
Представьте, что вы потратили месяцы на сбор и подготовку набора данных, тщательный отбор функций и построение модели машинного обучения. Вы точно настроили гиперпараметры, оценили производительность модели и уверены, что она готова делать точные прогнозы на основе новых данных. Но как только вы развертываете модель, вы начинаете замечать некоторые странные результаты. Модель делает странные предсказания, которые кажутся бессмысленными. Что пошло не так? Ответ может заключаться в выбросах — тех надоедливых точках данных, которые могут нанести ущерб моделям машинного обучения. В этом сообщении блога мы рассмотрим влияние выбросов на модели машинного обучения и обсудим различные стратегии их обнаружения для создания более устойчивых моделей.
Понимание выбросов
Выбросы — это значения в наборе данных, которые сильно отличаются от других, либо намного больше, либо значительно меньше. Эти значения могут быть вызваны ошибками измерения, ошибками ввода данных или даже допустимыми экстремальными значениями.
Выбросы могут влиять на модели машинного обучения несколькими способами. Одним из наиболее значительных способов воздействия выбросов на модели является искажение распределения данных. Поскольку выбросы не следуют той же схеме, что и другие точки данных, они могут значительно изменить среднее значение, медиану и стандартное отклонение набора данных. Это может привести к вводящим в заблуждение или неточным представлениям данных, что приведет к ошибочным моделям.
Выбросы также могут повлиять на соответствие модели машинного обучения. Когда в наборе данных присутствуют выбросы, они могут оказывать непропорциональное влияние на коэффициенты модели. Это может привести к переоснащению или недообучению модели, когда модель будет слишком сложной или слишком простой соответственно. Такие модели вряд ли будут давать точные прогнозы, что приведет к снижению производительности. Поэтому важно обнаруживать и устранять выбросы, чтобы обеспечить точность и надежность моделей машинного обучения. Устранение выбросов — важный шаг в создании устойчивых моделей машинного обучения.
Различные причины выбросов в наборах данных
- Ошибки ввода данных. Одной из основных причин выбросов являются ошибки ввода данных. Эти ошибки могут возникать из-за опечаток или ошибок десятичной точки, что может привести к записи неправильных данных. В некоторых случаях данные также могут быть записаны дважды или введены не в то поле, что приводит к выбросу в наборе данных.
- Ошибки измерения. Другой распространенной причиной выбросов являются ошибки измерения. Это может произойти из-за неисправных приборов, неточных показаний или человеческого фактора. Например, если весы не откалиброваны должным образом, они могут регистрировать значения веса, которые значительно отличаются от фактического веса.
- Ошибки выборки. Выбросы также могут возникать из-за ошибок выборки, которые могут возникнуть, когда размер выборки слишком мал или метод выборки необъективен. Например, если опрос включает только респондентов из определенной демографической группы, он может неточно отражать мнения или поведение большей части населения.
- Легитимные экстремальные значения. Выбросы также могут быть законными экстремальными значениями, которые важно зафиксировать. Например, при исследовании распределения доходов миллиардеры будут считаться исключениями, но их включение необходимо для точного отражения распределения богатства.
- Естественная изменчивость. Наконец, выбросы могут возникать из-за естественных вариаций данных. В некоторых случаях наличие выбросов может указывать на то, что данные не распределены нормально. Это может быть полезной информацией для анализа данных, поскольку она может помочь выявить потенциальные проблемы с данными.
Типы выбросов
Обычно выделяют два типа выбросов: одномерные выбросы и многомерные выбросы. Одномерные выбросы — это наблюдения, имеющие экстремальные значения, относящиеся только к одной переменной. Эти выбросы могут быть идентифицированы путем изучения распределения одной переменной с использованием таких методов, как ящичные диаграммы или гистограммы. Например, в наборе данных о результатах тестов учащихся учащийся, который набрал значительно больше или меньше баллов, чем другие учащиеся, будет считаться одномерным выбросом.

Многомерные выбросы, с другой стороны, представляют собой наблюдения, которые имеют экстремальные значения для комбинации переменных. Эти выбросы может быть сложнее обнаружить, чем одномерные выбросы, поскольку они могут быть неочевидны при изучении каждой переменной в отдельности. Многомерные выбросы можно выявить с помощью таких методов, как анализ основных компонентов или кластерный анализ. Например, в наборе данных медицинских карт пациентов пациент, который имеет комбинацию экстремальных значений нескольких показателей здоровья (таких как кровяное давление, частота сердечных сокращений и уровень холестерина), может считаться многомерным выбросом.

Как определить выбросы
Существуют различные способы выявления выбросов в наборе данных с использованием методов визуализации и статистики. Вот пример на Python с игрушечным набором данных:
Во-первых, давайте импортируем необходимые библиотеки и создадим набор данных:
import pandas as pd
import numpy as np
import seaborn as sns
from scipy import stats
# create toy dataset with outliers
data = {'x': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25],
'y': [8, 6, 9, 7, 15, 6, 7, 10, 12, 6, 7, 8, 9, 6, 7, 8, 100, 12, 10, 6, 7, 8, 9, 6, 7]}
df = pd.DataFrame(data)
Выявление выбросов с помощью визуализации
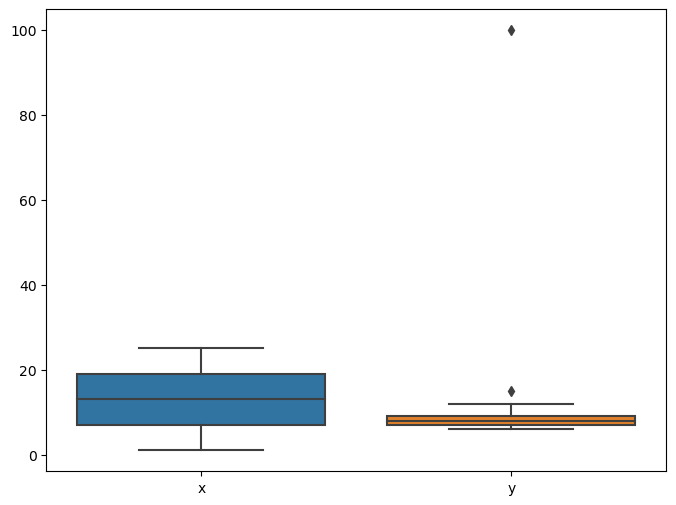
1. Блочная диаграмма
Одним из распространенных способов выявления выбросов является использование коробчатых диаграмм. Блочные диаграммы обеспечивают визуальное представление распределения данных и могут выделять наблюдения, которые значительно отличаются от других.
# detect outliers using boxplot sns.boxplot(df)
2. Диаграмма рассеяния
Другой способ определить выбросы — использовать диаграммы рассеивания. Нанося взаимосвязь между двумя переменными, точечные диаграммы могут эффективно иллюстрировать любые наблюдения, которые значительно отличаются от других.
# detect outliers using scatterplot sns.scatterplot(x=df['x'], y=df['y'])

Выявление выбросов с использованием статистических методов
1. Межквартильный размах (IQR)
Метод IQR (межквартильный диапазон) — это статистический метод, используемый для выявления и обработки выбросов в наборе данных. IQR определяется как разница между третьим квартилем (75-й процентиль) и первым квартилем (25-й процентиль) данных.

Чтобы использовать метод IQR для выявления выбросов, мы можем выполнить следующие шаги:
- Рассчитайте IQR: IQR = Q3 — Q1
- Определите нижнюю границу: Q1–1,5 * IQR
- Определите верхнюю границу: Q3 + 1,5 * IQR
- Определите выбросы: любая точка данных, выходящая за пределы нижней или верхней границы, считается выбросом.
# detect outliers using IQR Q1 = df['y'].quantile(0.25) Q3 = df['y'].quantile(0.75) IQR = Q3 - Q1 outliers = df[(df['y'] < Q1 - 1.5 * IQR) | (df['y'] > Q3 + 1.5 * IQR)] print(outliers)
Метод IQR эффективен при выявлении выбросов, которые являются более экстремальными, чем те, которые идентифицируются методом z-оценки. Он менее чувствителен к экстремальным значениям, чем метод z-оценки, и, следовательно, с меньшей вероятностью будет помечать значения как выбросы, которые на самом деле являются достоверными точками данных. Однако он по-прежнему может ошибочно идентифицировать достоверные точки данных как выбросы, если распределение данных сильно искажено.
2. Z-оценка
Метод z-оценки — это статистический метод, используемый для выявления выбросов на основе их отклонения от среднего значения. Он измеряет, на сколько стандартных отклонений наблюдение отличается от среднего.
Формула для расчета z-показателя для конкретного наблюдения:

где x — значение наблюдения, μ — среднее значение набора данных, а σ — стандартное отклонение набора данных.
Если абсолютное значение z-показателя превышает определенный порог, обычно 3 или 2,5, то наблюдение считается выбросом.
# detect outliers using z-score z_scores = np.abs(stats.zscore(df['y'])) threshold = 3 outliers = df[z_scores > threshold] print(outliers)
Метод z-оценки широко используется в различных областях, включая финансы, экономику и инженерию, поскольку он обеспечивает стандартизированный способ определения экстремальных значений в наборе данных. Однако не всегда может быть уместно использовать этот метод, особенно если набор данных не имеет нормального распределения или имеется только несколько наблюдений.
Когда следует удалять выбросы
Решение об удалении выбросов из набора данных зависит от контекста и цели анализа. В некоторых случаях выбросы могут быть подлинными наблюдениями, которые важны и не должны удаляться. В других случаях выбросы могут быть ошибками или аномалиями, которые могут исказить анализ и должны быть удалены.
Вот несколько общих рекомендаций, когда следует удалять выбросы:
- Выбросы — это ошибки или аномалии. Если выбросы вызваны ошибками сбора данных или измерения, их следует удалить, поскольку они не отражают реальную совокупность. Например, измерение веса человека в 2000 фунтов является исключением и должно быть удалено, поскольку это физически невозможно. Точно так же, если данные вводятся вручную и в них есть опечатки или ошибки, эти значения следует удалить.
- Выбросы не являются репрезентативными для генеральной совокупности. Выбросы, которые не являются репрезентативными для изучаемой генеральной совокупности, могут быть удалены, если они искажают распределение или анализ данных. Например, если в исследовании изучаются доходы домохозяйств среднего класса, может быть удален чрезвычайно высокий доход, не являющийся репрезентативным для среднего класса. Точно так же, если в исследовании изучается рост взрослых мужчин, женское значение может быть выбросом и должно быть удалено. Удаление этих выбросов может помочь получить более точное представление населения.
- Выбросы существенно влияют на результаты. Выбросы, существенно влияющие на результаты анализа, могут быть удалены, если будет сочтено, что они искажают данные. Например, в регрессионном анализе выбросы могут иметь непропорционально большое влияние на линию регрессии и могут исказить общее соответствие модели. В этом случае удаление выбросов может помочь получить более точную и репрезентативную модель. Однако важно отметить, что удаление слишком большого количества выбросов может привести к чрезмерному упрощению модели и потере важной информации.
Выводы
- Выбросы — это значения в наборе данных, которые сильно отличаются от других, либо намного больше, либо значительно меньше, и могут быть вызваны ошибками измерения, ошибками ввода данных или даже законными экстремальными значениями.
- Выбросы могут влиять на модели машинного обучения, искажая распределение данных, влияя на соответствие модели и приводя к неточным прогнозам.
- Обычно выделяют два типа выбросов: одномерные и многомерные. Одномерные выбросы — это наблюдения, имеющие экстремальные значения, относящиеся только к одной переменной. Многомерные выбросы — это наблюдения, которые имеют экстремальные значения для комбинации переменных.
- Существуют различные способы выявления выбросов, включая визуализацию (например, блочные диаграммы, диаграммы рассеяния) и статистические методы (например, IQR, z-показатель).
- Решение об удалении выбросов из набора данных зависит от контекста и цели анализа, и выбросы следует удалять только после тщательного рассмотрения, чтобы убедиться, что полученная модель точно представляет изучаемую совокупность.
Спасибо, что нашли время прочитать мою статью! Если вы нашли эту статью полезной или информативной, не забудьте нажать на значок хлопка столько раз, сколько хотите. Если вам нравятся мои работы и вы хотите поддержать меня, рассмотрите возможность подписаться на меня на Medium, чтобы в будущем получать больше подобного контента, или купите мне чашку кофе☕. Ваша поддержка мотивирует меня продолжать создавать ценный контент для моих читателей.