Введение
В области наук о данных и соревнований по машинному обучению Kaggle’s Playground выделяется как арена, где начинающие специалисты по данным демонстрируют свои навыки и опыт. В каждом соревновании за желанные призовые места борются многочисленные участники. Среди них несколько избранных выходят победителями, закрепляя свои позиции в неуловимой пятерке лидеров. Начинающие энтузиасты данных и конкуренты часто задаются вопросом, что отличает этих лучших исполнителей и побуждает их к такому выдающемуся успеху.
В своем стремлении разгадать секреты пяти лучших исполнителей Kaggle’s Playground я углубился в их код, анализируя тонкости и методы, которые проложили им путь к славе. В этой статье я стремлюсь пролить свет на их подходы, предоставив бесценные идеи и уроки, которые могут быть полезны любому, кто стремится повысить свое мастерство в науке о данных.
Присоединяйтесь ко мне, и я исследую внутреннюю работу кода этих 5 лучших исполнителей Kaggle, раскапывая стратегии, алгоритмы и методологии, которые привели их к вершине успеха. Независимо от того, являетесь ли вы опытным специалистом по данным или увлеченным новичком, эта статья послужит ценным ресурсом для расширения ваших знаний и вдохновит вас на расширение границ передового опыта в области обработки данных.
Методология
Я провел обширный анализ первых 10 соревнований Kaggle’s Playground, проведенных в этом году. Я сосредоточился на сборе информации о решениях 5 лучших пользователей в каждом соревновании, когда их подходы были доступны. Этот процесс был предназначен для выявления общих шаблонов, алгоритмов и методов, которые способствовали их успеху, что позволило мне предоставить всесторонний обзор методологий, принятых 5 ведущими конкурентами Kaggle.
Каковы задачи игровой площадки Kaggle?
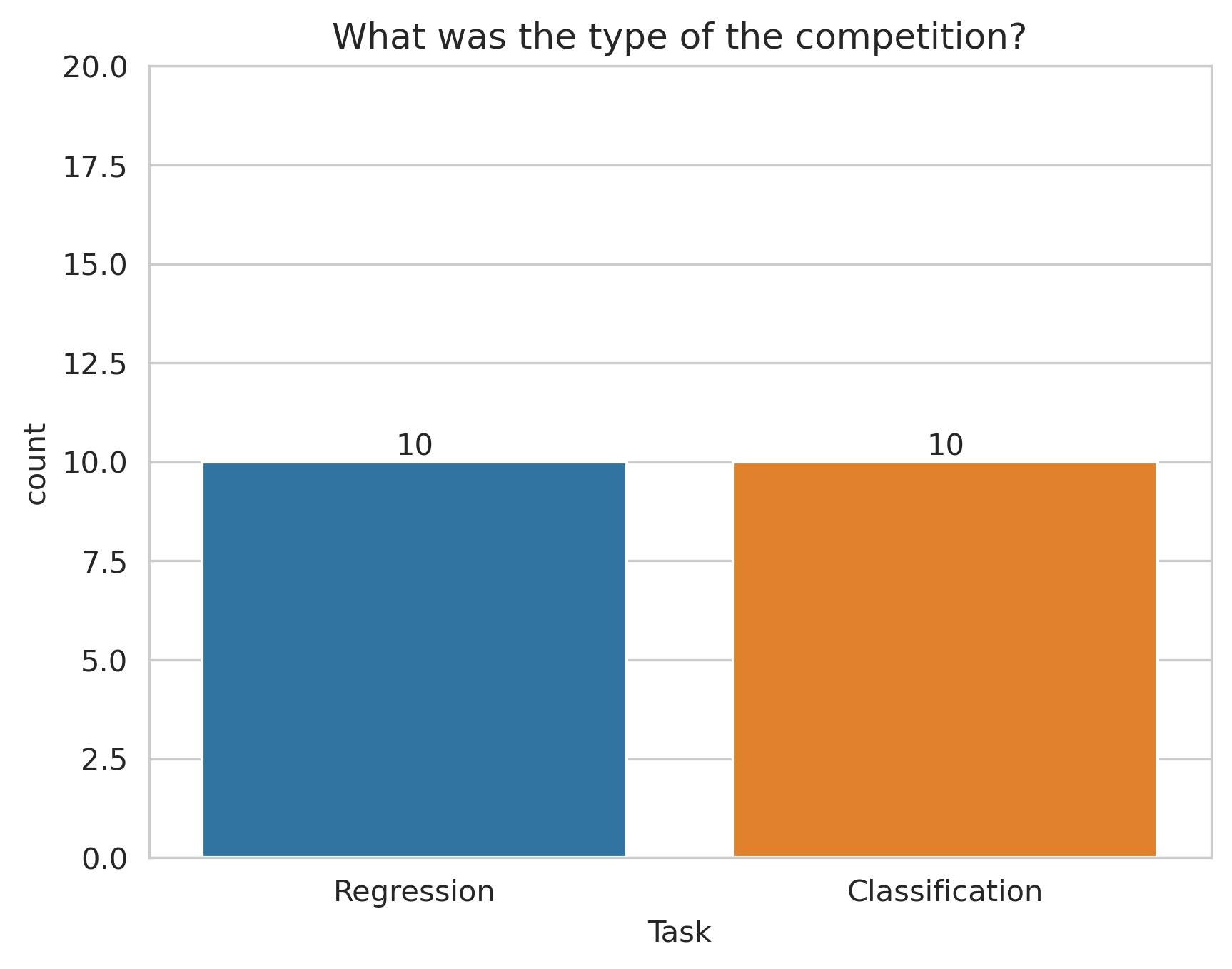
Как видите, в проанализированных данных половине пользователей приходилось сталкиваться с задачами классификации, а другой — с регрессией. Это проблемы, которые чаще всего возникают при работе с табличными данными.
В описании Kaggle’s Playground четко сказано:
Во-первых, серия получает обновленный брендинг. Мы убрали слово «Таблица» из названия, потому что, хотя мы ожидаем, что в этой серии по-прежнему будет много табличных соревнований, у нас также будут некоторые другие форматы.
Так что, возможно, авторы готовят что-то другое для других конкурсов.
Kaggle’s Playground — не для новичков?
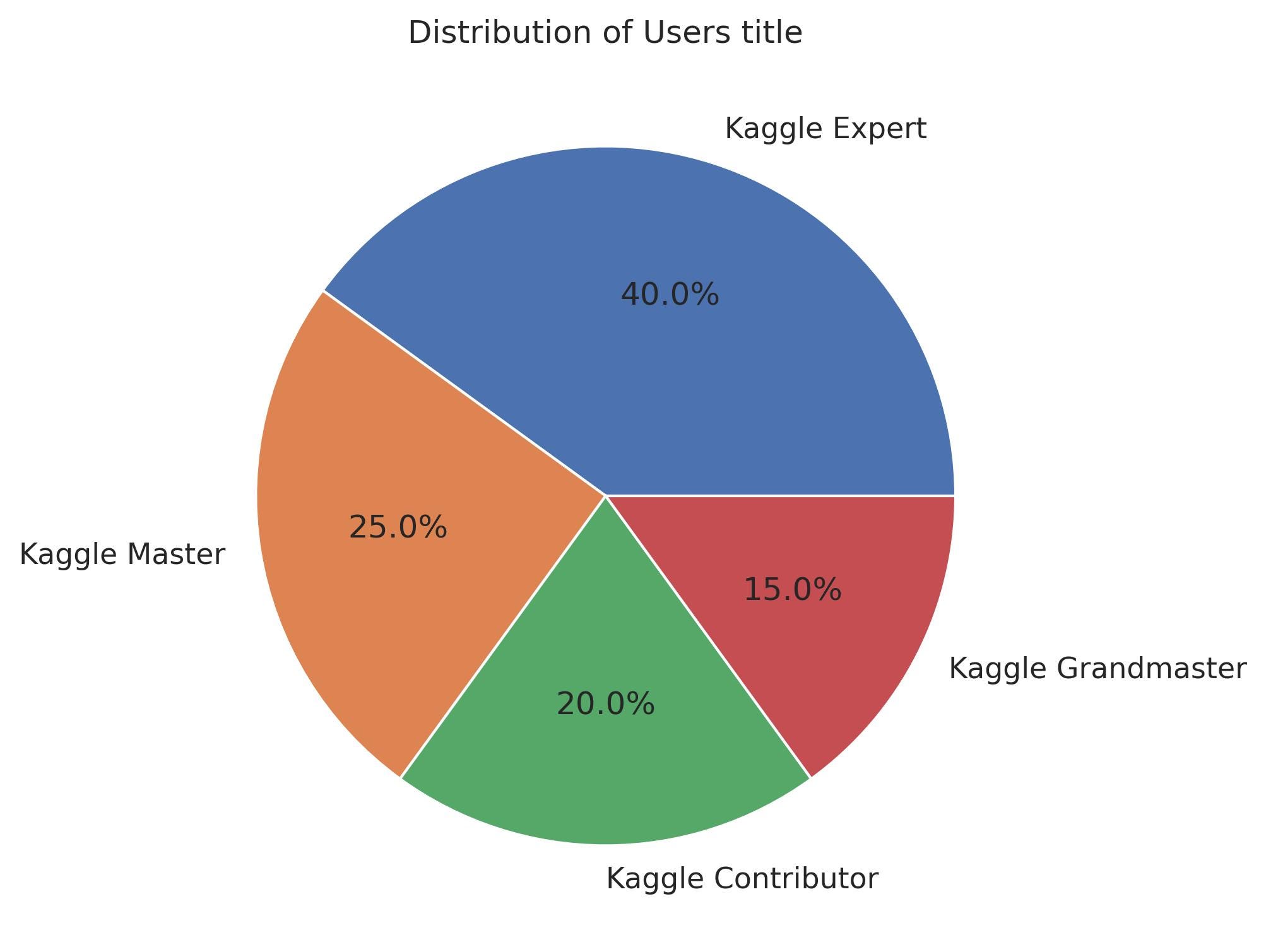
Как вы можете видеть на диаграмме выше — большая часть победителей — либо Kaggle Master, либо Grandmaster. 40% победителей в выбранных данных были экспертами Kaggle. Это может быть как полезно, так и вредно. С одной стороны, это позволяет нам, новичкам, читать код людей, которые уже работают в индустрии, и, таким образом, приобретать часть их мудрости. С другой стороны, очень демотивирует знать, что люди, соревнующиеся с вами, имеют намного больше опыта, поэтому шансы на победу довольно малы.
Битва Титанов: LightGBM, XGBoost и CatBoost
Изучая машинное обучение и табличные данные, я часто задавался вопросом — какие модели наиболее полезны. Диаграмма ниже описывает это хорошо, на мой взгляд.

Если вы хотите быстро достичь наилучших результатов, вам, вероятно, следует потратить время на изучение XGBoost, LightGBM и Catboost. Эти алгоритмы на протяжении многих лет складывались как модели, позволяющие находить выигрышные решения.
Но достаточно ли одной модели?
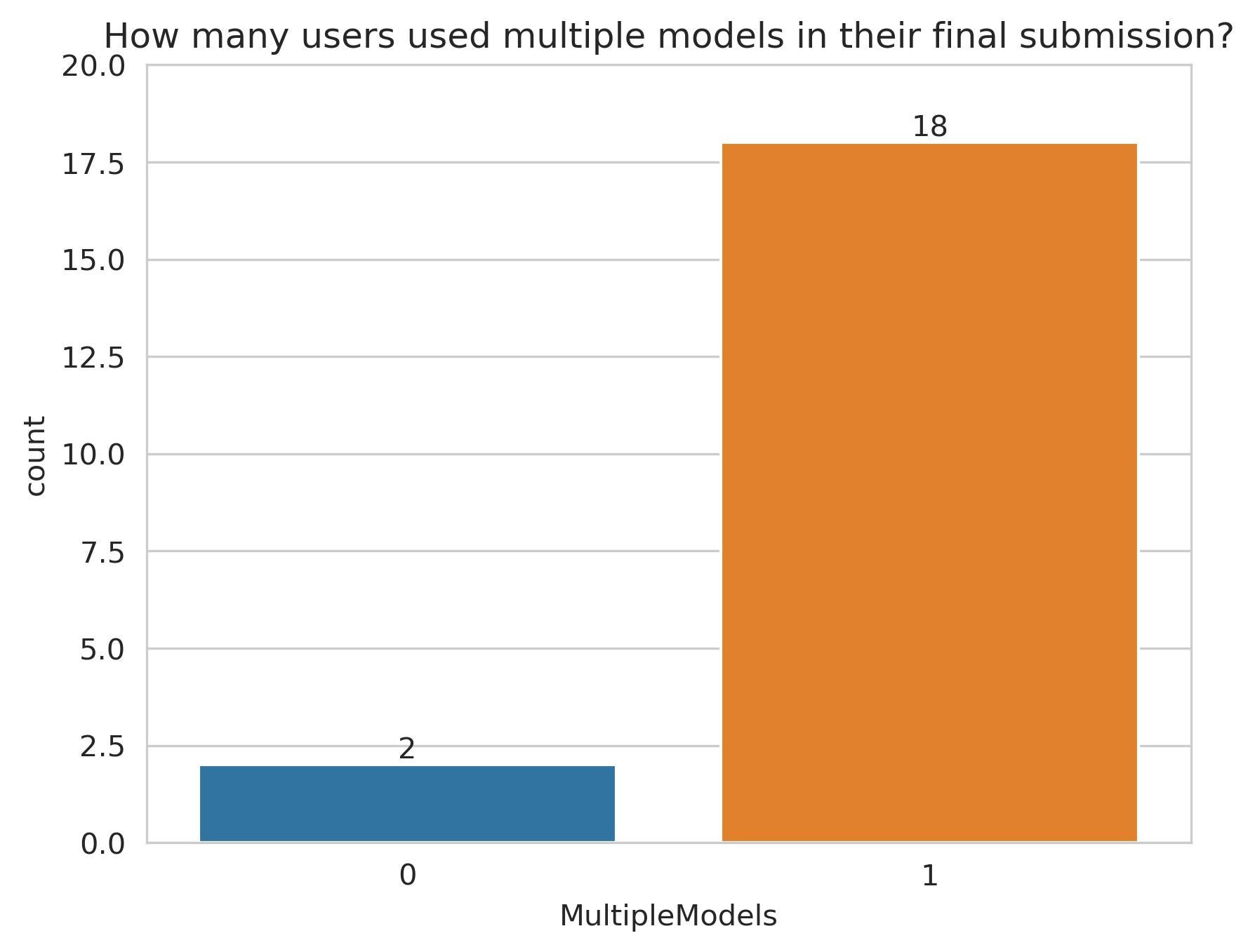
К сожалению…. нет. Как вы можете видеть на графике ниже, почти все решили использовать более одной модели — это связано с тем, что эти модели дополняют сами себя и позволяют достичь более высокой точности прогнозов, снижая при этом риск переобучения.
Переоснащение

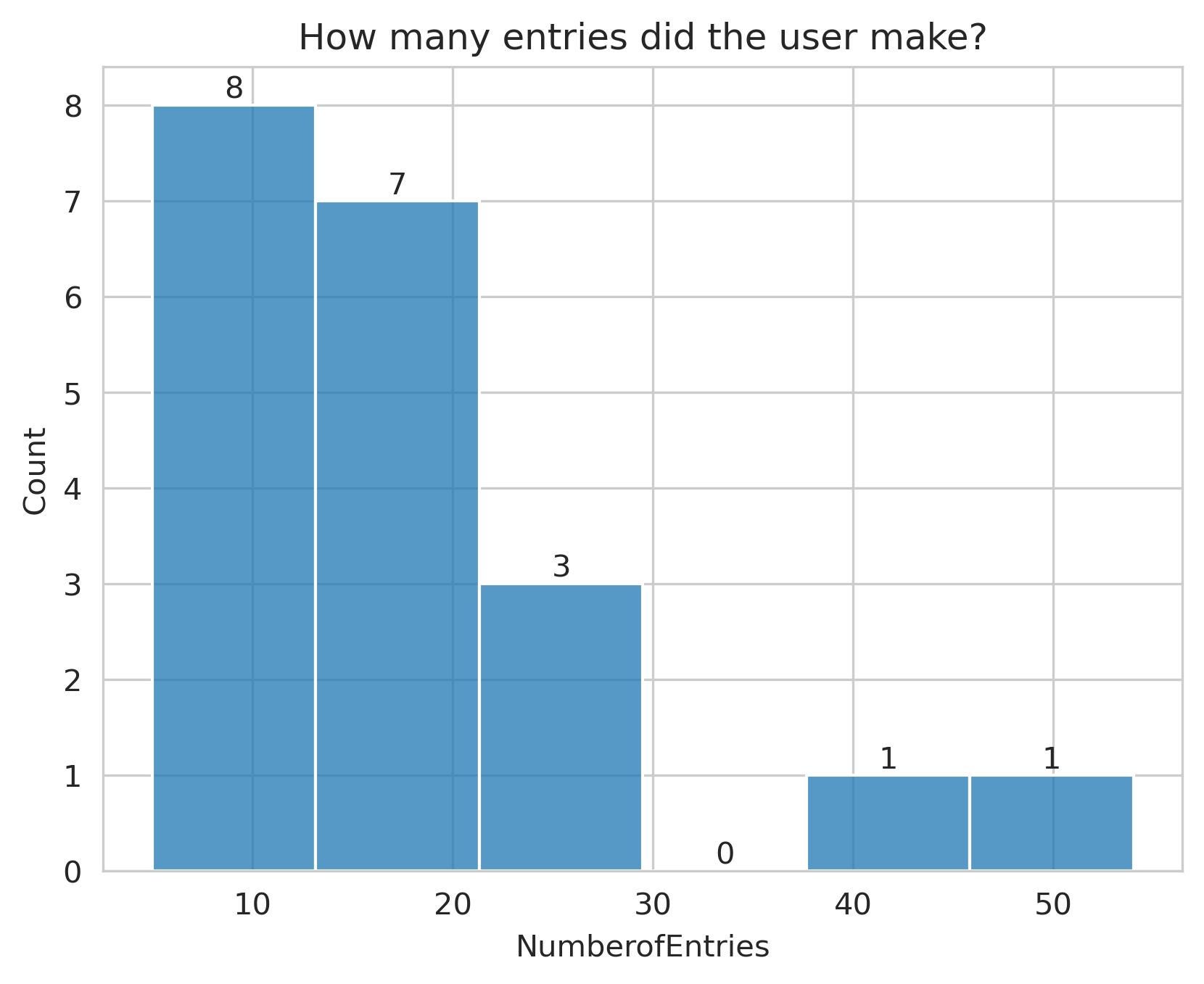
Одна вещь, которую я перечитывал снова и снова… НЕ СМОТРИТЕ НА ОБЩЕСТВЕННУЮ ОЦЕНКУ. Как видно на графике выше, половина людей, которые по проанализированным данным поднялись в рейтинге на 25 и более позиций. Это связано с тем простым фактом, что люди, набравшие высокие баллы на публичной доске, имеют много записей и, как следствие, они переобуваются. Итак, сколько записей у вас должно быть? Что ж, согласно приведенной ниже таблице — от 10 до 20 — разумное количество.
Что вы можете сделать, чтобы предотвратить переоснащение? Что нужно сделать, чтобы узнать, поправляетесь ли вы? Ответ прост, и это….
Перекрестная проверка.
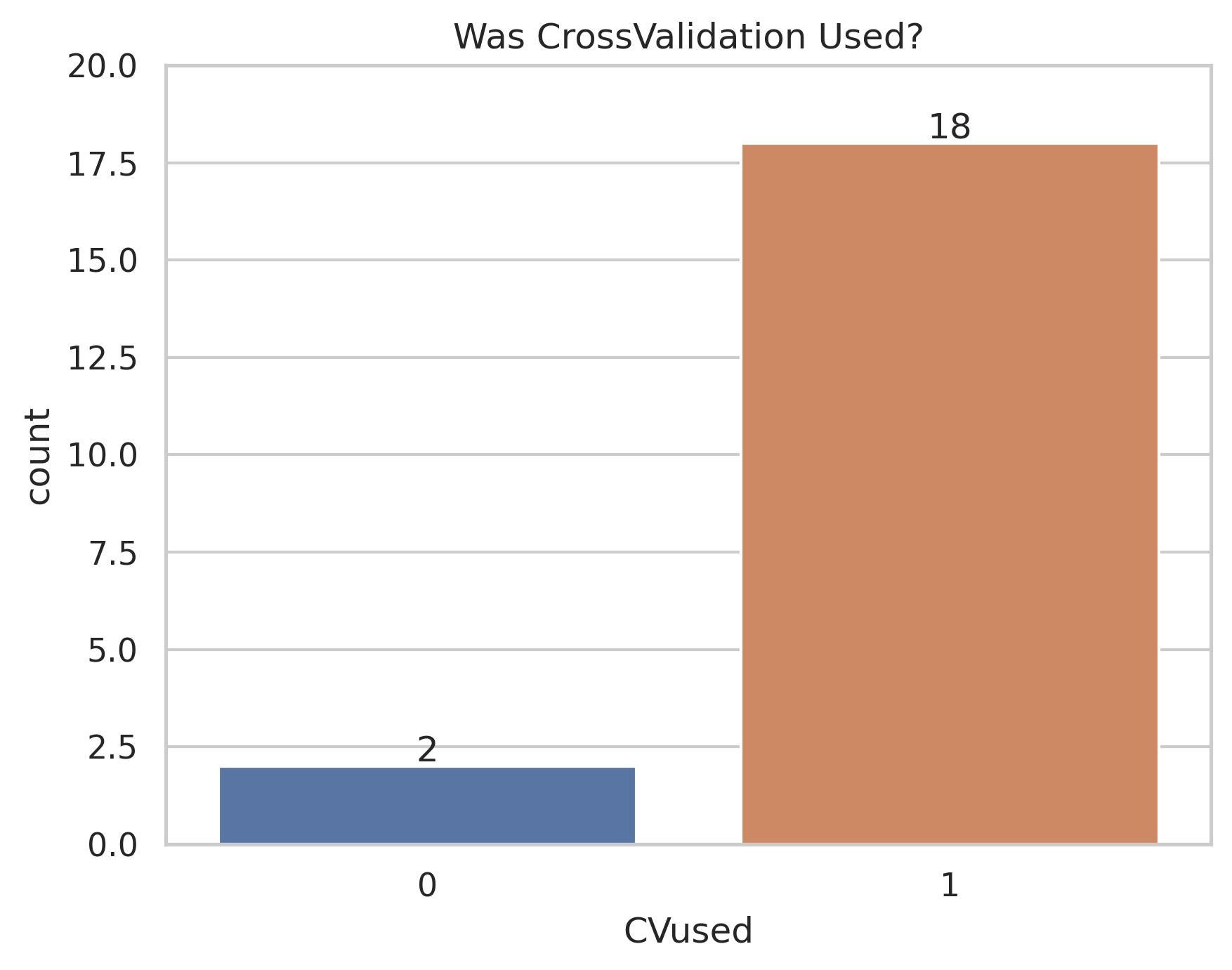
Как видите, почти все использовали CV в своей работе. Причина проста — это отличный способ проверить свои прогнозы без переобучения. Как написать хороший код перекрестной проверки? Возможно, я напишу еще один туториал на эту тему, но пока отправлю вас на этот ресурс.
Какие дополнительные советы я мог бы дать вам на основе проанализированного кода?
- читайте и используйте код других авторов — открытый код часто ускоряет вашу работу и позволяет добиться лучших результатов. Чем больше кода вы читаете — тем лучше код пишете
- сохраняйте интересные или чистые части вашего кода — они пригодятся вам в ваших следующих соревнованиях
- попробуйте писать функции вместо того, чтобы повторять код, который вы пишете — это экономит время и улучшает читаемость.
- используйте контроль версий — kaggle позволяет легко сохранять текущее состояние работы. Если вы испортите свой код, его легко вернуть, если вы используете контроль версий.
- убедитесь, что вы правильно понимаете метрику, используемую для оценки. Иногда лучше сделать больше ошибок в предсказании, убедившись, что вы не делаете ошибок, которые являются верным ответом.
- рассмотрите возможность использования исходных данных, чтобы улучшить результат
Конечные мысли
Когда мы подошли к концу этой статьи, позвольте мне сказать вам, что погружение в код и стратегии пяти лучших исполнителей Kaggle в соревнованиях Playground похоже на открытие сундука с сокровищами мудрости науки о данных. Это все равно, что получить инсайдерский доступ к секретному соусу, который делает их такими чертовски успешными. Так что, друзья, берите на заметку и черпайте вдохновение.
Итак, мои коллеги-энтузиасты данных, давайте отправимся в это эпическое путешествие, вооружившись знаниями пяти лучших исполнителей Kaggle. Давайте раздвинем границы возможного в науке о данных, по одной строке кода за раз. Вместе мы раскроем весь потенциал наших мечтаний, основанных на данных. Впереди интересные времена, друзья!