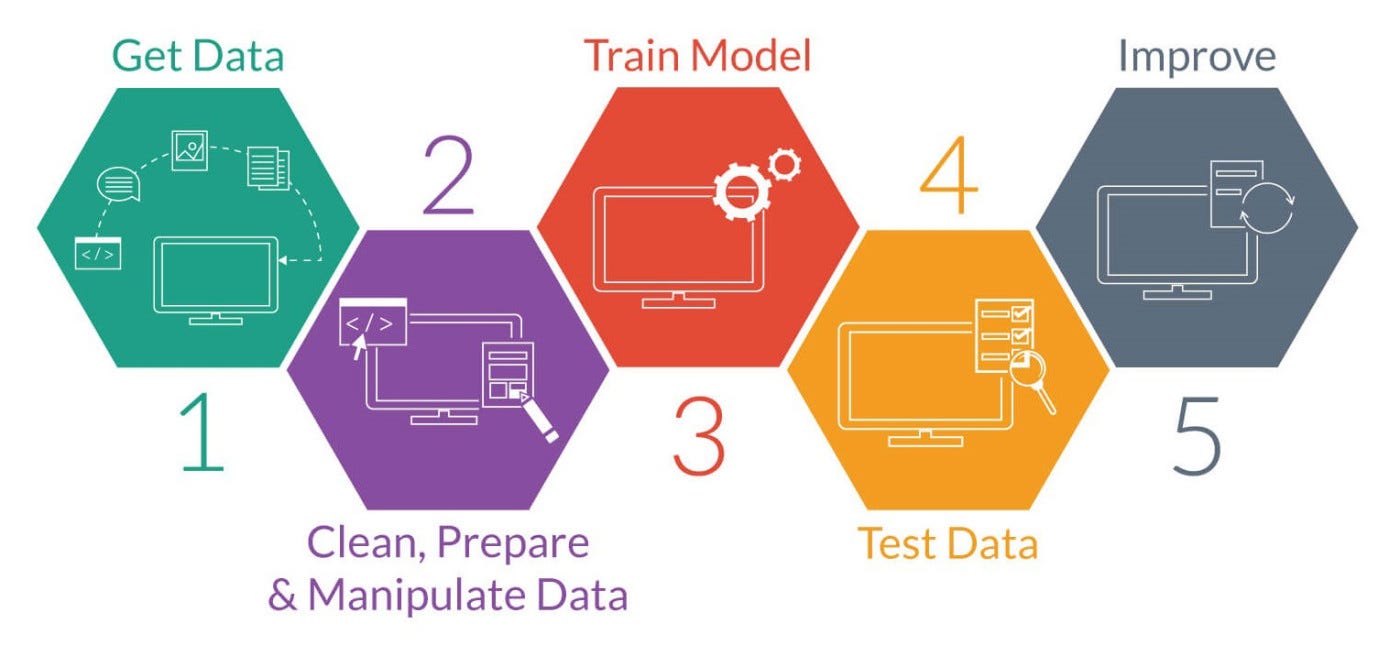
Обучение модели машинного обучения включает несколько шагов и требует разных файлов в зависимости от конкретной задачи. Вот общий обзор шагов, связанных с обучением модели машинного обучения, и файлов, которые могут потребоваться:
Шаг 1: Подготовка данных
Для обучения модели машинного обучения обычно требуется набор данных, который можно использовать для обучения и оценки модели. Набор данных должен быть правильно отформатирован и очищен, чтобы обеспечить точность и согласованность данных. Формат набора данных будет зависеть от типа проблемы, которую вы пытаетесь решить.
Например, если вы обучаете модель распознавать изображения, вам понадобится набор данных изображений в определенном формате (например, JPEG, PNG). Если вы обучаете модель классификации текста, вам понадобится набор данных текстовых документов в определенном формате (например, CSV, JSON).
Некоторые распространенные форматы файлов для наборов данных включают:
- CSV (значения, разделенные запятыми)
- JSON (обозначение объекта JavaScript)
- XML (расширяемый язык разметки)
- Форматы изображений (JPEG, PNG, BMP)
- Текстовые форматы (TXT, PDF)
Шаг 2: Выбор модели
Прежде чем приступить к обучению модели машинного обучения, необходимо выбрать подходящую архитектуру модели, подходящую для проблемы, которую вы пытаетесь решить. Существует множество различных типов моделей машинного обучения, в том числе:
- Линейная регрессия
- Логистическая регрессия
- Деревья решений
- Случайные леса
- Машины опорных векторов (SVM)
- Нейронные сети
После того, как вы выбрали архитектуру модели, вам нужно выбрать конкретную реализацию модели. Например, если вы решите использовать нейронную сеть, вам нужно выбрать количество слоев, функции активации и алгоритм оптимизации.
Шаг 3. Извлечение признаков
В большинстве случаев набор данных, который вы используете для обучения модели машинного обучения, будет содержать большое количество функций. Однако не все функции могут иметь отношение к проблеме, которую вы пытаетесь решить. Поэтому вам нужно извлечь наиболее важные функции из набора данных.
Это может включать такие задачи, как масштабирование функций, выбор функций и разработка функций. Масштабирование функций включает в себя нормализацию функций, чтобы все они имели одинаковый масштаб. Выбор функций включает в себя выбор подмножества наиболее важных функций. Разработка функций включает в себя создание новых функций из существующих.
Шаг 4: Обучение модели
После того, как вы подготовили набор данных и выбрали архитектуру модели, вы можете начать обучение модели. На этом этапе вы вводите обучающие данные в модель и настраиваете параметры модели для оптимизации ее производительности.
Процесс обучения модели включает в себя несколько этапов, в том числе:
- Инициализация: инициализация весов и смещений модели.
- Прямое распространение: подача входных данных в модель и вычисление выходных данных.
- Расчет стоимости: расчет стоимости (или потерь) результатов модели.
- Обратное распространение: распространение ошибки обратно по модели и обновление весов и смещений.
- Оптимизация: использование алгоритма оптимизации (например, градиентного спуска) для минимизации затрат и повышения производительности модели.
Некоторые распространенные форматы файлов для сохранения обученной модели включают в себя:
- HDF5 (формат иерархических данных версии 5)
- Соленый огурец
- Сохраненная модель
Шаг 5: Оценка модели
После обучения модели необходимо оценить ее производительность на отдельном наборе данных (проверочный набор). Это даст вам представление о том, насколько хорошо модель способна обобщать новые данные.
Этап оценки включает в себя расчет различных показателей производительности, таких как точность, достоверность, полнота и оценка F1. Эти показатели помогут вам определить, достаточно ли хорошо работает модель, чтобы ее можно было развернуть в реальном приложении.
Шаг 6: Развертывание модели
Если модель работает хорошо, вы можете развернуть ее в реальном приложении. Это включает в себя интеграцию модели в код приложения и ее тестирование в производственной среде.
Некоторые распространенные форматы файлов для развертывания включают в себя:
- Обслуживание TensorFlow
- ONNX (обмен открытыми нейронными сетями)
- Апач MXNet
Вот пример кода для обучения простой модели линейной регрессии с использованием Python и библиотеки scikit-learn:
# Import the necessary packages import numpy as np from sklearn.linear_model import LinearRegression # Load the training data X_train = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) y_train = np.array([3, 6, 9]) # Initialize the model model = LinearRegression() # Train the model model.fit(X_train, y_train) # Save the model import joblib joblib.dump(model, 'linear_regression_model.pkl')
В этом примере мы загрузили небольшой обучающий набор данных, состоящий из трех точек данных с тремя функциями в каждой. Мы инициализировали модель LinearRegression и обучили ее набору данных. Наконец, мы сохранили обученную модель с помощью библиотеки joblib.