Сохранение информации — еще один способ запоминания

В переполненном конференц-зале редактор сделал паузу, когда понял, что один из журналистов не делает никаких заметок. Удивленный, он спросил, почему, и еще более удивленный, он слушал, как журналист повторял каждое слово, как будто оно было где-то записано. Вскоре после этого журналист Соломон Шерешевский посетил специалиста по запоминанию и спросил его, почему он должен был делать записи, а не запоминать все, что он слышал. На самом деле, он хотел знать, почему все должны делать заметки, а не полагаться исключительно на свои воспоминания. Александр Лурия, психолог, общался с Саломоном почти 30 лет. За это время Александр стал свидетелем того, как Соломон мог легко использовать свою память, чтобы читать целые стихи, последовательности чисел и слов, сложные математические формулы и целые отрывки из книг, написанные на иностранных языках. Александр задокументировал все свои переживания и беседы с Саломоном, которые вдохновили многих других исследовательских проектов, эссе, фильмов,и даже рассказа великого Хорхе Луиса Борхеса. Это также вдохновило на создание статьи о мнемонистах, рекуррентных нейронных сетях и неизбежной тенденции объяснять интуицию, стоящую за алгоритмами машинного обучения.
Введение
Мнемонисты — это люди со странной способностью запоминать обширные фрагменты информации, такие как списки чисел или отрывки из книги. Некоторые, такие как Соломон Шерешевский, рождаются такими, в то время как другие полагаются на правила или методы, называемые мнемоникой, которые помогают им запоминать длинные списки данных. Являясь естественными или обученными, мнемонисты могут запоминать такие большие наборы данных, что любому нормальному человеку их запоминание покажется невозможным. В последнем Чемпионате памяти США финальное соревнование состояло в запоминании порядка 104 покерных карт всего за 5 минут! Как они это делают? Хотя объяснение того, что происходит внутри их мозга, определенно сложно и не является целью этой статьи, провести аналогию между мнемонистами и рекуррентными нейронными сетями возможно. Начнем с искусственных нейронных сетей; что это такое и как они работают?
Обычные ИНС
Искусственная нейронная сеть (ИНС) представляет собой группу связанных единиц (нейронов), которые получают и передают сигналы. То, как работает ИНС, напоминает процесс, в котором взаимодействуют нейроны в нашем мозгу. Все начинается, когда набор входных данных проходит через сеть блоков, распределенных по разным слоям. Затем входные данные преобразуются в соответствии с функцией активации каждой единицы, а также весами и смещениями, которые соединяют все единицы. Последний слой сети берет выходные данные и сравнивает их с реальными наблюдаемыми данными. Различия между выходными и реальными данными используются для корректировки весов и смещений, которые соединяют все единицы измерения. Эта настройка повторяется несколько раз, пока ИНС не будет обучена. Таким образом, процесс обучения в ИНС состоит из нескольких итераций, в которых веса и смещения сети изменяются до тех пор, пока ИНС не сможет воспроизвести наблюдаемые данные с достаточной степенью достоверности. Процесс обучения, который происходит в мозгу, и тот, который закодирован в ИНС, определенно отличаются. Это различие было главной темой обсуждения во многих других исследовательских проектах и статьях. Несмотря на свои различия, ИНС являются основой глубокого обучения и ключом к множеству приложений и процессов искусственного интеллекта, используемых каждый день.
То, как работает ИНС, широко освещалось в других источниках, и было бы неплохо иметь четкое представление об ИНС, прежде чем продолжать читать это. Вот очень краткое объяснение того, как работает ИНС: На рисунке 1 показана схема ИНС с входным слоем, одним скрытым (или промежуточным) слоем и выходным слоем. Обратите внимание, как каждая единица связана через сеть весов и смещений. Два входных значения переходят в единую единицу в скрытом слое после умножения и суммирования с соответствующими весами и смещениями. Оказавшись внутри устройства, функция активации преобразует входное значение в соответствии с предварительно установленной функцией. Выход этого модуля теперь является входом для следующего модуля в выходном слое. На этот раз также применяются веса и смещения следующего слоя, а также функция активации. Таким образом, после того как a1 умножается и суммируется с весом и смещением, оно переходит в последнюю единицу, где преобразуется в a2 после применения функции активации.

Объясненный ранее процесс известен как распространение распространения. С другой стороны, обратное распространение — это процесс, в котором веса и смещения изменяются в соответствии с различиями между выходными значениями и наблюдаемыми значениями. Эти различия распространяются на все уровни и соединения в ИНС. Цикл прямого и обратного распространения повторяется несколько раз, пока разница между выходными и наблюдаемыми значениями не будет минимизирована. Результат — это группа весов и смещений, которые берут входные данные и преобразуют их в наблюдаемые значения или их хорошее приближение.
Рекуррентные нейронные сети
До этого момента описанная нейронная сеть может распознавать закономерности и предсказывать выходные данные в соответствии с набором входных значений. До сих пор ничего не было сказано о порядке представления входных данных. А последовательность? Может ли ИНС, подобная описанной, знать, какой следующий номер следует за длинным списком чисел? Что, если порядок входных данных имеет значение? В рекуррентной нейронной сети (RNN) порядок представления данных влияет на параметры сети. Как мнемонисты, RNN обучены воспроизводить длинные последовательности данных. Затем RNN используются для прогнозирования следующего значения. Существует много типов RNN, которые более продвинуты, чем то, что будет объяснено здесь: например, Долгосрочная кратковременная память (LSTM) и Gated Recurrent Units (GRU). Некоторыми приложениями RNN являются прогнозирование временных рядов, языковое моделирование, распознавание речи и машинный перевод. Эти приложения похожи по способу представления входных данных: RNN берет последовательность чисел или слов и предсказывает, какое из них является следующим наиболее вероятным. В отличие от ИНС, у РНС есть какая-то память, которая использует предыдущие значения, чтобы предсказать, какое из них будет следующим. Как работает эта память?
Обычные диаграммы RNN аналогичны рисунку 2. Свернутая версия RNN показывает сеть, которая содержит входной слой с 4 единицами, рекуррентный скрытый слой и выходной слой. Этот повторяющийся скрытый слой взаимодействует с каждым из элементов входного слоя и переносит информацию от каждого из этих взаимодействий в следующий. Это показано в развернутой версии RNN.
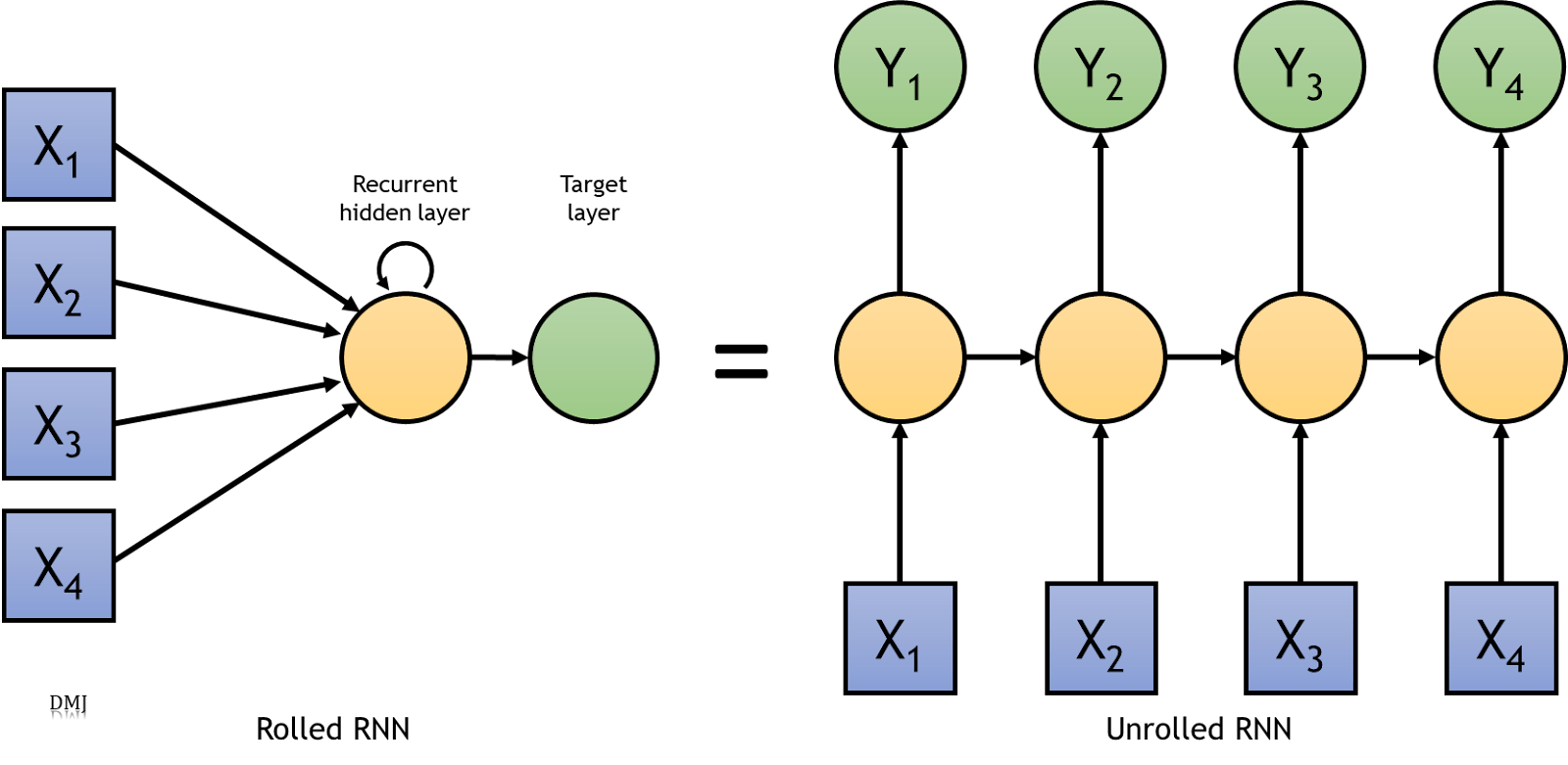
Предыдущая диаграмма используется во многих источниках и статьях, связанных с RNN. Альтернативная визуализация представлена на рисунке 3. В отличие от того, что делается в ИНС, единицы входного слоя не считываются одновременно. Вместо этого каждый из них последовательно переходит в блок скрытого слоя. Это означает, что X1 соединяется со скрытым слоем с помощью весов (w1) и смещений (b1), а затем преобразуется в соответствии с функцией активации единицы измерения. После этого X2 следует тому же процессу, а затем X3 и X4. Ключом к RNN является то, как информация передается от одного устройства к другому, что представляет собой компонент «памяти» этой сети. Выход каждого из взаимодействий со скрытым слоем (a1,a2,a3) также включается в расчеты. Обратите внимание, как каждая из входных единиц умножается на вес, суммируется по смещению, а затем суммируется с «рекуррентным весом» (wr), который является выходом предыдущей единицы. Итак, a2 зависит от X2, w1, b1 и a1; a3 зависит от X3, w1, b1 и a2; а a4 зависит от X4, w1, b1 и a3. Память в RNN состоит из отслеживания значения активации из предыдущего блока ввода.

Еще одна важная характеристика RNN заключается в том, что ее веса и смещения распределяются между всеми слоями. Это означает, что все единицы входного слоя умножаются и суммируются с одинаковыми весами и смещениями, тогда как в ИНС каждое соединение между единицами на разных уровнях имеет разный вес. Эта деталь важна в момент обучения RNN: меньше весов и меньше смещений означает, что нужно настроить меньше параметров, и, как правило, это приведет к более быстрому процессу обучения.
Как и в случае с другими типами сетей, RNN может включать не один, а несколько модулей скрытого уровня. Наличие большего количества единиц увеличит количество весов и смещений, связанных со скрытым слоем. Однако увеличение количества блоков также может повысить производительность RNN. На рис. 4 показана схема RNN, которая содержит два модуля на скрытом уровне и два модуля на входном уровне. Важно отметить, что скрытый слой теперь содержит 6 весов и 2 смещения. Есть 2 веса, связанные со связями между входным слоем и скрытым слоем, и 4 «повторяющихся» веса, которые связаны со связями между единицами в скрытом слое. Как объяснялось ранее, эти 4 веса несут информацию, которая выводит единицы скрытого слоя при их взаимодействии с входным слоем.

Больше различий между ANN и RNN
Одним из многочисленных применений нейронных сетей является построение регрессионной модели с целью ее последующего использования для прогнозирования новых значений. Это также можно сделать с помощью линейной и нелинейной регрессии. В наборе данных, подобном показанному на рисунке 5, ИНС может моделировать поведение между x и y таким образом, что после обучения модели новые значения >y (цель) можно рассчитать по новым значениям x(вход). Результатом обучения ИНС является набор весов и смещений, способных воспроизвести поведение входных и целевых переменных. Чем более нелинейна эта связь, тем больше элементов и слоев требуется в ИНС. Итак, в этом случае ИНС будет использовать как входные, так и целевые переменные. С другой стороны, RNN моделирует поведение целевой переменной как последовательный список чисел.
В RNN целевые переменные группируются в соответствии с длиной последовательности. В примере, показанном на рис. 5, используется длина последовательности, равная 3. Это означает, что в качестве входных данных используются три значения, а следующее четвертое значение является целевым. Область, выделенная пунктирным квадратом, содержит 7 точек данных. Для длины последовательности, равной 3, можно определить 4 набора входных и целевых значений. В каждом из этих наборов вход состоит из 3 значений, а цель содержит одно значение. Таким образом, длина последовательности определяет, сколько входных данных и целей можно использовать для обучения и тестирования RNN. Например, в наборе данных из 1000 точек и длине последовательности 5 количество пар входных/целевых данных будет равно 995.

На рис. 5 показано, что процесс подготовки данных в RNN отличается от процесса, применяемого к ANN. В RNN данные должны быть разделены в соответствии с длиной последовательности перед вводом в сеть. Как только данные будут готовы, RNN будет обрабатывать каждую из последовательностей отдельно. В каждом из этих процессов RNN сравнивает выходные данные с целевым значением. Как только все последовательности будут обработаны, а их выходные данные рассчитаны и сравнены с целевыми, RNN будет иметь меру того, насколько далеко от ожидаемого значения. Эта разница затем используется в процессе обратного распространения для определения новых весов и смещений.
Прямое распространение
Первым шагом в любой сети является распространение входных данных по слоям с использованием весов и смещений. Рисунок 6 содержит графический пример того, как этот процесс работает в RNN. В этом примере показана RNN с одноэлементным скрытым слоем и входными данными, состоящими из 3 значений. Функция активации для этого слоя представляет собой гиперболический тангенс (tanh). После скрытого слоя идет выходной слой с одним блоком и линейной функцией активации. Все уравнения и числа, написанные красным цветом, представляют собой расчеты, которые выполняются на каждом из агрегатов. Обратите внимание, что первая единица скрытого слоя не содержит значения для wr. Однако это значение всегда присутствует для остальных юнитов. wr представляет компонент памяти этой сети, поскольку он отслеживает предыдущую активацию.

Как и в других типах сетей, следующим шагом после прямого распространения является сравнение выходных данных с целевым значением. Это делается с помощью функции ошибки, такой как среднеквадратическая ошибка (MSE). Эта функция вычисляется для каждой из пар выход-цель, а затем функция потерь вычисляет одно значение потерь для итерации. Потери показывают, насколько результат близок к ожидаемому значению. Значение потерь также используется в начале процесса обратного распространения.
Обратное распространение
Обратное распространение или обратное распространение, пожалуй, самая запутанная часть искусственной нейронной сети. Основная идея этого процесса состоит в том, чтобы распределить разницу между результатами и целями в сети весов и смещений. Одним из способов распределения или обратного распространения потерь является использование градиентного спуска. Возможно, это не лучшее решение для всех случаев. Тем не менее, это один из наиболее распространенных алгоритмов обратного распространения. Здесь важно отметить, что обратное распространение — не единственный алгоритм обучения нейронных сетей. Задача нахождения наилучшей комбинации весов и смещений по сути является задачей оптимизации, которую можно решить с помощью эволюционных алгоритмов или любого другого типа алгоритмов оптимизации без производных. Объяснение процесса обратного распространения с помощью градиентного спуска — хороший способ понять, что происходит, но его не следует воспринимать как единственное решение.
Обратное распространение во времени (BPTT)
Процесс обратного распространения в RNN аналогичен тому, который выполняется в ANN. Однако в RNN процесс обратного распространения учитывает наличие нескольких процессов прямого распространения на каждой итерации. Таким образом, обратное распространение выполняется для каждой последовательности, идущей назад во времени, и поэтому оно называется BPTT. Детали процесса лучше объясняются в этой Python Notebook и в других источниках. Основным результатом BPTT является градиент для каждого из весов и смещений. Затем этот градиент вычитается из исходного значения веса/смещения для создания нового веса/сдвига, который будет использоваться в следующей итерации. В конце процесса веса и смещения должны быть скорректированы таким образом, чтобы выходные данные RNN напоминали целевые значения.
Обучение RNN — непростая задача. Хотя градиенты легко рассчитать с помощью алгоритма BPPT, производная функции потерь может быть очень большой по сравнению со скрытыми активациями в более ранние моменты времени. Поскольку функция потерь очень чувствительна к этим небольшим изменениям, она становится прерывистой (Суцкевер, 2013). В дополнение к этому, RNN также представляет проблемы исчезающих и взрывающихся градиентов. Это можно решить, обрезав градиенты до значения по умолчанию.
Практические примеры
Этот раздел содержит несколько примеров применения RNN в задачах регрессии. Как упоминалось ранее, это не единственное применение RNN, но это хорошая отправная точка для понимания процесса, прежде чем приступать к другим, более сложным задачам. Все приведенные здесь примеры полностью объяснены в этой блокноте Python. Помимо полных объяснений, эта записная книжка Python содержит пошаговое построение RNN. Эта RNN содержит один скрытый слой (tanh) и выходной слой (identity) с одним модулем. Количество юнитов в скрытом слое можно изменить в коде. На рис. 7 показана схема RNN. Такая RNN, как эта, обычно называется vanilla RNN, и она будет использоваться в следующих примерах.

Функция sin(x)
Это очень простой первый пример. Идея состоит в том, чтобы найти RNN, способную воспроизвести поведение функции sin(x). Основным входом является таблица со значениями x и y в соответствии с sin(x). На рис. 8 показан график этой функции. В следующих разделах представлены различные подходы к моделированию этой функции: ванильный RNN, Keras RNN и Многослойный регрессор персептрона (sklearn).

Ванильный РНН
Перед внедрением этой RNN необходимо сделать несколько подготовительных действий. Первый — преобразовать данные в подходящий формат, чтобы алгоритм RNN мог их прочитать. Данные, представленные на рисунке 8, могут быть извлечены в виде таблицы с двумя столбцами: один для независимой переменной и один для зависимой переменной. Входные данные для RNN состоят только из столбца зависимой переменной. Длина последовательности определяет, сколько разделов используется для разделения столбца. На рис. 9 показано, что в наборе данных с 7 значениями длина последовательности, равная 3, дает 4 выборки. Это образцы, которые будут введены в RNN.

Первая подфункция, включенная в код Vanilla RNN Python, называется «PrepareData». Эта подфункция берет файл .csv с таблицей, такой же, как та, что показана в левой части рис. 9, и преобразует ее в несколько массивов. Это обычная практика в алгоритмах машинного обучения, которая используется для определения эффективности алгоритма без генерации новых данных. Последним важным моментом на этом этапе является необходимость масштабирования данных перед их подачей в RNN. В этом примере все данные масштабируются до минимального значения -1 и максимального значения 1. Однако можно использовать и другие типы процессов масштабирования.
Прежде чем масштабированные данные поступят в RNN, необходимо инициализировать параметры. Процесс инициализации присваивает случайные значения весам и нулям смещениям. Для этого важно знать архитектуру RNN, поскольку она будет определять, сколько значений потребуется при инициализации. В этом примере используются 5 параметров: wx, bx, wr, wy и by. Первые три связаны со скрытым слоем, а последние два — с выходным слоем. После инициализации параметров входные данные поступают в сеть и запускают цикл прямого распространения, расчета потерь и обратного распространения.
На рис. 10 показан результат обучения ванильной RNN с использованием функции sin(x). Vanilla RNN довольно хорошо приближает целевые точки. Важно отметить, что результаты, показанные на рис. 11, были перемасштабированы для соответствия входным данным. Это означает, что после вычисления вывода значения были преобразованы из масштабирования [-1,1] в исходную форму. В этом первом примере Vanilla RNN используется длина последовательности, равная 2, и одна единица в скрытом слое. В этой конфигурации RNN содержит 2 веса и 1 смещение для скрытого слоя и один вес и одно смещение для выходного слоя. Всего 5 параметров.

На рис. 11 показано поведение функции потерь в процессе обучения RNN. Функция потерь начинается с высокого значения и постепенно уменьшается, пока не достигнет минимума. На этом этапе важно отметить, что способ определения Vanilla RNN делает результаты очень чувствительными к начальным значениям параметров. Другие реализации RNN (например, от Keras) решают эту проблему. В этой Vanilla RNN разные начальные комбинации параметров могут привести к разным результатам.

Керас
На рис. 12 показаны результаты обучения RNN с использованием библиотеки Keras. Эти результаты сравнимы с результатами, представленными на рисунке 10, поскольку RNN содержит одну единицу в скрытом слое с функцией активации tanh и длиной последовательности, равной 2. То, как работают RNN, определенные в Keras, делает их менее зависимыми от начального набор параметров, что является проблемой, которая не решается в Vanilla RNN.

Многослойный регрессор персептрона (MLPR)
Функция sin(x) также может быть смоделирована с помощью обычной ИНС. Однако для настройки потребуется больше параметров. ИНС, показанная на рисунке 14, использует три скрытых слоя по 25, 15 и 5 единиц в каждом. Важно помнить, что эта ИНС принимает в качестве входных данных значения x, представленные на горизонтальной оси. Эта ИНС не учитывает порядок целевых значений, поскольку она работает непосредственно с отношением между входом (x) и выходом (y).

Дебит нефти скважины
Все примеры, представленные до этого момента, относятся к функции sin(x), которая является очень простой функцией. Однако RNN также можно использовать для представления более сложного поведения. Следующий раздел содержит данные, относящиеся к месячному дебиту нефтяной скважины. Этот пример является хорошим способом тестирования RNN, поскольку данные не следуют какому-либо шаблону или циклу и не могут быть смоделированы с помощью функции.
Ванильный РНН
Для этого приложения Vanilla RNN длина последовательности равна 15, а количество единиц в скрытом слое равно 1 (рис. 14). Обратите внимание, что, хотя в данных есть четкая тенденция склонения, точки выглядят действительно некоррелированными. Тем не менее, RNN может сопоставить некоторые точки. Худшая часть приходится на последний период, когда результаты RNN значительно далеки от цели.

На рис. 15 показаны результаты обучения Vanilla RNN для воспроизведения даты дебита нефти, но на этот раз с использованием длины последовательности 5 и 2 единиц в скрытом слое. Результаты кажутся немного лучше, чем раньше. Как и в случае с другими типами нейронных сетей, настройка метапараметров имеет большое значение. В Блокноте Jupyter, связанном с этой статьей, можно попробовать различные комбинации единиц измерения в скрытом слое, длину последовательности, скорость обучения и количество эпох.

Керас
Сценарий, аналогичный только что представленному, был запущен с использованием Keras (рис. 16). Он имеет 2 элемента в скрытом слое и длину последовательности 5. Результаты аналогичны ванильному RNN даже на финальном этапе.

Многоуровневый регрессор персептрона
На рис. 17 показаны результаты обучения обычной ИНС воспроизведению набора данных дебита нефти. В этом примере используются три скрытых слоя размером 100, 50 и 25 единиц каждый. Общее поведение дебита нефти хорошо представлено ИНС. Однако, как и в предыдущем примере, ИНС не распознает мелкие детали данных. Эта производительность ближе к результатам, которые можно получить с помощью нелинейной регрессии, чем с RNN.

Заключение
Основная цель этой статьи состояла в том, чтобы дать четкое объяснение того, как работают RNN и чем их процесс прямого и обратного распространения немного отличается от обычного ANN. Основная характеристика RNN связана с ее рекуррентными единицами. Эти блоки отслеживают предыдущие активации, что дает RNN особый тип памяти. Эта функция позволяет RNN воспроизводить более детальное поведение, чем обычные ANN. Представленные примеры показывают, как ИНС хорошо воспроизводит общую тенденцию. Однако если стоит задача воспроизведения поточечных значений, то лучше перейти на RNN. Это объясняет, почему RNN используются в языковом моделировании, распознавании речи и других подобных приложениях. Таким образом, хотя поведение RNN не так впечатляет, как навыки Соломона Шерешевского, они все же могут быть использованы для решения многих проблем, с которыми приходится сталкиваться ежедневно. В конце концов, маловероятно, чтобы кто-то мог вспомнить разговоры 12-летней давности. Полезнее иметь алгоритм, который может угадать, каким будет следующее слово в текстовом сообщении, написанном в спешке.
Рекомендации
- Риос, Л. М., и Сахинидис, Н. В. (2013) Оптимизация без производных: обзор алгоритмов и сравнение программных реализаций. Журнал глобальной оптимизации.
- Суцкевер, И. (2013). Обучение рекуррентных нейронных сетей. Кандидатская диссертация. Университет Торонто
- Вербос, П. Дж. (1990) Обратное распространение во времени: что оно делает и как это делать. Труды IEEE 78 (10), 1990, 1550–1560.
- Манфре, Д. (2021). Действительно ли искусственные нейронные сети учатся?. К науке о данных
- Фосетт, Л. (1993) Основы нейронных сетей. Пирсон