Как запустить код
Вы можете скачать этот блокнот отсюда: здесь, и вам следует установить все необходимые пакеты, прежде чем запускать код локально. И вы можете скачать набор данных из:
Постановка задачи
Представьте, что вы работаете с агентством прогнозов погоды, которое стремится улучшить свои прогнозы дождя по всей Австралии. Ваша задача как Data Scientist — создать автоматизированную систему, которая предсказывает, будет ли дождь на следующий день. Ваша модель прогнозирования должна учитывать такие особенности, как местоположение, температура, влажность, скорость ветра и другие соответствующие параметры погоды.
Прогнозы дождя из вашей системы не только помогут в прогнозировании дождя, но и должны давать четкие объяснения для каждого прогноза, который она делает.
Чтобы помочь вам в выполнении этой задачи, вам предоставляется CSV-файл, содержащий данные ежедневных наблюдений за погодой за десятилетие из различных мест Австралии. Набор исторических данных включает параметры погоды вместе с бинарным индикатором «RainTomorrow», обозначающим, шел ли дождь на следующий день (1 мм или более, «Да») или нет («Нет»).
Ваша задача — использовать эти данные для создания системы прогнозирования, способной точно прогнозировать дождь на любой день, даже если данные этого дня не являются частью исходного набора данных.
Импорт библиотек
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression from sklearn import metrics import seaborn as sns import plotly.express as px import numpy as npdata = pd.read_csv('weatherAUS.csv') # load the dataset
Исследовательский анализ данных и визуализация
Чтобы понять доступные данные, мы должны выполнить анализ данных, визуализируя распределение значений в каждой функции и отношения между продажной ценой и другими функциями. Под функциями я подразумеваю столбцы данных.
data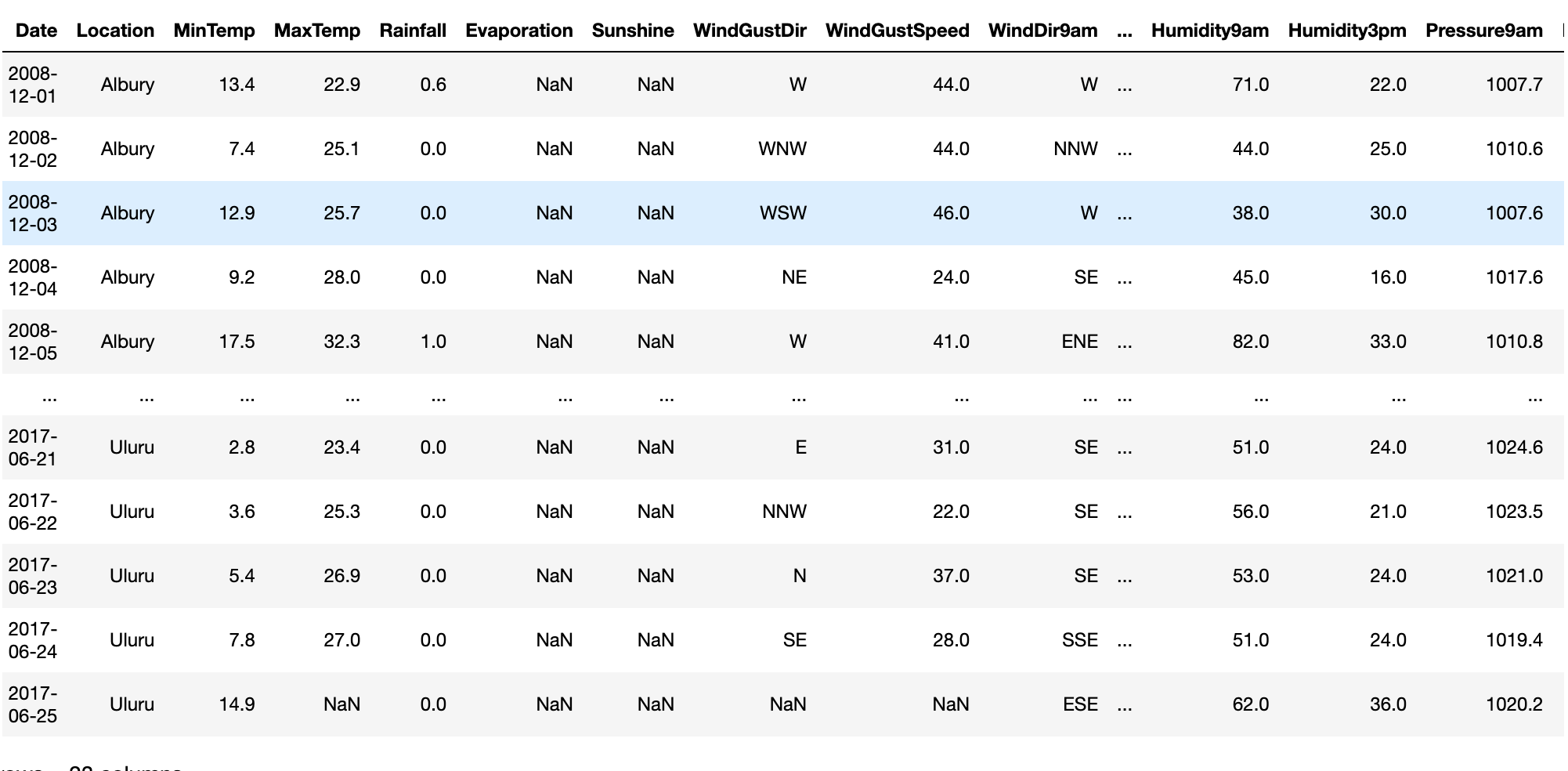
Набор данных содержит 145460 строк и 23 столбца. Каждая строка в наборе данных содержит информацию (столбцы), также называемые признаками погоды в конкретный день. Задача состоит в том, чтобы найти способ оценить значение в столбце «RainTomorrow», используя значения в других столбцах. Если мы можем сделать эту оценку для исторических данных, то мы сможем оценить RainTomorrow для будущих дат, которые не являются частью этого набора, просто предоставив такую информацию, как температура, влажность, скорость ветра и другие соответствующие параметры погоды.
Проверьте типы данных каждого столбца
data.info()
Проверьте недостающие значения каждого столбца
data.isnull().sum()
Поскольку в категории RainTomorow не слишком много пропущенных значений, я удалю все дни, когда это значение отсутствует, поскольку важно иметь только точные значения, если это возможно, перед обучением нашей модели.
data.shape # outputs(145460, 23) # Drop values in a dataset where rain today and rain tomorrow are NaN.data.dropna(subset=['RainToday', 'RainTomorrow'], inplace=True)
Исследовательский анализ и визуализация
Теперь начинаем изучать некоторые особенности
На графике ниже видно, что распределение признака «Местоположение» равномерное, в каждом городе количество дождливых дней почти одинаковое. За исключением некоторых из них, таких как Улуру, Кэтрин и Нхил. Но это также может быть связано с тем, что в этих областях также ниже количество пропущенных значений, поскольку они не полностью измеряли погоду за последние 10 лет.
## Explore rainy days over all locations in Australia px.histogram(data, x='Location', color='RainToday', title='Rainy days over all locations in Australia')

data.Location.nunique() # outputs 49Графики ниже показывают корреляцию между низкими температурами в 15:00 и вероятностью дождя завтра или низкими температурами утром и вероятностью дождя в этот день. Из сюжета видно, что это правда, что также является интуитивным предположением. Чем ниже температура в 15:00, тем выше вероятность дождя завтра.
px.histogram(data, x='Temp3pm', color='RainTomorrow', title='Rain Tomorrow vs Temperature at 3pm')px.histogram(data, x='Temp9am', color='RainToday', title='Rain Today vs Temperature at 9am')


Важно проверить распределение нашей целевой переменной RainTomorrow.
px.histogram(data, x='RainTomorrow', color='RainToday', title='Rain Tomorrow vs Rain Today)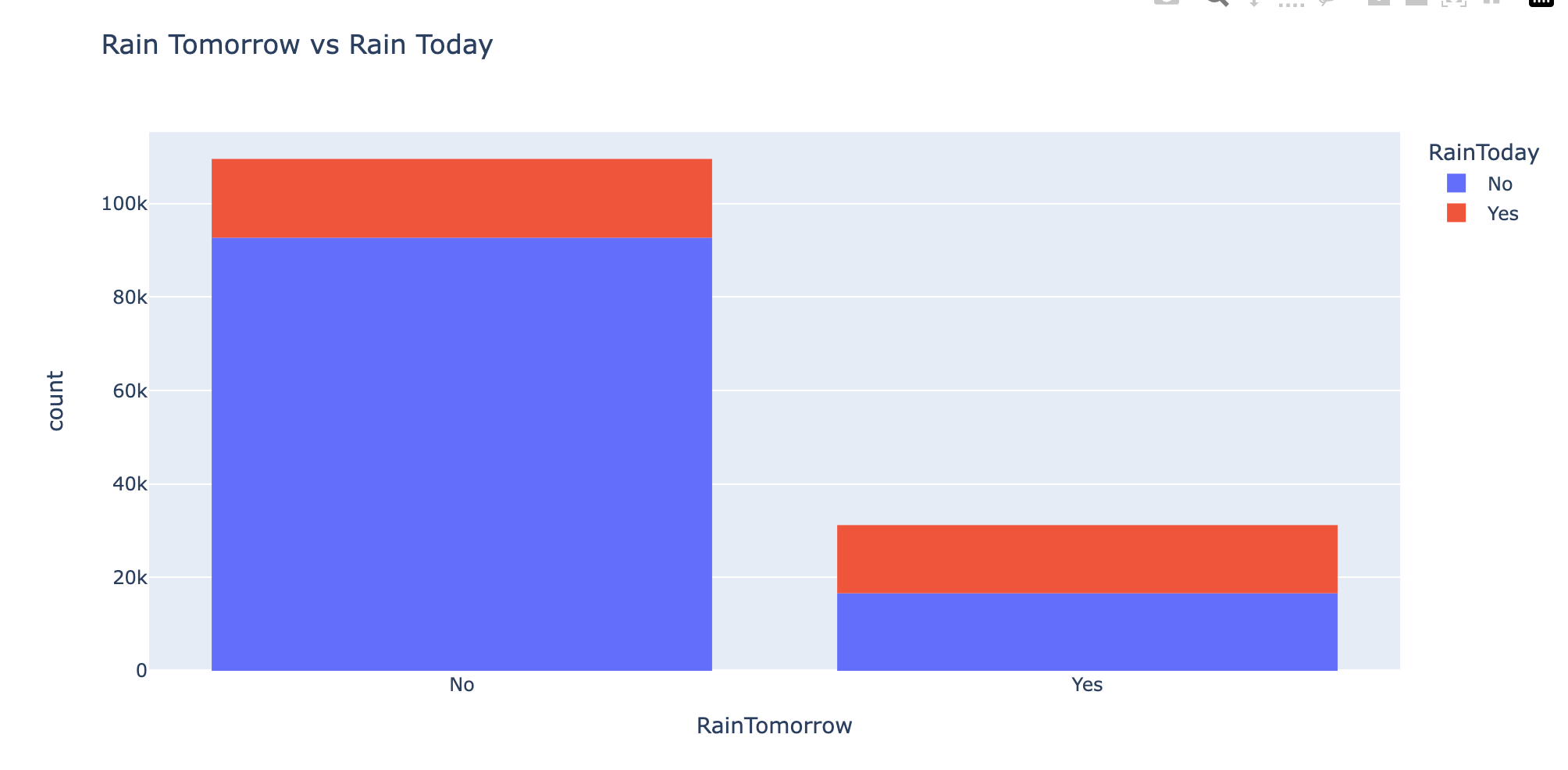
На приведенном выше графике мы могли бы сказать, что наш RainTomorrow, функция (класс), которую мы пытаемся предсказать, неравномерно представлена в наборе данных. Это означает, что наши данные несбалансированы, поскольку дней без дождя больше, чем дней с дождем.
Из этого распределения мы видим, что если сегодня не было дождя, то высока вероятность, что дождя не будет и завтра (мы можем видеть это по столбцу RainTomorrow No), с другой стороны, если мы посмотрим на Raintomorrow YES , из RainToday довольно сложно сделать вывод, будет ли завтра дождь, да или нет.
Из-за этого нашей модели сложнее предсказать, будет ли завтра дождь, и легче предсказать, будет ли дождь НЕ завтра.
px.scatter(data.sample(1000), x='MinTemp', y='MaxTemp', color='RainToday', title='MinTemp and MaxTemp vs RainToday')
Из приведенного выше графика видно, что существует линейная корреляция между MinTemp и MaxTemp за день, и если мы проверим точки данных RainToday = Yes, мы увидим, что в дни, когда шел дождь, нет большой разницы между Мин. и макс. температура
# Grouping the data by category and target and calculating the count
grouped_data = data.groupby(['Cloud3pm', 'RainTomorrow']).size().unstack()
grouped_data.plot(kind='bar', stacked=True)
plt.xlabel('Category')
plt.ylabel('Count')
plt.title('Correlation between Categorical Variable and Target Variable')
plt.legend(title='Target')
plt.show()
Основываясь на графиках выше, мы могли видеть, что существует корреляция между облаками в 15:00 и завтрашним дождем. Если облачность в 3 часа дня равна 7 или 8 баллам, велика вероятность дождя завтра.
px.histogram(data, x='WindSpeed3pm', color='RainTomorrow', title='Rain Tomorrow vs Temperature at 3pm')
px.scatter(x='Temp3pm', y='Humidity3pm', color='RainTomorrow', data_frame=data.sample(8000), title='Rain Tomorrow vs Temperature at 3pm, Humidity at 3pm')

Из приведенных выше графиков видно, что если влажность выше 50, а температура относительно низкая, завтра больше шансов на дождь.
px.scatter(x='Temp9am', y='Humidity9am', color='RainToday', data_frame=data.sample(8000), title='Rain Today vs Temperature at 3 pm, Humidity at 3pm)
Мы получаем аналогичные результаты, проверяя влажность и температуру в 9 утра.
Обучение/Тестирование/Проверка Разделения
- Обучающий набор. Это набор данных, который используется для обучения модели машинного обучения. Модель учится на этих данных и настраивает свои параметры, чтобы минимизировать разницу между прогнозируемыми и фактическими значениями целевой переменной. Обучающий набор обычно составляет около 60–80% набора данных.
- Проверочный набор. Проверочный набор используется для оценки производительности модели на этапе обучения и точной настройки гиперпараметров модели (параметров, которые не извлекаются из данных, а задаются практикующим специалистом, как скорость обучения в градиентном спуске). Модель не учится на этих данных в традиционном смысле, а скорее используется для предотвращения переобучения обучающим данным. Набор проверки помогает гарантировать, что модель хорошо обобщает невидимые данные. Обычно он составляет около 10–20% набора данных.
- Тестовый набор. Это данные, которые модель никогда не видела на этапе обучения или проверки. Он используется для оценки окончательной производительности модели после завершения обучения и проверки. Это помогает нам понять, как модель будет работать, когда она используется для прогнозирования новых, невидимых данных в реальном мире. Как и проверочный набор, тестовый набор обычно составляет около 10–20% набора данных.
Разделение данных на эти три набора важно, потому что это позволяет нам убедиться, что наша модель не только хорошо работает с данными, на которых она была обучена, но и хорошо обобщает новые, невидимые данные. Этот процесс помогает нам избежать переобучения, когда модель настолько хорошо усваивает обучающие данные, что плохо работает при столкновении с новыми данными.
train_val_df, test_df = train_test_split(data, test_size=0.2, random_state=42) # get 20% of data for testing (test_df) train_df, val_df = train_test_split(train_val_df, test_size=0.25, random_state=42) # from 80% remaining data, get 25% for validation (val_df), and the remaining train_df for training.data['Date'] = pd.to_datetime(data['Date']) # convert Date column to DateTime format data['Year'] = data['Date'].dt.year # extract year from Date column sns.countplot(x=data['Year'])
Поскольку мы пытаемся предсказать, будет ли дождь в будущем, логично также соответствующим образом обучить данные. Например, лучше использовать обучающий набор для исторических данных (с 2007 по 2014 год), затем использовать данные в будущем для проверки, например, 2015 года и 2016 года для настройки гиперпараметров, а затем использовать данные 2017 года для прогнозирования (тестирование нашей модели).
train_df = data[data['Year'] < 2015] # get data before 2015 for training
val_df = data[data['Year'] == 2015] # get data in 2015 for validation
test_df = data[data['Year'] > 2015] # get data after 2015 for testingОпределите входы и цель
Нет смысла обучать модель с использованием столбца «Дата», поскольку другие функции, основанные на анализе, важны для нашего прогноза, потому что с использованием этих столбцов существует корреляция дождя сегодня/завтра.
В целевой колонке завтра будет дождь, и мы должны удалить ее из нашего ввода.
В этом наборе данных есть местоположение столбца, мы используем его в нашей модели, но это означает, что эту модель можно использовать только для прогнозирования определенных местоположений, заданных в обучающем наборе, если мы хотим сделать его более общим. столбец местоположения должен быть удален.
Обработка отсутствующих данных
Обработка пропущенных значений — очень важный шаг в предварительной обработке данных. Стратегия обработки этих пропущенных значений зависит от типа данных и характера проблемы.
Для числовых данных обычно используются следующие методы:
- Удаление: удаление строк с отсутствующими значениями. Среднее/медиана: замените отсутствующие значения средним или медианным значением непропущенных значений.
- Среднее значение чувствительно к выбросам, а медиана — нет, может быть более подходящим использовать медиану.
- Случайный: замените отсутствующие значения случайным значением из доступных данных.
- K-ближайшие соседи (KNN): вменение пропущенных значений с использованием алгоритма KNN, который заполняет пропущенные значения на основе аналогичных наблюдений «соседей».
Для категориальных данных обычно используются следующие методы:
- Удаление: удаление строк с отсутствующими значениями.
- Режим: замените отсутствующие значения режимом (наиболее часто встречающееся значение).
- Случайный: То же, что и для числовых данных.
- KNN: также может использоваться для категориальных данных, где наиболее распространенный класс среди K-ближайших соседей заменяет отсутствующее значение. Выбор правильного метода зависит от конкретных данных, важности функции и доли пропущенных значений.
Существует больше методов обработки пропущенных значений, и они важны в зависимости от проблемы, с которой вы можете экспериментировать, используя разные подходы.
В приведенном ниже коде мы идентифицируем наши числовые столбцы и категориальные столбцы, а также обрабатываем пропущенные значения и делим наш набор данных на наборы для обучения/тестирования/проверки.
numerical_columns = train_df.select_dtypes(include=np.number).columns # get numerical columns categorical_columns = train_df.select_dtypes('object').columns # gettrain_df[categorical_columns].nunique()def handle_missing(table, columns = None, method = 'drop'): table = table.copy() if columns == None: columns = table.columns for col in columns: if method == 'drop': table[col].dropna(inplace=True) elif method == 'mode': table[col].fillna(table[col].mode()[0], inplace = True) elif method == 'median': table[col].fillna(table[col].median(), inplace = True) elif method == 'mean': table[col].fillna(table[col].mean(), inplace = True) elif method == 'random': table[col] = table[col].apply(lambda x: np.random.choice(table[col].dropna().values) if np.isnan(x) else x) return tabletrain_df = handle_missing(train_df, columns=numerical_columns, method='mean') test_df = handle_missing(test_df, columns=numerical_columns, method='mean') val_df = handle_missing(val_df, columns=numerical_columns, method='mean') y_train = train_df['RainTomorrow'] y_test = test_df['RainTomorrow'] y_val = val_df['RainTomorrow'] train_df = train_df.drop(['RainTomorrow'],axis=1) test_df = test_df.drop(['RainTomorrow'],axis=1) val_df = val_df.drop(['RainTomorrow'],axis=1)train_df.isnull().sum()
Масштабирование числовых функций
Масштабирование числовых признаков до определенного диапазона (например, от 0 до 1 или от -1 до 1) является хорошей практикой в машинном обучении. Это помогает гарантировать, что все функции вносят равный вклад в прогноз модели, предотвращая доминирование какой-либо отдельной функции из-за ее большего масштаба. Кроме того, это делает алгоритмы оптимизации более эффективными, поскольку они обычно лучше работают с меньшими числами.
Например:
Рассмотрим две точки данных:
Человек А: возраст = 25 лет, доход = 50 000 долларов США.
Человек B: возраст = 50 лет, доход = 100 000 долларов США.
Без масштабирования функция дохода перевешивала бы функцию возраста из-за ее больших значений, что влияло бы на обучение нашей модели.
Применяя мин-макс масштабирование, мы корректируем значения:
Человек A: масштабированный возраст = 0, масштабированный доход = 0
Человек B: масштабированный возраст = 1, масштабированный доход = 1
Теперь обе функции имеют одинаковый диапазон, что позволяет модели учиться на обеих без предвзятости.
Масштабирование числовых признаков с помощью библиотеки sk-learn.
from sklearn.preprocessing import MinMaxScalertrain_df.describe()scaler = MinMaxScaler() scaler.fit(data[numerical_columns])train_df[numerical_columns] = scaler.transform(train_df[numerical_columns]) val_df[numerical_columns] = scaler.transform(val_df[numerical_columns]) test_df[numerical_columns] = scaler.transform(test_df[numerical_columns])val_df[numerical_columns].describe()
Кодирование категориальных данных
Прежде чем мы сможем применить алгоритмы машинного обучения к категориальным переменным, нам нужно преобразовать их в числовую форму. Этот процесс известен как кодирование.
Например, возьмем столбец «Передача», который содержит «Ручной» и «Автоматический». Учитывая, что категорий всего две, мы можем использовать двоичное кодирование: присвоить «0» «Ручному» и «1» «Автоматическому» или наоборот.
В случае «Fuel_Type» с тремя категориями мы можем применить One-Hot-Encoding. Здесь каждая категория получает свой столбец в данных, и эти новые столбцы являются двоичными, указывая на наличие (1) или отсутствие (0) этой категории для данной записи.
One-Hot-Encoding особенно полезен, когда категории не имеют естественного порядка или иерархии, как в случае с «Fuel_Type». Это предотвращает присвоение алгоритмом машинного обучения ненадлежащего веса или важности категориям на основе числового значения.
Однако следует быть осторожным при использовании One-Hot-Encoding с переменной, которая имеет много категорий. Это связано с тем, что это может привести к значительному увеличению количества столбцов (размерности) в вашем наборе данных, что сделает его разреженным и потенциально трудным для работы — ситуацию, которую часто называют «проклятием размерности». В таких ситуациях могут оказаться более подходящими другие методы кодирования, такие как порядковое кодирование или целевое кодирование.
Пример One Hot Encoding:

Одна реализация горячего кодирования с использованием библиотеки sk-learn.
from sklearn.preprocessing import OneHotEncoder## Remove RainTommorrow from categorical since we're gonna use it to create our data frames etc. categorical_columns = categorical_columns.drop('RainTomorrow')encoder = OneHotEncoder(sparse=False, handle_unknown = 'ignore') encoder.fit(data[categorical_columns])encoded_columns = list(encoder.get_feature_names_out(categorical_columns))print(encoded_columns)train_df[encoded_columns] = encoder.transform(train_df[categorical_columns].fillna('Unknown')) val_df[encoded_columns] = encoder.transform(val_df[categorical_columns].fillna('Unknown')) test_df[encoded_columns] = encoder.transform(test_df[categorical_columns].fillna('Unknown'))train_df = train_df.drop(categorical_columns, axis=1)test_df = test_df.drop(categorical_columns, axis=1) val_df = val_df.drop(categorical_columns, axis=1)train_df = train_df.drop(['Date', 'Year'], axis=1) val_df = val_df.drop(['Date', 'Year'], axis=1) test_df = test_df.drop(['Date', 'Year'], axis=1)
Логистическая регрессия
Логистическая регрессия — это алгоритм обучения классификации. Объяснение будет в случае бинарной классификации. Однако ее можно расширить до многоклассовой классификации. В логистической регрессии, аналогично линейной регрессии, мы по-прежнему хотим смоделировать наш результат yi (i-й пример в нашем наборе данных) как линейную функцию xi (yi = w * xi + b), но это приведет к функции, которая может имеют значения от минус бесконечности до плюс бесконечности (продолжается диапазон значений, как и в линейной регрессии). Но в нашей задаче значения yi могут быть только «да» или «нет» (помните, что RainTomorrow может быть «да» или «нет»).
В качестве решения этой проблемы мы могли бы закодировать положительные метки как 1, а отрицательные метки как 0 (в нашем случае это будет «Да» = 1, «Нет» = 0), и тогда нам просто нужно найти простое непрерывное функция, домен которой равен (0, 1). В таком случае, если значение, возвращаемое моделью для ввода x, ближе к 0, то мы присваиваем x отрицательную метку; в противном случае пример помечен как положительный. Одной из функций, обладающих таким свойством, является стандартная логистическая функция (также известная как сигмовидная функция):
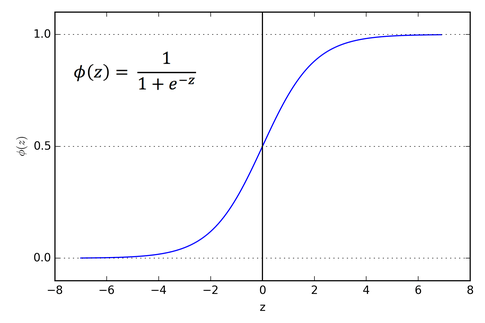
Итак, теперь вместо z мы просто заменяем его нашей известной линейной комбинацией функций (x * w + b), какое бы значение это ни возвращало, оно будет в диапазоне 0,1, а затем мы можем установить например, для значений больше 0,5 мы классифицируем их как Да, а для значений меньше 0,5 мы классифицируем их как Нет.

Итак, мы берем линейную комбинацию наших входных признаков с их соответствующими весами, затем применяем сигмовидную функцию, чтобы получить число от 0 до 1. Это число представляет вероятность ввода; классифицируется как «Да»
Функция ошибок, которая оценивает наши результаты, называется потерями перекрестной энтропии:

Минимизация кросс-энтропийных потерь приводит к наилучшей модели, т. е. той, которая предсказывает наибольшую вероятность для правильного класса.
С точки зрения весов и смещений наша цель состоит в том, чтобы найти значения этих параметров, которые минимизируют функцию кросс-энтропийных потерь. Обычно это достигается с помощью итеративного процесса, такого как градиентный спуск, когда мы начинаем со случайных значений весов и смещений, а затем итеративно корректируем эти значения в направлении, которое больше всего уменьшает кросс-энтропийные потери.
Вкратце процедура будет выглядеть так:
- Инициализируйте веса и смещения: начните со случайных значений весов и смещений. Это начальные «догадки» о наилучших значениях этих параметров.
- Вычислите потери: используйте текущие веса и смещения, чтобы делать прогнозы на обучающих данных, а затем вычисляйте потери перекрестной энтропии. Это говорит нам о том, насколько хорошо (или плохо) работают текущие веса и смещения.
- Вычислите градиенты: вычислите градиенты функции потерь относительно весов и смещений. Градиент — это многомерная производная, которая сообщает нам наклон функции потерь во всех направлениях. Он указывает в сторону самого крутого подъема.
- Обновите веса и смещения: вычтите небольшой кратный градиент из текущих весов и смещений. Это «шаги» в направлении наискорейшего спуска, то есть в направлении, которое больше всего уменьшает потери.
- Повтор: повторите шаги 2–4 много раз. До тех пор, пока убыток не уменьшится до нашего удовлетворенного уровня или пока не будет значительного снижения.
Важно понимать, как работает градиентный спуск, знать, как вычисляются эти градиенты и как обновляются веса. Для получения дополнительной информации посмотрите это видео: здесь.
Обучение модели с помощью LogisticRegression и интерпретация с использованием библиотеки sklearn
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression(solver='liblinear', random_state=42)
Параметр max_iteration метода подгонки по умолчанию равен 100, это означает, что он будет запускаться 100 раз и делать прогнозы, вычислять ошибки, изменять веса и смещения.
model.fit(train_df, y_train)Мы можем проверить веса, присвоенные каждой функции
print(train_df.columns)
print(model.coef_.tolist())Мы могли видеть, что max temp имеет отрицательный вес, это может означать, что он не сильно влияет на нашу целевую переменную. Осадки имеют положительное значение, температура имеет положительное значение и т. д. Модель изучила веса, если солнечный свет имеет сильно отрицательное значение.
Чем выше вес, тем сильнее коррелирует функция с нашей целью. Давайте построим график важности функции, отсортировав и отобразив соответствующий вес каждой функции.
weight_df = pd.DataFrame({
'feature': train_df.columns,
'weight': model.coef_to listt()[0]
})
weight_df
sns.barplot(data=weight_df.sort_values('weight', ascending=False).head(10), x='weight', y='feature')
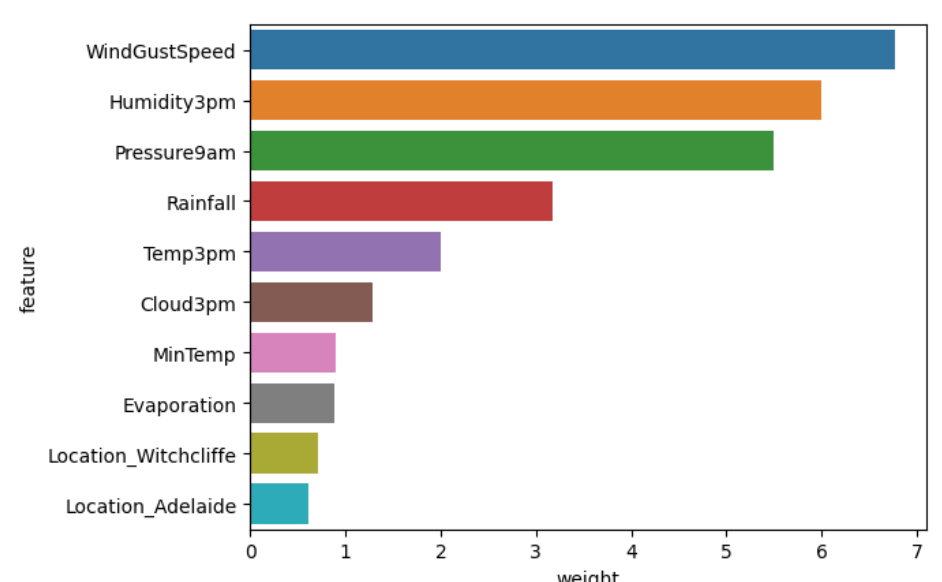
Как видно из графика выше, наиболее важными функциями с более высокими весами, которые влияют на нашу целевую переменную, являются WindGustSpeed, Humidity3pm, …
Делайте прогнозы на основе наших данных о поездах, используя приведенный ниже код:
train_predictions = model.predict(train_df) train_predictionsy_train
Оценка нашей модели
Подсчитайте количество совпадений между прогнозами и фактическими значениями, разделите на количество прогнозов (дней) | Всего строк
from sklearn. metrics import accuracy_score
accuracy_score(y_train, train_predictions)Это точность нашей модели на тренировочных данных составляет 85%. Мы также могли бы вернуть вероятности, для каждого прогноза у нас будут вероятности.
model.classes_ # outputsarray(['No', 'Yes'], dtype=object)train_probabilities = model.predict_proba(train_df)from sklearn.metrics import confusion_matrix
train_probabilities возвращает список вероятностей, для каждой точки данных поезда его прогноз «Да» с определенной вероятностью и «НЕТ» с 1-вероятностью ДА.
Лучшей метрикой для оценки эффективности нашей модели является матрица путаницы.
Четыре члена в матрице:
Истинные положительные результаты (TP): это случаи, когда модель предсказывала «Да», и фактический класс также был «Да».
Истинно отрицательные значения (TN): это случаи, когда модель предсказывала «Нет», и фактический класс также был «Нет».
Ложные срабатывания (FP): это случаи, когда модель предсказывала «Да», но фактический класс был «Нет». Это также известно как «ошибка типа I».
Ложноотрицательные результаты (FN): это случаи, когда модель предсказала «Нет», но фактический класс был «Да». Это также известно как «ошибка типа II».

confusion_matrix(y_train, train_predictions, normalize='true')
# OUTPUTS
array([[0.94614779, 0.05385221],
[0.47729149, 0.52270851]])Матрица путаницы дает нам общее представление о том, насколько хорошо наша модель предсказывает, будет ли завтра дождь или нет.
Давайте разберемся, что означают значения в матрице. Верхнее левое значение (0,9461) — это доля истинно отрицательных результатов. Это означает, что модель правильно предсказала 94,61% случаев, когда на следующий день НЕ будет дождя. Таким образом, он очень хорошо сообщает нам, когда будет сухой день.
Однако нижнее правое значение (0,5227), представляющее истинное положительное значение, показывает, что модель правильно предсказала, что на следующий день будет идти дождь примерно в 52,27% случаев. Таким образом, это не так точно, когда дело доходит до прогнозирования дождливых дней (что прискорбно, потому что это то, чего мы пытаемся достичь с помощью этой модели).
Верхнее правое значение (0,0538), уровень ложных срабатываний, говорит нам о том, что модель неверно предсказала, что на следующий день будет дождь примерно в 5,38% случаев, когда день был сухой.
Нижнее левое значение (0,4772), доля ложноотрицательных результатов, указывает на то, что модель неверно предсказала отсутствие дождя на следующий день примерно в 47,72% случаев, когда дождь закончился.
В зависимости от ситуации нас могут больше беспокоить ложные срабатывания (предсказание дождя в сухую погоду) или ложноотрицательные результаты (предсказание сухости во время дождя). Это области, над которыми нам нужно поработать, чтобы улучшить производительность нашей модели.
Если мы пытаемся проверить, хотим ли мы провести завтра игру в теннис, но несколько ложноотрицательных результатов высоки, то наша модель работает плохо, поскольку она, скорее всего, не будет хорошо предсказывать, что завтра будет дождь. Потому что модель предсказывает, что дождя НЕ будет. поэтому вы пытаетесь уменьшить ложноотрицательные результаты, даже если это снижает точность.
Если бы мы пытались порекомендовать химиотерапию при раке молочной железы, то мы смотрим на ложноположительные результаты, потому что мы предсказывали, что у человека рак, но это не так. Это был Ложный Положительный результат. Поэтому в зависимости от проблемы мы оптимизируем эти значения.
Эта модель, основанная на матрице путаницы, не так уж хороша, поскольку она имеет только 47% точности в предсказании завтрашнего дождя, она близка к случайному предположению.
Причина того, что TN составляет всего 0,5, а TP — 0,94, в основном связана с тем, что набор данных несбалансирован, и это следует исправить, чтобы получить лучшие результаты. Эта модель ориентирована на прогнозирование того, что завтра дождя НЕ будет, и она до сих пор мало что знает о прогнозировании дождя.
Подобно прогнозам для набора поездов, вы можете использовать тестовый набор данных, чтобы делать прогнозы по невидимым наборам данных для нашей модели, что может быть полезно при прогнозировании, будет ли завтра дождь.
test_predictions = model.predict(test_df)
accuracy_score(y_test, test_predictions)
# Accuracy score on test data is 0.841Следующие шаги
- Обработка дисбаланса классов, поскольку мы видим, что алгоритм сильно смещен в сторону класса большинства «Дождя завтра не будет».
- применять такие методы, как недостаточная или избыточная выборка, SMOTE, веса класса настройки или другие методы (поэкспериментируйте с этим, всегда проверяя результаты).
- Мы могли бы больше поэкспериментировать с логистической регрессией, изменить порог 0,5 (граница решения) и получить тот, который лучше всего соответствует характеру проблемы.
- Используйте проверочный набор для настройки гиперпараметров
- Поэкспериментировав с параметрами и обработав дисбалансы классов, попробуйте ввести в модель один вход и проверьте вероятность того, что завтра будет дождь или нет.
- Используйте другие алгоритмы классификации, такие как Random Forests или XGBOOST.
Случайный лесной классификатор
Бэгинг
Бэггинг, также известный как агрегация начальной загрузки, — это стратегия, используемая для повышения надежности наших прогнозов. Он работает, уменьшая дисперсию наших прогнозов.
Чтобы понять бэггинг, полезно знать два термина: «дисперсия» и «независимый и одинаково распределенный (i.i.d.)».
Дисперсия — это мера того, насколько значения в наборе данных отличаются от среднего значения. Проще говоря, это способ понять, насколько разбросаны данные. Например, если мы прогнозируем цену дома на основе определенных характеристик, дисперсия будет заключаться в том, насколько прогнозируемые цены отличаются от средней прогнозируемой цены. Высокая дисперсия может означать, что наша модель очень хорошо работает с некоторыми данными, но очень плохо с другими данными, что не является идеальным.
Теперь «независимый и одинаково распределенный» или «i.i.d.» — это термин, используемый для описания сценария, в котором все элементы в последовательности имеют одинаковое распределение вероятностей, и каждый элемент в последовательности не зависит от других элементов. Другими словами, это как брать карты из колоды, каждый раз заменяя карту — каждое взятие не влияет на другие и имеет одинаковые шансы.
Итак, бэггинг усредняет прогнозы нескольких моделей, каждая из которых обучена на разных наборах i.i.d. образцы (наборы данных). Этот процесс усреднения уменьшает дисперсию, что означает, что наши прогнозы становятся более надежными и менее разбросанными. Проще говоря, используя бэггинг, мы собираем мнения из нескольких моделей, а не полагаемся на одну, и это приводит к более стабильному и точному окончательному прогнозу.
Деревья решений
Прежде чем использовать алгоритм случайного леса, важно иметь представление о модели дерева решений.

Учитывая приведенную выше таблицу, мы хотели бы решить, играть нам в гольф или нет. Мы можем обучить дерево решений, которое строит дерево с учетом набора данных и создает эту иерархическую структуру, в которой в каждом узле у нас есть решение, которое нужно принять (это дерево создается с помощью компьютера, вместо того, чтобы вручную определять лучшие решения). которые ведут нас к ответу на нашу проблему).
Другим более конкретным примером может быть это дерево, которое было обучено с помощью класса sk-learn DecisionTreeClassifier.

Мы можем видеть значение Джини в каждом поле, это функция потерь, используемая деревом решений, чтобы решить, какой столбец следует использовать для разделения данных и по какому значению они должны быть разделены. Чем ниже значение Джини, тем лучше разделение в том смысле, что точность предсказания этого класса в этом узле выше. Идеальное разделение (указывающее, что все данные, принадлежащие к одному и тому же классу, были собраны в этом узле) имеет индекс Джини, равный 0.
В Дереве решений на каждом шаге создаются подмножества данных, которые разделяются на создаваемые друг другом узлы. Дерево можно разделить до тех пор, пока все точки данных в каждом узле не будут принадлежать одному и тому же классу, что указывает на идеальную классификацию, что также приводит к переоснащению.
Случайные леса
Деревья решений, как правило, превосходят обучающие данные. Это означает, что они могут настолько хорошо предсказывать примеры, которые видели, что плохо работают с новыми, невидимыми данными. Они также могут быть чувствительны к небольшим изменениям в данных, что приводит к совершенно другим деревьям.
Random Forest помогает решить эти проблемы. Он создает целый лес различных деревьев решений, каждое из которых обучено на своем наборе выборок из данных (это часть «упаковки»), и каждое дерево получает только подмножество функций для принятия решений (это « случайная часть). Таким образом, Random Forest гарантирует, что деревья разнообразны и не коррелируют друг с другом.
Когда необходимо сделать новый прогноз, Random Forest принимает входные данные, заставляет каждое из деревьев решений в лесу сделать прогноз, а затем принимает большинство голосов прогнозов в качестве окончательного решения. Таким образом, модель использует мудрость толпы, делая общие прогнозы более надежными и менее подверженными переоснащению любого отдельного дерева.
from sklearn.ensemble import RandomForestClassifierИспользуя тот же обучающий/тестовый набор, я создал базовую модель с параметрами RandomForsetClassifier по умолчанию. Мы будем использовать эту модель для первоначальных прогнозов, а затем улучшим ее с помощью таких методов, как GridSearchCv, чтобы найти наилучшие возможные параметры, дающие наилучшие результаты.
model = RandomForestClassifier(n_jobs=-1, random_state=42)
model.fit(train_df, y_train)
print("Accuracy on train set")
print(model.score(train_df, y_train))
print("Accuracy on validation set")
print(model.score(val_df, y_val))
## OUTPUTS
Accuracy on train set
0.9999795893374699
Accuracy of the validation set
0.8562233015390017Глядя на показатели точности, мы можем наблюдать большую разницу между наборами для обучения и проверки. Модель практически идеальна на тренировочном наборе с точностью 99,99%, но на проверочном наборе точность падает до 85,62%. Это указывает на то, что наша модель переоснащается — она очень хорошо изучила обучающие данные, может быть, слишком хорошо, до такой степени, что изо всех сил пытается обобщить новые, невидимые данные в наборе проверки.
Переобучение происходит, когда модель изучает конкретные детали и шум в наших обучающих данных до такой степени, что это негативно влияет на способность нашей модели работать с новыми данными. В этом случае он, по сути, «запомнил» тренировочный набор и, следовательно, работает значительно хуже с данными, которые он раньше не видел.
В этом часто могут помочь методы ансамбля, которые объединяют прогнозы из нескольких моделей. Они работают по принципу, согласно которому отдельные ошибки каждой модели имеют тенденцию компенсировать друг друга при усреднении, что приводит к более надежному и точному окончательному прогнозу. Это похоже на то, как спросить мнение многих людей — они могут не все согласиться, но коллективно они часто могут прийти к лучшему решению. В случае деревьев решений потребовалось бы много деревьев, предсказывающих неточно, чтобы в итоге получить окончательный неверный прогноз.
Получить важность функции
importance_df = pd.DataFrame({
'feature': train_df.columns,
'importances': model.feature_importances_
}).sort_values('importances', ascending=False)
plt.title("Feature importances")
sns.barplot(data=importance_df.head(10), x='importances', y='feature')
Настройка гиперпараметров с помощью Random Forest
GridSearchCV и RandomizedSearchCV — это два метода, которые можно использовать в sklearn для настройки гиперпараметров. Они используются для поиска оптимальных гиперпараметров модели, которые дают наиболее «точные» прогнозы.
GridSearchCV: этот метод выполняет исчерпывающий поиск по указанным значениям параметров для средства оценки. Он обучает модель для каждой комбинации гиперпараметров и сохраняет наилучшую комбинацию. Например, если вы укажете значения max_depth как [1, 2, 3] и n_estimators как [50, 100, 200], то GridSearchCV попробует все комбинации [(1, 50), (1, 100), (1, 200), (2, 50), (2, 100), (2, 200), (3, 50), (3, 100), (3, 200)] и вернуть набор параметров с наилучшей метрикой производительности . Недостатком является то, что это может занять очень много времени для больших наборов данных и/или для слишком большого количества указанных параметров.
RandomizedSearchCV: этот метод представляет собой случайный поиск по гиперпараметрам. RandomizedSearchCV реализует рандомизированный поиск по параметрам, где каждый параметр выбирается из распределения по возможным значениям параметров. При наличии достаточного количества времени RandomizedSearchCV найдет такие же или лучшие параметры, как GridSearchCV. Обычно это быстрее и приводит к тем же результатам, что и GridSearchCV.
Создайте базовую модель, которую мы сравним с нашей потенциально улучшенной моделью случайного леса после настройки гиперпараметров.
base_model = RandomForestClassifier(n_jobs=-1, random_state=42, class_weight={"No":1, "Yes":2})
base_model.fit(train_df, y_train)
print("Accuracy on train set")
print(model.score(train_df, y_train))
print("Accuracy on validation set")
print(model.score(val_df, y_val))
## BASE MODEL EVALUTAION
Accuracy on train set
0.9999795893374699
Accuracy of the validation set
0.8562233015390017Некоторые важные параметры, используемые при использовании классификатора случайного леса
n_estimators — мы можем изменить количество оценок (деревьев решений), чем больше деревьев решений, тем больше случайности в нашем решении, что может уменьшить переобучение. Значение по умолчанию — 100, попробуйте 200, 400, 800… и попутно проверьте, становится ли точность лучше (намного лучше), если она не сильно меняется, просто используйте меньше n оценок, чтобы стоимость обучения не стала слишком высокой. .
Хорошей практикой является построение графика этого изменения точности и выбор наилучшего значения. В огромных наборах данных вы должны быть осторожны при увеличении количества оценок, поскольку это требует больших вычислительных ресурсов, если это не так, вы можете просто выполнить поиск по сетке и найти лучший. Увеличение n_estimators не приведет к переоснащению модели.
- критерий: это функция, используемая для измерения качества разбиения дерева решений. Другими словами, он используется, чтобы решить, какую функцию использовать для разделения данных на каждом этапе построения деревьев.
- Джини: Относится к примеси Джини, мере неправильной классификации, целью которой является максимизация вероятности правильной классификации.
- энтропия: Относится к приросту информации, который измеряет снижение энтропии (случайности), достигнутое из-за разделения.
- max_depth — это максимальная глубина дерева. Это полезно для контроля переобучения.
- max_leaf_nodes — это максимальное количество конечных узлов, которые может иметь дерево. Это полезно для контроля переобучения.
- class_weight — мы можем использовать это, чтобы придать больший вес классу меньшинства. Это полезно, когда у нас намного больше данных для одного класса, чем для другого, как в нашем случае. вы также можете использовать class_weight как сбалансированный, что автоматически придаст больший вес классу меньшинства.
Реализация классификатора случайного леса с использованием GridSearchCV для поиска лучших параметров.
from sklearn.model_selection import GridSearchCV criterion = ['gini', 'entropy'] n_estimators = [100, 200, 300] max_features = ['auto', 'sqrt'] max_depth = [10, 20] max_depth.append(None) params = {'criterion': criterion, 'n_estimators': n_estimators, 'max_features': max_features, 'max_depth': max_depth} gs = GridSearchCV(base_model, param_grid=params, n_jobs=-1) gs.fit(val_df, y_val)gs.best_params_model = RandomForestClassifier(n_jobs=-1, random_state=42, class_weight={"No":1, "Yes":2}, criterion='entropy', max_depth=10, max_features='auto', n_estimators=300) model.fit(train_df, y_train) predictions = model.predict(test_df) print("Accuracy on test set") print(accuracy_score(y_test, predictions))# Calculate confusion matrix cm = confusion_matrix(y_test, predictions, normalize='true') print(cm)## OUTPUTS Accuracy on the test set 0.831660832360949 [[0.9067136 0.0932864 ] [0.42454936 0.57545064]]
Выводы и следующие шаги
Модель случайного леса работает лучше, чем наша логистическая регрессия, в ней меньше ложных отрицательных значений, что хорошо для этой конкретной проблемы по причинам, упомянутым ранее.
Следующие шаги:
- Используйте лучшие методы исправления дисбаланса классов, такие как SMOTE, для дальнейшего улучшения нашей модели.
- Попробуйте разные модели классификации, такие как SVM, xgboost и т. д.
- В зависимости от важности функции, возможно, удалите некоторые функции и проверьте, улучшается ли точность модели.
Заключительные примечания
Чтобы получить более глубокое понимание темы, важно дополнительно изучить все темы, представленные в этом документе.
Несколько полезных книг по машинному обучению и глубокому обучению:
- Глубокое обучение — Ян Гудфеллоу Йошуа Бенджио Аарон Курвиль
- Кристофер М. Бишоп — Распознавание образов и машинное обучение
- Чару С. Аггарвал — Учебник по интеллектуальному анализу данных