через входной поток, а затем обновляется статистика о том, сколько ключей было обработано.
- Этап вывода: результат всех операций с картой записывается в виде одного файла (конечный результат).
Давайте подробнее рассмотрим, как это работает.
Назовите статистический анализ
Дэниел Сэм Грейс
Сэм Байо Анкуш
Анкуш Байо Грейс
Нам нужно проанализировать, сколько раз появлялось каждое имя.
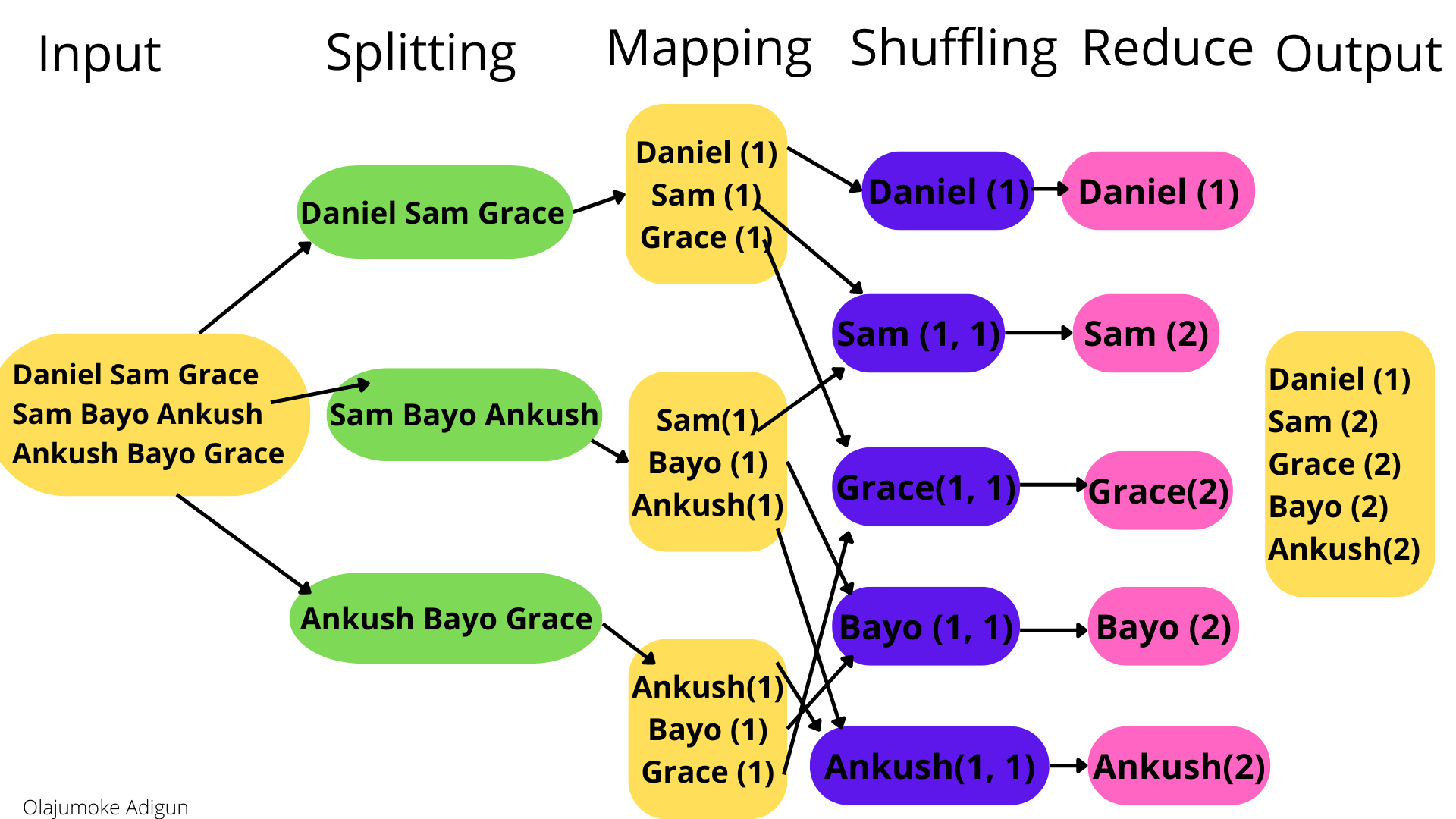
С помощью MapReduce вы можете выполнять такие анализы, как продажи в магазине, веб-анализ и анализ приложений и многое другое.
Почему Hadoop — это здорово
Проблема с большими данными заключается в том, что они слишком велики для традиционных баз данных. Хотя реляционные базы данных были созданы для работы с объемом информации, генерируемой малым бизнесом, они просто не приспособлены для обработки огромных объемов данных, генерируемых сегодня.
На самом деле, у некоторых компаний так много данных, что их склады заполнены жесткими дисками, и у них нет возможности упорядочить или получить доступ к своей информации.
Решением является Hadoop (сокращение от Apache Hadoop), разработанная программная среда с открытым исходным кодом. Проблема с большими данными заключается в том, что они слишком велики для традиционных баз данных. Хотя реляционные базы данных были созданы для работы с объемом информации, генерируемой малым бизнесом, они просто не приспособлены для обработки огромных объемов данных, генерируемых сегодня.
Кроме того, они оптимизированы для структурированной информации, такой как транзакции продаж или заказы клиентов. На собственном серверном оборудовании одна база данных SQL может легко переполниться неструктурированными источниками данных, такими как веб-страницы, изображения и документы, даже если в общей сложности задействовано всего несколько тысяч гигабайт (гигабайты = 1 миллиард байт).
Преимущества Хадуп
- Во-первых, это масштабируемость — это означает, что Hadoop может обрабатывать большие объемы данных (порядка терабайт).
- Обеспечивает отказоустойчивость и отказоустойчивость в случае сбоя или недоступности одного сервера;
- Вы можете использовать его без предоплаты (кроме оборудования).
Проблема с большими данными и почему Hadoop — это решение
Большие данные относятся к наборам данных, которые слишком велики или сложны для эффективной обработки традиционными системами реляционных баз данных. Таким образом, организациям нужны новые инструменты, способные обрабатывать эти огромные объемы информации, сохраняя при этом скорость, масштабируемость и надежность. Hadoop предлагает несколько решений:
- Он предоставляет распределенную систему хранения, способную хранить и извлекать большие наборы данных, сохраняя при этом отказоустойчивость на нескольких компьютерах в инфраструктуре организации.
Заключение
Сочетание Hadoop и больших данных обеспечивает мощную масштабируемую инфраструктуру для анализа огромных объемов данных. Хотя существует множество других технологий, которые можно использовать для анализа данных (например, SQL), ни одна из них не предлагает такой же гибкости, как Hadoop.