Прежде чем углубиться в статистику, давайте посмотрим, что такое наука о данных и ее жизненный цикл.
Наука о данных — это практика использования статистических и вычислительных методов для извлечения идей и знаний из данных. Он включает в себя сбор, очистку, обработку, анализ и визуализацию данных для выявления закономерностей и тенденций, которые могут использоваться в бизнес-решениях, научных исследованиях и других приложениях.
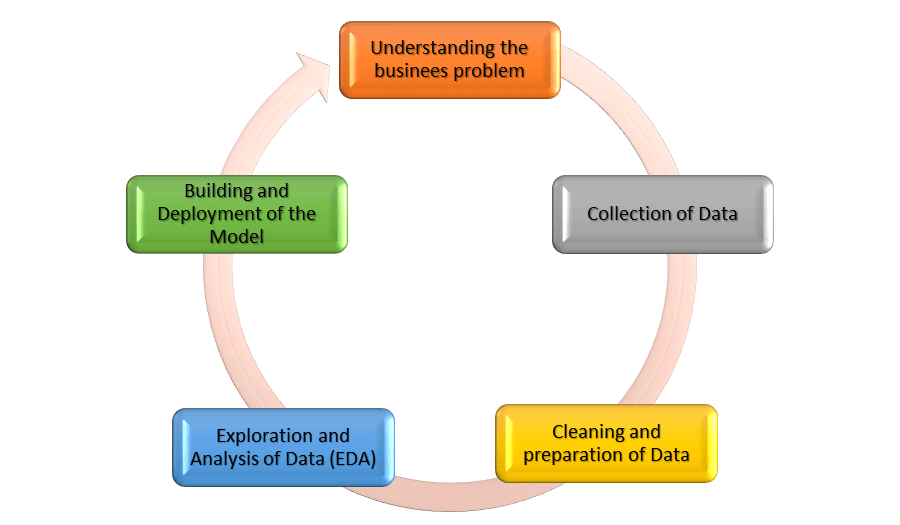
Жизненный цикл показывает, что работа с данными занимает большую часть времени. Следовательно, при принятии окончательного решения данные имеют решающее значение. Но, тем не менее, проблема заключается в том, как данные подготавливаются и обрабатываются.
Вот когда на помощь приходит статистика!!
В первом случае мы получаем полные необработанные данные, которые не имеют смысла, неформатированные данные, данные в различных формах, таких как видео, изображения и т. д., пропущенные значения и т. д. Статистика преобразует эти данные в числовой эквивалент и дает нам возможность понять данные.
Это также дает нам различные методы измерения эффективности наших идей и поиска наилучшего математического подхода к нашим данным.
Типы статистики:
- Описательная статистика — этот тип статистики включает сбор, представление и анализ данных таким образом, который описывает основные характеристики генеральной совокупности или выборки. Описательная статистика используется для обобщения и описания характеристик набора данных, таких как меры центральной тенденции (среднее, медиана, мода), меры изменчивости (стандартное отклонение, дисперсия) и графические представления (гистограммы, диаграммы разброса, точечные диаграммы).
- Выводная статистика. Этот тип статистики включает в себя обобщение или прогнозирование населения на основе выборки. Логическая статистика используется, чтобы делать выводы и делать прогнозы о большей совокупности на основе выборки из этой совокупности. Это включает в себя проверку гипотез, P-значение, T-тест, Z-тест, F-тест, тест хи-квадрат, альтернативную гипотезу и т. Д.
Оба типа статистики помогают нам принимать решения на основе данных.
Население и выборка:
В статистике совокупность — это вся группа отдельных лиц или объектов, которую исследователь хочет изучить, а выборка — это подмножество совокупности, выбранное для анализа.
Например: производственная компания производит миллионы продуктов, где совокупность будет состоять из всех произведенных продуктов, а образец будет представлять собой случайно выбранную группу из 500 продуктов для контроля качества. сильный>
Возникает следующий вопрос, как делается эта выборка!! Всегда ли образцы выбираются случайным образом?
Ответ - нет. Существуют различные методы выборки, которые используются для отбора выборок из генеральной совокупности.
Методы отбора проб:
- Простая случайная выборка. Каждый человек или объект в генеральной совокупности имеет равные шансы попасть в выборку. Например, выбор 100 студентов из колледжа путем случайного выбора их имен.
- Стратифицированная выборка. Население делится на подгруппы или страты на основе интересующей характеристики, и из каждой страты случайным образом отбирается выборка. Например, выбрать 50 студентов мужского пола и 50 студенток колледжа.
- Кластерная выборка.Население делится на кластеры, выбирается случайная выборка кластеров, а затем в выборку включаются все лица или объекты внутри выбранных кластеров. Например, выбрав три класса в школе, а затем включив в выборку всех учащихся в этих классах.
- Систематическая выборка. Отдельные лица или объекты выбираются из совокупности через фиксированные промежутки времени. Например, выбирая каждого 10-го покупателя, который входит в магазин в течение определенного часа.
- Удобная выборка: люди или объекты выбираются на основе их доступности и готовности участвовать в исследовании. Например, проведение опроса путем приближения людей на улице.
Выбор метода выборки зависит от вопроса исследования, характеристик населения и имеющихся ресурсов. Каждый метод имеет свои сильные и слабые стороны, и выбор соответствующего метода выборки имеет решающее значение для обеспечения репрезентативности выборки для населения и достоверности результатов.
Использование выборки:
Вот несколько примеров того, как выборка может использоваться в машинном обучении:
- Обучение модели. При построении модели машинного обучения обычно разделяют доступные данные на обучающий набор и тестовый набор. Выборка может использоваться для случайного выбора подмножества данных для обучения модели. Например, если у вас есть набор данных из 10 000 изображений и вы хотите использовать 80 % данных для обучения и 20 % для тестирования, вы можете случайным образом выбрать 8 000 изображений для обучающего набора и 2 000 для тестовый набор.
- Увеличение данных. В некоторых случаях может быть полезно искусственно увеличить размер набора данных, создав новые точки данных, похожие на исходные данные. Можно использовать выборку. для выбора подмножества исходных данных и применения преобразований или других методов для создания новых точек данных. Например, если у вас есть набор данных из 1000 изображений собак, вы можете использовать выборку, чтобы выбрать подмножество изображений и применить методы обработки изображений, такие как поворот, обрезка или отражение, для создания новых изображений.
- Оценка модели. При оценке эффективности модели машинного обучения важно использовать репрезентативную выборку данных. Выборка может использоваться для выбора подмножества доступных данных для использования в оценке модели. Например, если у вас есть набор данных из 10 000 изображений и вы хотите оценить производительность модели компьютерного зрения, вы можете случайным образом выбрать 1000 изображений из набора данных для использования для оценки.
- Несбалансированные наборы данных. В некоторых случаях набор данных может быть несбалансированным, поскольку небольшое количество точек данных принадлежит одному классу или категории. Методы выборки, такие как избыточная или недостаточная выборка, можно использовать для балансировки набора данных и повышения производительности модели. Например, если у вас есть набор данных из 1000 изображений кошек и только 100 изображений собак, вы можете использовать избыточную выборку для создания дополнительных изображений собак или недостаточную выборку, чтобы уменьшить количество изображений кошек.
Это только начало статистики. Оставайтесь с нами, чтобы узнать больше о статистике !!